Автор: Денис Аветисян
Исследователи предлагают инновационный подход к прогнозированию пожизненной ценности клиента, учитывающий особенности распределения данных и выявление наиболее ценных пользователей.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал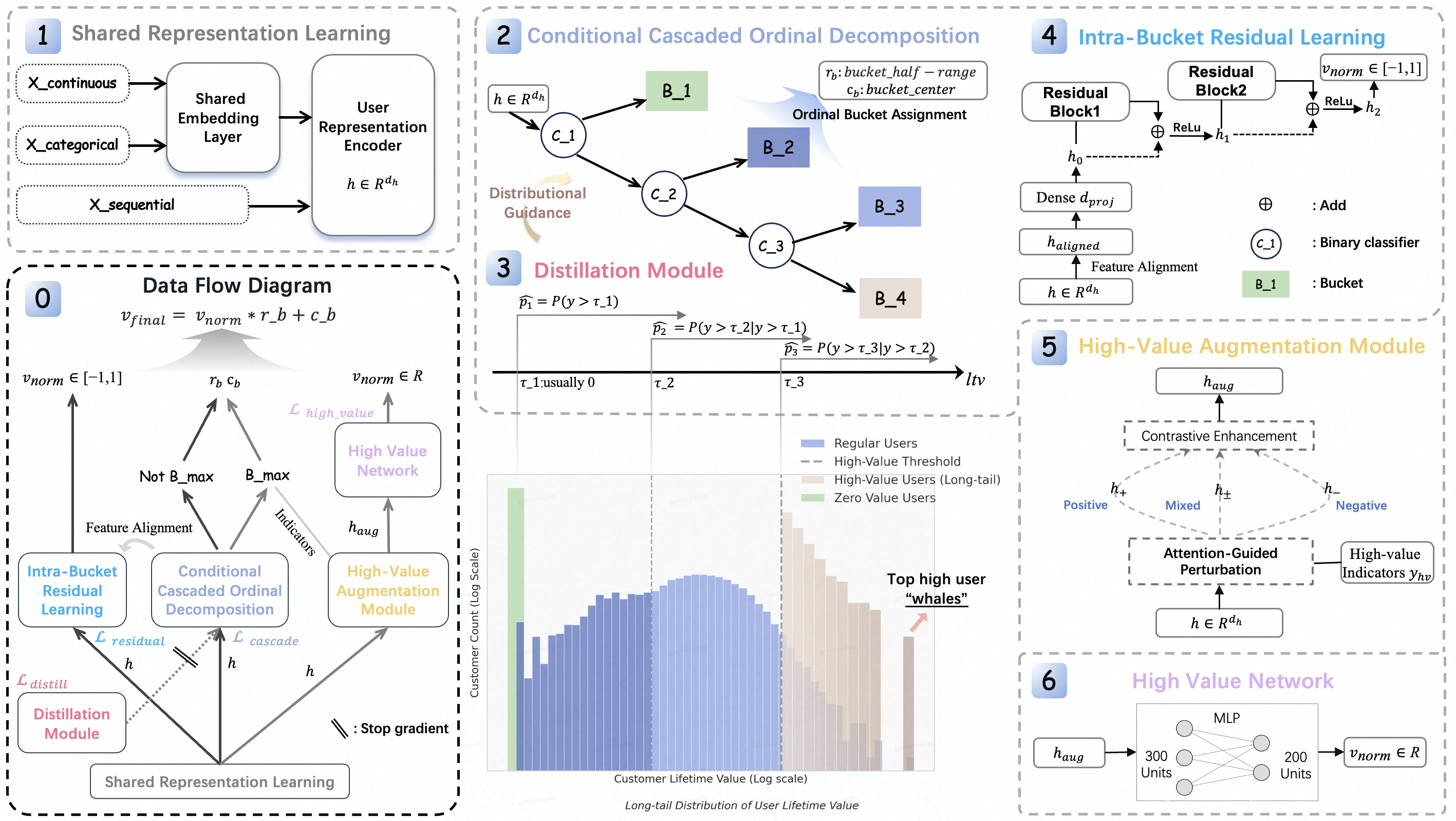
В статье представлена модель CC-OR-Net, объединяющая структурное разделение задач ранжирования и регрессии для более точного предсказания LTV.
Прогнозирование пожизненной ценности клиента (LTV) осложняется спецификой данных — преобладанием пользователей с низкой и средней ценностью и редким, но критически важным сегментом «китов». В данной работе, ‘CC-OR-Net: A Unified Framework for LTV Prediction through Structural Decoupling’, предложена новая архитектура глубокого обучения, которая структурно разделяет задачи ранжирования и регрессии, обеспечивая более точную оценку LTV в условиях неравномерного распределения. Предложенный фреймворк CC-OR-Net объединяет модули для устойчивого ранжирования, точной регрессии внутри сегментов и целевого усиления точности для пользователей с высокой ценностью. Сможет ли данный подход открыть новые возможности для персонализированного маркетинга и оптимизации стратегий удержания клиентов?
Прогнозирование LTV: Вызов длинного хвоста
Точное прогнозирование пожизненной ценности клиента (LTV) имеет решающее значение для современных веб-платформ, поскольку служит основой для эффективного распределения ресурсов и персонализации пользовательского опыта. Платформы, способные надежно предсказывать будущую ценность каждого клиента, получают возможность оптимизировать маркетинговые кампании, направляя инвестиции в наиболее перспективные сегменты аудитории. Более того, точный LTV позволяет адаптировать предлагаемые сервисы и контент под индивидуальные потребности, значительно повышая вовлеченность и лояльность пользователей. В конечном итоге, эффективное прогнозирование LTV становится ключевым фактором конкурентоспособности и устойчивого роста в динамичной цифровой среде, позволяя компаниям максимизировать отдачу от каждого взаимодействия с клиентом.
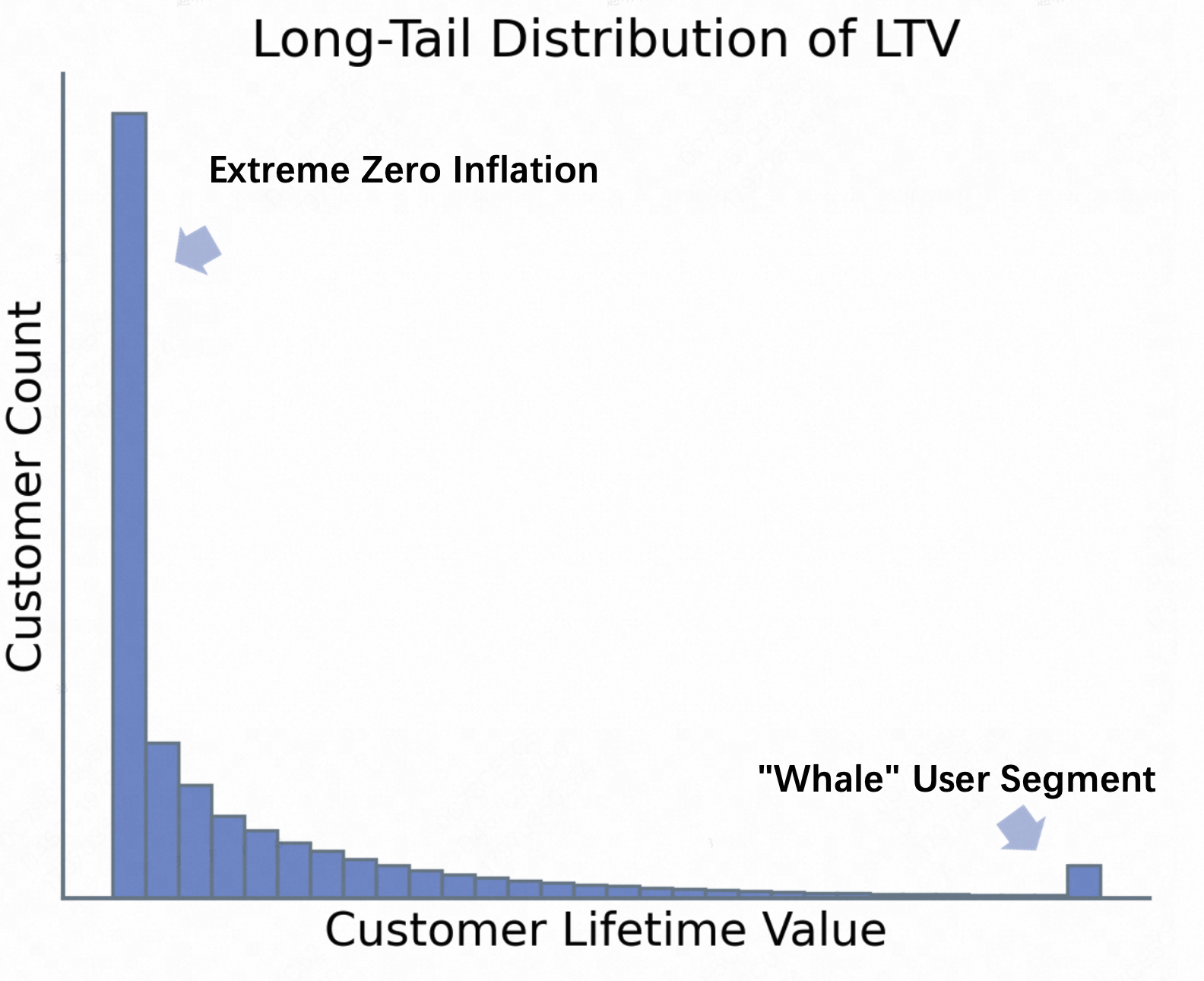
Традиционные модели прогнозирования пожизненной ценности клиента (LTV) часто сталкиваются с проблемой неравномерного распределения вклада пользователей, известной как «длинный хвост». Большинство пользователей вносят лишь незначительный вклад в общую ценность платформы, в то время как небольшая группа пользователей генерирует основную часть дохода. Это означает, что стандартные статистические методы, ориентированные на средние значения, могут быть неэффективными для точной оценки LTV, поскольку они не учитывают выраженную асимметрию данных. В результате, модели склонны к занижению ценности наиболее активных пользователей и переоценке ценности неактивных, что негативно сказывается на эффективности маркетинговых кампаний и персонализации предложений. Преодоление этой проблемы требует применения специализированных методов, способных эффективно работать с данными, характеризующимися выраженной асимметрией и большим количеством нулевых значений.
Существенное усложнение прогнозирования пожизненной ценности клиента (LTV) связано с феноменом нулевой инфляции — значительным преобладанием пользователей, не приносящих никакой ценности. Данное явление не просто увеличивает дисбаланс в данных, но и существенно искажает работу традиционных моделей, приводя к неточным оценкам и затрудняя эффективную сегментацию клиентской базы. Модели, не учитывающие эту особенность, склонны к занижению ценности активных пользователей и не позволяют выявить наиболее прибыльные группы клиентов, что негативно сказывается на персонализации и оптимизации маркетинговых стратегий. Игнорирование нулевой инфляции приводит к снижению точности прогнозов и затрудняет принятие обоснованных бизнес-решений, направленных на максимизацию прибыли.
Выделение и приоритизация сегмента “китов” — небольшой, но критически важной группы пользователей, приносящих наибольшую ценность — представляет собой сложную задачу для веб-платформ. Несмотря на то, что эти пользователи составляют лишь малую долю от общей базы, именно они генерируют значительную часть дохода и обеспечивают устойчивость бизнеса. Определение таких пользователей затруднено из-за их малочисленности и схожести с остальной массой пользователей на ранних этапах взаимодействия с платформой. Традиционные методы сегментации часто оказываются неэффективными, требуя разработки специализированных алгоритмов и моделей, способных выявлять скрытые закономерности и предсказывать будущую ценность каждого пользователя. Успешное выявление и удержание “китов” становится ключевым фактором конкурентоспособности и долгосрочного успеха веб-сервисов.
CC-OR-Net: Разделение ординальности и регрессии
CC-OR-Net представляет собой унифицированную архитектуру, разработанную для раздельного решения задач ранжирования и регрессии при прогнозировании пожизненной ценности клиента (LTV). Традиционные подходы часто объединяют эти задачи, что приводит к сложностям в обучении и снижению точности. В CC-OR-Net ранжирование и регрессия обрабатываются независимо друг от друга, позволяя модели более эффективно улавливать зависимости в данных и повышать общую производительность. Такое разделение позволяет оптимизировать каждый компонент независимо, что приводит к улучшению как качества ранжирования, так и точности прогнозируемой ценности клиента.
Ключевым новшеством CC-OR-Net является метод условного каскадного ординального разложения (Conditional Cascaded Ordinal Decomposition). Он преобразует задачу K-классовой ординальной классификации в последовательность K-1 задач бинарной классификации. Вместо непосредственного прогнозирования ранга клиента в одной из K категорий, модель последовательно определяет, принадлежит ли клиент к группе с более высоким рангом. Каждая бинарная классификация обучена условно, учитывая результаты предыдущих шагов, что позволяет модели фокусироваться на различении только двух соседних рангов на каждом этапе. Такое разложение упрощает процесс обучения и повышает точность прогнозирования, особенно при работе с несбалансированными данными.
Разложение задачи на последовательность бинарных классификаций позволяет модели сосредотачиваться на различении между смежными классами, а не на одновременном предсказании всей ординальной шкалы. Это особенно важно при работе с данными о LTV, где распределение клиентов по ценности часто крайне неравномерно — преобладают клиенты с низкой ценностью, что создает проблему несбалансированности классов. Прямое моделирование такой имбалансированной ординальной зависимости приводит к смещению в сторону преобладающего класса и снижению точности предсказаний для клиентов с высокой ценностью. Предложенный подход, напротив, позволяет более эффективно обучать модель, избегая этой проблемы и повышая точность прогнозирования для всех сегментов клиентов.
Модель CC-OR-Net предлагает надежное решение проблемы трилеммы прогнозирования LTV, заключающейся в одновременной оптимизации качества ранжирования, точности регрессии и прецизионности прогнозов для клиентов с высокой ценностью. В ходе экспериментов было установлено, что CC-OR-Net обеспечивает снижение предвзятости при прогнозировании высокоценных клиентов на 25.0% (измеряется как AMBE — Absolute Mean Bias Error) по сравнению с базовыми моделями, что свидетельствует о повышении точности и надежности прогнозов LTV.
![На Domain 1 модель CC-OR-Net значительно превосходит ExpLTV и OptDist в выявлении наиболее ценных пользователей при фиксированном бюджете, достигая показателя [latex]Recall@5000[/latex] в 38.1% и обеспечивая максимальную отдачу от маркетинговых инвестиций.](https://arxiv.org/html/2601.10176v1/fig2.png)
Таргетированное обучение для пользователей с высокой ценностью
Модуль усиления ценных пользователей (High-Value Augmentation Module) в CC-OR-Net предназначен для оптимизации распределения вычислительных ресурсов, направляя их исключительно на сегмент наиболее ценных пользователей. Данный подход позволяет повысить точность прогнозирования и улучшить качество обслуживания для критически важной группы, обеспечивая более эффективное использование доступных ресурсов. Вместо равномерного распределения, модуль динамически выделяет больше вычислительной мощности для обработки данных, связанных с пользователями, демонстрирующими наибольшую ценность, что позволяет добиться существенного улучшения показателей модели в отношении этой ключевой группы.
Таргетированная аугментация в CC-OR-Net реализуется путем целенаправленного увеличения объема данных и вычислительных ресурсов, выделяемых для обучения модели на сегменте редких, но высокоценных пользователей. Этот подход позволяет модели более эффективно изучать закономерности, характерные именно для этой группы, что невозможно при равномерном распределении ресурсов. Вместо обработки всего объема данных с одинаковой интенсивностью, система концентрируется на примерах, связанных с пользователями, генерирующими наибольшую ценность, тем самым повышая точность прогнозирования и оптимизируя производительность модели для ключевого сегмента аудитории.
Для повышения эффективности целевого подхода модуль использует Focal Loss — функцию потерь, которая снижает вес простых примеров и концентрируется на наиболее сложных случаях. Это достигается путем динамической регулировки весов примеров во время обучения: простые примеры, для которых модель предсказывает верный ответ с высокой уверенностью, получают меньший вес в общей функции потерь. В результате, градиенты от этих примеров оказывают меньшее влияние на обновление параметров модели, что позволяет ей более эффективно обучаться на редких и сложных случаях, представляющих наибольшую ценность. Таким образом, Focal Loss позволяет оптимизировать процесс обучения, направляя вычислительные ресурсы на те примеры, которые требуют наибольшего внимания.
В дополнение к основным методам обучения, CC-OR-Net использует Intra-Bucket Residual Learning для более точной оценки ценности пользователей. Этот подход позволяет учитывать небольшие, но значимые различия в поведении внутри каждой группы (bucket) пользователей, объединенных по общей ценности. Вместо обобщенной оценки для всей группы, Intra-Bucket Residual Learning моделирует остаточные отклонения от среднего значения внутри bucket, что повышает точность предсказаний и позволяет более эффективно ранжировать пользователей по их потенциальной ценности. Таким образом, модель способна выявлять даже небольшие нюансы в поведении, влияющие на ценность пользователя, что приводит к более персонализированным и точным прогнозам.
![Анализ компромиссов в Domain 1 показывает, что CC-OR-Net обеспечивает наилучший баланс между общей точностью ([latex]SVA[/latex]) и смещением в сторону важных значений ([latex]AMBE[/latex]), при этом размер пузырька отражает задержку вывода, а предложенный модуль аугментации направлен на дальнейшее улучшение этих показателей.](https://arxiv.org/html/2601.10176v1/fig1.png)
Повышение стабильности и обобщающей способности
Для регуляризации распределения данных в пределах одной партии и предотвращения переобучения, CC-OR-Net использует механизм потерь, известный как Distillation Loss. Этот подход позволяет модели учиться не только на прямых метках, но и на «мягких» вероятностях, полученных от другой, более стабильной модели или предыдущей версии той же модели. По сути, Distillation Loss способствует передаче знаний, делая процесс обучения более устойчивым к шумам и вариациям в данных. Это особенно важно при работе с несбалансированными наборами данных, где модель может быть склонна к запоминанию редких классов вместо обобщения закономерностей. В результате, CC-OR-Net демонстрирует повышенную способность к обобщению и надежность прогнозов даже при изменении входных данных.
Для обеспечения стабильности и надежности прогнозов модели при обработке различных партий данных, используется специальный механизм регуляризации. Данный подход гарантирует, что предсказания модели не будут существенно колебаться в зависимости от конкретной выборки данных, что особенно важно при работе с несбалансированными наборами или сложными взаимосвязями в данных. По сути, модель обучается выдавать согласованные результаты, даже если состав каждой партии данных немного отличается, что повышает её устойчивость к шумам и обеспечивает более предсказуемое поведение в реальных условиях эксплуатации. Это способствует более надежной оценке и приоритезации пользователей, особенно в бизнес-контексте, где важна точность и стабильность результатов.
Сеть CC-OR-Net демонстрирует существенное повышение точности стратифицированной ценности (SVA) благодаря эффективной обработке проблем, связанных с несбалансированными данными и сложными взаимосвязями между признаками. Традиционные модели часто испытывают трудности при работе с наборами данных, где одни классы представлены значительно чаще других, что приводит к смещению в прогнозах. CC-OR-Net, напротив, использует инновационные методы для выявления и смягчения этих дисбалансов, позволяя модели более точно оценивать ценность каждого пользователя, независимо от его принадлежности к определенной группе. Благодаря этому, достигается более надежное ранжирование пользователей и, как следствие, оптимизация бизнес-показателей, поскольку модель способна более эффективно выявлять и приоритизировать наиболее ценных клиентов.
Ключевым показателем эффективности CC-OR-Net является точность стратифицированной ценности (SVA), которая напрямую отражает способность модели выявлять и приоритизировать пользователей с высокой потенциальной прибылью. В отличие от стандартных метрик, SVA оценивает не просто общую точность предсказаний, а фокусируется на корректном определении наиболее ценных сегментов аудитории. Это позволяет бизнесу оптимизировать маркетинговые кампании, персонализировать предложения и эффективно распределять ресурсы, максимизируя возврат инвестиций. Улучшение SVA, достигаемое благодаря CC-OR-Net, означает не просто повышение точности модели, а ощутимый рост ключевых бизнес-показателей и улучшение коммерческих результатов.
Исследование демонстрирует, что попытки построить универсальные модели для предсказания ценности клиента обречены на провал из-за неравномерности данных. Как справедливо заметил Пол Эрдеш: «Математика — это искусство открывать закономерности, которые другие не видят». Подобно тому, как математик ищет скрытые связи, авторы статьи предлагают структурное разделение задач ранжирования и регрессии, чтобы лучше учитывать особенности распределения клиентов. Вместо того, чтобы строить единую систему, они предлагают подход, который позволяет системе развиваться, адаптируясь к сложным данным и выявляя ценных пользователей даже в условиях «длинного хвоста» распределения.
Куда Ведет Эта Дорога?
Представленная работа, стремясь разделить задачи ранжирования и регрессии в предсказании пожизненной ценности клиента, лишь обнажает более глубокую проблему: попытка укротить хаос, заставив его говорить на языке ожиданий. Долгое время исследователи полагали, что можно «построить» систему, предсказывающую поведение. Однако, очевидно, что системы — это не конструкции, а развивающиеся экосистемы. Успех CC-OR-Net, как и любого подобного подхода, не измеряется точностью прогноза, а скорее способностью адаптироваться к неизбежной непредсказуемости.
Особое внимание следует уделить не столько улучшению алгоритмов, сколько пониманию природы «хвоста» распределения. Определение высокоценных пользователей — это не поиск редких экземпляров, а признание того, что ценность — понятие относительное и контекстуальное. Гарантий, разумеется, не существует. Есть лишь соглашение с вероятностью, которое время от времени нарушается.
В будущем, вероятно, потребуется отказ от стремления к единой модели, способной охватить все сценарии. Стабильность — это иллюзия, которая хорошо кэшируется, но рано или поздно дает сбой. Более перспективным представляется подход, основанный на создании ансамбля адаптивных моделей, способных обучаться и эволюционировать в реальном времени, признавая, что истинный прорыв лежит не в предсказании будущего, а в способности реагировать на него.
Оригинал статьи: https://arxiv.org/pdf/2601.10176.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- ТГК-14 акции прогноз. Цена TGKN
- Серебро прогноз
- Татнефть префы прогноз. Цена TATNP
- Крипто-рынок в тумане: Отток ETF, раскол ФРС и устойчивость Bitcoin (30.04.2026 21:15)
- Мечел акции прогноз. Цена MTLR
- Палантир: Иллюзии Будущего
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- Будущее SOL: прогноз цен на криптовалюту SOL
2026-01-17 21:17