Автор: Денис Аветисян
Новое исследование показывает, что даже небольшие языковые модели способны выполнять сложные задачи, требующие многошаговых рассуждений, при правильном подходе к обучению.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал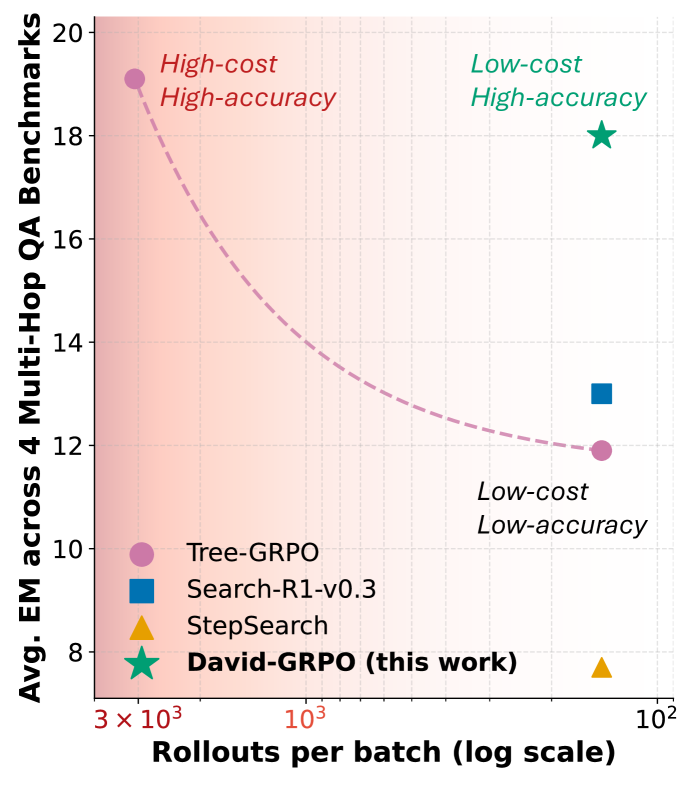
Представлен алгоритм David-GRPO, позволяющий небольшим языковым моделям эффективно решать задачи многошагового рассуждения за счет обучения с подкреплением и использования внешних источников информации.
Несмотря на успехи обучения с подкреплением в создании агентов, способных к многошаговому рассуждению с использованием поиска и инструментов, эти достижения часто зависят от значительных вычислительных ресурсов. В работе «Can David Beat Goliath? On Multi-Hop Reasoning with Resource-Constrained Agents» предложен фреймворк DAVID-GRPO, демонстрирующий, что небольшие языковые модели способны эффективно выполнять многошаговое рассуждение даже при ограниченных ресурсах. Ключевым является повышение эффективности исследования и обоснование рассуждений на основе извлеченной информации, что позволяет достичь высокой точности при низких затратах на обучение. Возможно ли создание еще более компактных и эффективных агентов, способных к сложному рассуждению в условиях реальных ограничений?
Временные Закономерности: Сложность Многошагового Рассуждения
Несмотря на значительный прогресс в разработке языковых моделей, многошаговое рассуждение продолжает оставаться серьезной проблемой на пути к достижению производительности, сопоставимой с человеческой. Современные модели часто демонстрируют впечатляющие результаты в простых задачах, однако при решении вопросов, требующих последовательного применения нескольких логических шагов и объединения информации из разных источников, их эффективность резко снижается. Это связано с тем, что количество возможных путей рассуждений экспоненциально возрастает с увеличением длины цепочки, что создает вычислительные трудности и повышает вероятность ошибок. В результате, модели испытывают затруднения в понимании контекста, выявлении релевантной информации и формулировании корректных выводов, особенно в ситуациях, требующих абстрактного мышления и здравого смысла. Таким образом, преодоление этих ограничений является ключевой задачей для создания действительно интеллектуальных систем.
Традиционные подходы к многоступенчатым рассуждениям сталкиваются с проблемой комбинаторного взрыва, когда количество возможных путей решения задачи экспоненциально возрастает с каждым новым шагом. Представьте, что для ответа на простой вопрос требуется последовательно проверить множество фактов и связей: каждый новый факт усложняет поиск, увеличивая число вариантов в геометрической прогрессии. Эта сложность быстро становится непреодолимой для классических алгоритмов, поскольку ресурсы, необходимые для перебора всех комбинаций, растут слишком быстро. В результате, даже относительно простые задачи, требующие нескольких логических выводов, могут оказаться недоступными для решения без применения более эффективных методов, способных обходить или сокращать пространство поиска.
Существующие оценочные наборы данных, предназначенные для проверки способностей к многошаговому рассуждению, зачастую не отражают реальную сложность этой когнитивной функции. Многие из них страдают от предвзятостей, позволяющих моделям находить поверхностные корреляции вместо истинного логического вывода. Более того, типичные наборы данных могут содержать слишком простые задачи или обладать ограниченной вариативностью, что не позволяет адекватно оценить способность системы к обобщению и решению новых, сложных проблем. Таким образом, результаты, полученные на этих наборах, могут быть завышенными и не отражать истинный уровень развития искусственного интеллекта в области рассуждений, что затрудняет прогресс в создании действительно интеллектуальных систем.
Успешное освоение многошагового рассуждения имеет решающее значение для широкого спектра прикладных задач. В частности, это открывает новые возможности в области интеллектуальных систем ответа на вопросы, где требуется не просто извлечение информации, а её синтез из нескольких источников. Кроме того, развитие данного направления стимулирует прогресс в автоматизированном открытии знаний, позволяя системам самостоятельно выявлять связи и закономерности в больших объемах данных. В конечном итоге, способность к многошаговому рассуждению является ключевым элементом для создания систем, способных решать сложные проблемы, требующие последовательного анализа, планирования и принятия решений, что существенно расширяет горизонты применения искусственного интеллекта в различных областях науки и техники.
![Эксперименты на MuSiQue с использованием Qwen2.5-1.5B показали, что увеличение количества шагов рассуждений повышает точность ([latex]EM[/latex]) при одновременном увеличении числа уникальных поисковых действий, при этом минимальное необходимое количество поисков для каждого подмножества шагов обозначено пунктирными линиями, а модель Search-R1-v0.3 обучалась с использованием награды за поиск.](https://arxiv.org/html/2601.21699v1/x8.png)
David-GRPO: Обучение с Подкреплением для Эффективного Рассуждения
David-GRPO представляет собой фреймворк обучения с подкреплением, разработанный для эффективного многошагового рассуждения в условиях ограниченных ресурсов. В отличие от традиционных подходов, требующих значительных вычислительных мощностей и объемов данных, David-GRPO оптимизирован для работы в средах с ограниченным бюджетом, что делает его применимым к широкому спектру задач, где ресурсы ограничены. Основная цель фреймворка — повышение эффективности обучения и снижение затрат на исследование пространства состояний при решении сложных задач, требующих последовательного применения логических выводов и поиска доказательств.
В основе David-GRPO лежит стратегия «warm-start», использующая небольшое количество примеров для быстрой инициализации агента. Этот подход позволяет существенно сократить время обучения и повысить эффективность использования данных (sample efficiency) за счет предварительной настройки агента на ограниченном наборе данных. Вместо обучения с нуля, агент начинает с уже сформированных начальных знаний, что ускоряет процесс схождения к оптимальной политике и снижает потребность в больших объемах данных для достижения требуемой производительности. Использование few-shot learning позволяет David-GRPO эффективно адаптироваться к новым задачам, требующим многошагового рассуждения, даже в условиях ограниченных вычислительных ресурсов.
В основе David-GRPO лежит механизм вознаграждения, основанный на извлечении релевантной информации из достоверных источников. Этот сигнал вознаграждения направляет процесс исследования агента, отдавая приоритет траекториям, которые соответствуют подтвержденным фактам. Применение этого подхода обеспечивает не только релевантность генерируемых рассуждений, но и их когерентность, поскольку агент стимулируется к выбору путей, подтверждаемых внешними данными. Сигнал вознаграждения формируется на основе соответствия между шагами рассуждений и извлеченными доказательствами, что позволяет агенту эффективно ориентироваться в пространстве возможных решений и избегать отклонений от достоверной информации.
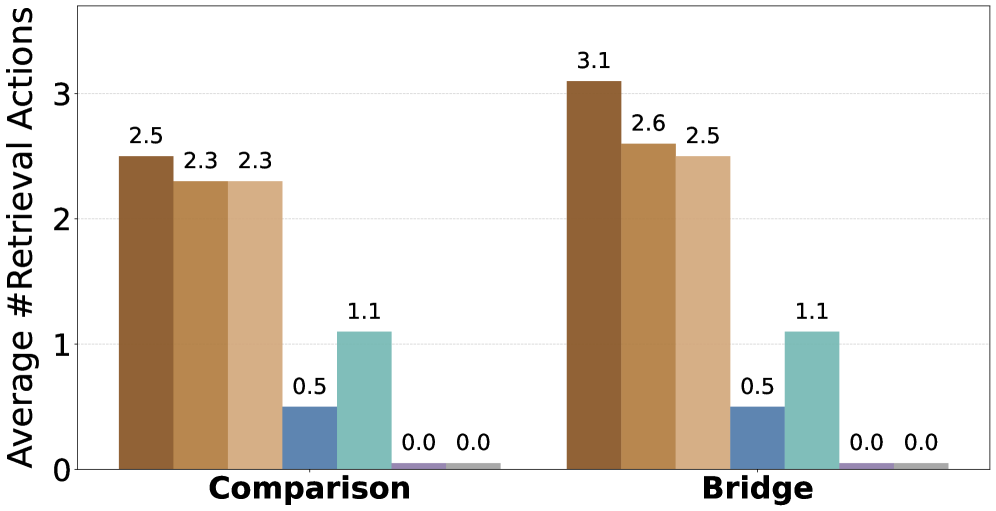
Динамическое расширение траекторий (Grounded Expansion) в David-GRPO представляет собой механизм уточнения существующих последовательностей действий агента. Этот процесс заключается в итеративном добавлении к текущей траектории новых шагов, основанных на релевантных документах, полученных из внешнего источника знаний. Каждый новый шаг оценивается с использованием сигнала вознаграждения, привязанного к этим документам, что позволяет агенту корректировать свою стратегию и находить более оптимальные пути рассуждений. Использование динамического расширения позволяет эффективно исследовать пространство действий, избегая зацикливания и фокусируясь на наиболее перспективных траекториях, что приводит к улучшению способности агента к многошаговому рассуждению в условиях ограниченных ресурсов.
Экспериментальное Подтверждение: Малые Модели, Большие Результаты
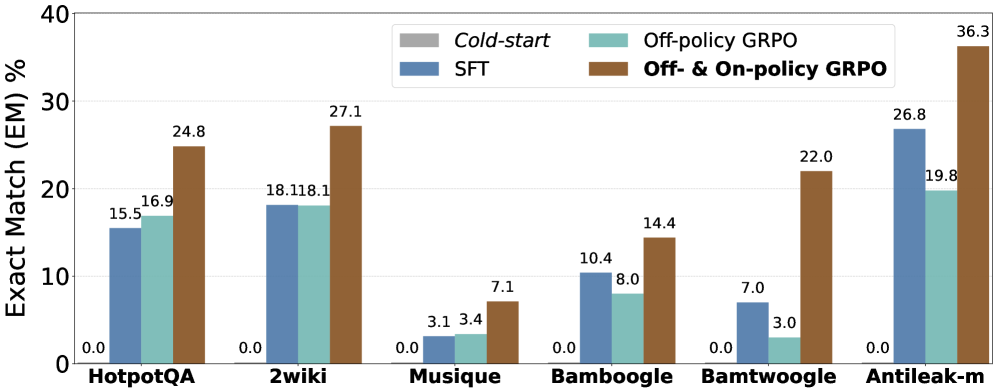
Экспериментальные данные подтверждают эффективность David-GRPO при использовании с небольшими языковыми моделями, такими как Qwen2.5 и Llama-3.2-1B. В ходе тестов было показано, что данная комбинация позволяет достигать значимых результатов в задачах, требующих многоступенчатого логического вывода, несмотря на ограниченное количество параметров используемых моделей. Это демонстрирует, что David-GRPO способен эффективно использовать потенциал небольших языковых моделей для решения сложных задач, что особенно важно в условиях ограниченных вычислительных ресурсов и необходимости быстрой обработки данных.
В ходе экспериментов, фреймворк David-GRPO продемонстрировал конкурентоспособные результаты на сложных бенчмарках, требующих многошагового рассуждения для ответов на вопросы. В частности, достигнута высокая производительность на наборах данных Bamboogle, BamTwoogle и AntiLeakBench-Multi-hop, которые характеризуются необходимостью синтеза информации из нескольких источников для получения корректного ответа. Эти бенчмарки специально разработаны для оценки способности моделей к сложному логическому выводу и поиску релевантной информации, что подтверждает эффективность предложенного подхода в задачах, требующих продвинутых навыков рассуждения.
Экспериментальные данные демонстрируют, что David-GRPO достигает сопоставимой или превосходящей производительности по сравнению с базовыми моделями, требующими значительных вычислительных ресурсов, при этом используя лишь 4.7% от количества обучающих эпизодов (rollouts), необходимых этим базовым моделям. Данный факт свидетельствует о высокой эффективности алгоритма David-GRPO в плане использования вычислительных ресурсов и времени обучения, что позволяет достигать конкурентоспособных результатов при значительно меньших затратах.
В ходе экспериментов на бенчмарке AntiLeakBench-Multi-hop, фреймворк David-GRPO продемонстрировал превосходство над моделью Search-R1-v0.3, достигнув прироста показателя EM Score до 19.6 процентных пунктов. Это указывает на значительное улучшение точности извлечения ответов на вопросы, требующие многошагового рассуждения и поиска информации в различных источниках, по сравнению с базовой моделью Search-R1-v0.3.
В ходе экспериментов David-GRPO продемонстрировал превосходство над Tree-GRPO на трех различных мульти-хоповых бенчмарках: 2WikiMultiHopQA, MuSiQue и Bamboogle. На этих задачах David-GRPO показал более высокие результаты, что свидетельствует о его способности эффективно решать широкий спектр вопросов, требующих последовательного рассуждения и извлечения информации из нескольких источников. Данный результат подчеркивает универсальность David-GRPO и его способность адаптироваться к различным типам задач, требующих сложных логических операций.
В ходе экспериментов на бенчмарке BamTwoogle, David-GRPO продемонстрировал превосходство над AutoCoA, достигнув прироста в 9.09 процентных пункта по метрике EM Score. Дополнительно, при оценке по той же метрике, David-GRPO превзошел AutoCoA на 8.4 процентных пункта. Эти результаты подтверждают эффективность David-GRPO в задачах, требующих многошагового рассуждения и извлечения информации из сложных источников данных.
Результаты экспериментов демонстрируют, что использование методов обучения с подкреплением (RL), таких как David-GRPO, позволяет значительно повысить способность к рассуждению у небольших языковых моделей, таких как Qwen2.5 и Llama-3.2-1B. Данный подход позволяет достигать сопоставимых или превосходящих результатов по сравнению с более крупными моделями, требующими значительных вычислительных ресурсов, при этом используя лишь 4.7% от количества обучающих итераций, необходимых для этих моделей. Это указывает на перспективность RL-методов в контексте создания эффективных систем искусственного интеллекта, не требующих огромного количества параметров и, следовательно, снижающих затраты на обучение и эксплуатацию.
Использование небольших языковых моделей предоставляет существенные преимущества с точки зрения вычислительных затрат, энергоэффективности и гибкости развертывания. Сокращение количества параметров модели напрямую снижает требования к вычислительным ресурсам, необходимым для обучения и инференса, что ведет к снижению стоимости и времени обработки. Это особенно важно для приложений, требующих масштабируемости и работы в условиях ограниченных ресурсов, таких как мобильные устройства или периферийные вычисления. Более низкое энергопотребление небольших моделей также способствует экологической устойчивости и снижает операционные расходы. Кроме того, меньший размер модели упрощает развертывание и интеграцию в различные среды и платформы, обеспечивая большую гибкость в разработке и адаптации приложений.
За Гранью Бенчмарков: К Надежному и Адаптивному Рассуждению
Успех David-GRPO демонстрирует, что обучение с подкреплением представляет собой перспективный подход к преодолению ограничений, связанных с увеличением масштаба моделей для решения сложных задач, требующих рассуждений. В отличие от традиционных методов, которые полагаются на огромные объемы данных и вычислительные ресурсы, David-GRPO показал способность эффективно обучаться посредством взаимодействия со средой и получения обратной связи. Этот подход позволяет агенту не просто запоминать ответы, но и разрабатывать стратегии решения задач, что особенно важно для сценариев, где требуется адаптация к новым условиям и нестандартным ситуациям. Таким образом, обучение с подкреплением открывает новые возможности для создания более интеллектуальных и гибких систем, способных к сложному рассуждению без необходимости неограниченного увеличения размеров модели.
Интеграция поиска по нулевому запросу с использованием псевдо-релевантной обратной связи значительно повышает способность системы адаптироваться к новым данным и знаниям. Данный подход позволяет модели не просто запоминать информацию, но и активно искать и извлекать релевантный контекст из обширных источников, даже если эти источники не были явно указаны в процессе обучения. Псевдо-релевантная обратная связь, в свою очередь, позволяет системе уточнять поисковые запросы и отбирать наиболее полезную информацию, основываясь на первоначальных результатах поиска. Этот процесс самообучения и адаптации к новым данным, в отличие от статической базы знаний, обеспечивает более гибкое и надежное решение сложных задач, требующих актуальной информации и способности к обобщению.
Перспективы развития предложенного подхода простираются далеко за рамки текущих задач. Исследователи планируют адаптировать эту структуру для решения более сложных типов рассуждений, таких как здравый смысл и логический вывод. Особенно важным представляется применение к задачам, требующим понимания неявных знаний и контекста, где текущие модели часто демонстрируют ограниченные возможности. Адаптация алгоритма к задачам логического вывода позволит создать системы, способные к формальному анализу и доказательству теорем, что значительно расширит спектр решаемых проблем. Подобные исследования открывают путь к созданию более интеллектуальных систем, способных к гибкому и надежному решению широкого круга задач, приближая искусственный интеллект к человеческому уровню когнитивных способностей.
Разработка более эффективных и устойчивых агентов, способных к рассуждениям, представляется ключевым шагом в создании по-настоящему интеллектуальных систем, пригодных для решения реальных задач. В отличие от простого увеличения масштаба моделей, фокус на оптимизации процессов логического вывода и адаптации к новым данным позволяет создавать системы, способные не только решать известные задачи, но и эффективно справляться с непредвиденными ситуациями. Такие агенты, способные к гибкому мышлению и надежному принятию решений, необходимы для широкого спектра применений — от автоматизации сложных производственных процессов до разработки интеллектуальных систем поддержки принятия решений в критических областях, таких как медицина и финансы. Их устойчивость к шуму и неполноте информации, а также способность к самообучению и адаптации, открывают перспективы для создания действительно автономных и интеллектуальных систем, способных к решению сложных проблем в динамично меняющемся мире.
Исследование демонстрирует, что даже небольшие языковые модели способны на сложные рассуждения, если правильно организовать процесс поиска и использования информации. Разработанный фреймворк David-GRPO акцентирует внимание на эффективном исследовании пространства решений и привязке рассуждений к извлеченным данным, что позволяет преодолеть ограничения вычислительных ресурсов. Тим Бернерс-Ли однажды сказал: «Интернет — это для всех, и мы должны сделать все возможное, чтобы он оставался открытым и доступным». Подобно этой идее, David-GRPO стремится расширить возможности языковых моделей, делая сложные задачи доступными даже при ограниченных ресурсах. Подход, основанный на эффективном исследовании и обоснованных наградах, позволяет системам «стареть достойно», адаптируясь к изменяющимся условиям и поддерживая свою функциональность даже со временем.
Что дальше?
Представленная работа, безусловно, демонстрирует способность малых языковых моделей к многошаговому рассуждению, но эта способность, как и любая другая, ограничена временем. Рассматриваемая архитектура David-GRPO — лишь одна из возможных стратегий, оптимизированная для текущего состояния технологий. Вопрос не в том, насколько успешно она работает сейчас, а в том, как долго она сможет противостоять неизбежному устареванию. Упор на эффективное исследование и привязку рассуждений к извлекаемым доказательствам — разумный подход, но и он не является панацеей.
Следующим шагом представляется не столько увеличение масштаба моделей, сколько разработка систем, способных к самоадаптации и коррекции ошибок в процессе рассуждения. Вместо поиска «идеального» алгоритма, необходимо сосредоточиться на создании систем, способных извлекать уроки из собственных неудач. Решение, как и любая абстракция, несёт груз прошлого, и игнорирование этого груза обрекает систему на повторение ошибок.
Перспективы кажутся очевидными: переход от поиска оптимальных решений к созданию систем, способных к устойчивому развитию в меняющейся среде. Только медленные изменения сохраняют устойчивость, и в долгосрочной перспективе именно они определят, смогут ли «Давид» выдержать испытание временем, или же ему суждено уступить место более совершенным «Голиафам».
Оригинал статьи: https://arxiv.org/pdf/2601.21699.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Нефть, Геополитика и Рубль: Что ждет инвесторов в ближайшую неделю
- XRP Остывает: Анализ Снижения Спекуляций, DeFi-Рост и Юридические Риски (12.03.2026 07:45)
- Российская экономика: Бюджетное давление, геополитика и новые экспортные возможности (11.03.2026 21:32)
- Газпром акции прогноз. Цена GAZP
- Театр энергетики: акции, которые обещают вечность
- Российский Рынок: Банки и Дивиденды vs. Рубль и Геополитика – Что Ждет Инвесторов? (06.03.2026 00:32)
- Сургутнефтегаз префы прогноз. Цена SNGSP
- Падение ConocoPhillips в 2025: Тайные Каталы Восстановления
- Полюс акции прогноз. Цена PLZL
2026-02-02 04:20