Автор: Денис Аветисян
Новый подход сочетает в себе машинное обучение и линейное программирование для создания персонализированных рекомендаций, учитывающих интересы как пользователей, так и бизнеса.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал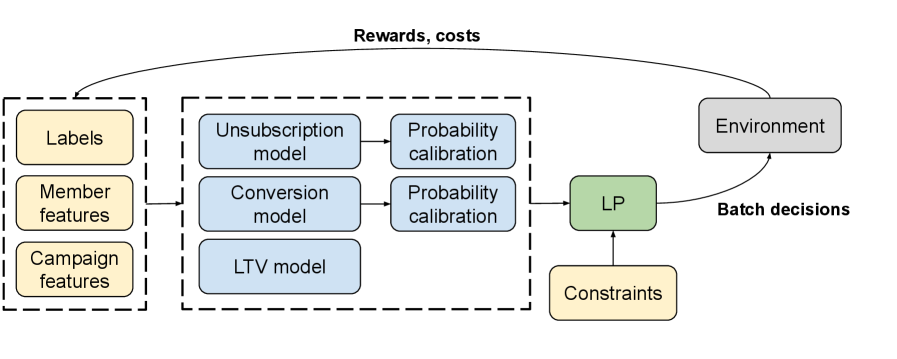
Представлен BanditLP — алгоритм, использующий контекстные бандиты и крупномасштабное линейное программирование для оптимизации рекомендаций с учетом сложных ограничений и интересов нескольких заинтересованных сторон.
В современных системах персоментированных рекомендаций часто возникает противоречие между стремлением к максимальной эффективности и необходимостью учета множества ограничений и интересов заинтересованных сторон. В данной работе представлена методология ‘BanditLP: Large-Scale Stochastic Optimization for Personalized Recommendations’, объединяющая нейронные контекстуальные бандиты и крупномасштабное линейное программирование для оптимизации рекомендаций с учетом сложных ограничений. Предложенный подход демонстрирует значительные улучшения по сравнению с существующими методами, обеспечивая баланс между исследованием и использованием новых стратегий. Возможно ли дальнейшее масштабирование и адаптация BanditLP для решения еще более сложных задач оптимизации в различных областях, включая маркетинг и финансы?
Многоцелевая Оптимизация: Вызов Традиционным Рекомендательным Системам
Традиционные системы рекомендаций, как правило, ориентированы на оптимизацию единственной метрики, например, предсказание вероятности клика или покупки. Такой подход зачастую игнорирует интересы различных заинтересованных сторон — пользователей, контент-провайдеров и владельцев платформы. Например, максимизация кликабельности может привести к продвижению сенсационного, но не всегда качественного контента, что негативно сказывается на удовлетворении пользователей и доходах контент-провайдеров. Аналогично, оптимизация исключительно для увеличения продаж может привести к игнорированию потребностей пользователей в разнообразии или открытии нового контента. В результате, системы, сосредоточенные на одной цели, могут оказаться неэффективными в долгосрочной перспективе, приводя к снижению вовлеченности и общей ценности платформы.
Неэффективность традиционных рекомендательных систем, ориентированных на единственную цель, часто приводит к неудовлетворительным результатам для всех заинтересованных сторон. Пользователи могут сталкиваться с предложениями, не соответствующими их истинным предпочтениям, что снижает вовлеченность и лояльность. Провайдеры контента, в свою очередь, могут испытывать разочарование из-за недостаточной видимости релевантного материала и, как следствие, снижения дохода. Владельцы платформ, стремящиеся к максимизации прибыли и удержанию аудитории, также страдают от этой ситуации, поскольку неудовлетворенность пользователей и провайдеров негативно сказывается на общей эффективности и рентабельности системы. Таким образом, однобокий подход к рекомендациям создает замкнутый круг, требующий комплексного решения, учитывающего интересы всех участников.
Для эффективного решения проблемы конфликтующих приоритетов необходима разработка комплексной системы, способной к балансировке множественных, зачастую противоречивых целей. Такая система должна учитывать интересы всех заинтересованных сторон — пользователей, поставщиков контента и владельцев платформы — и находить компромиссные решения, оптимизирующие общую эффективность. Она требует применения продвинутых алгоритмов, позволяющих не просто максимизировать одну метрику, но и учитывать взаимосвязи между различными показателями, а также устанавливать приоритеты в зависимости от конкретной ситуации. Подобный подход позволяет создавать более устойчивые и справедливые рекомендательные системы, способные удовлетворять потребности всех участников и обеспечивать долгосрочный успех платформы.
Оптимизация с Ограничениями: Баланс Многосторонних Интересов
В многосторонних системах рекомендаций обеспечение соблюдения ограничений является критически важным. Это обусловлено необходимостью учета интересов различных заинтересованных сторон и предотвращения выдачи рекомендаций, нарушающих установленные правила или лимиты. Ограничения могут включать в себя бюджетные рамки, доступность контента, политические или юридические требования, а также предпочтения пользователей, выраженные в виде нежелательных категорий или брендов. Несоблюдение этих ограничений может привести к снижению доверия пользователей, юридическим последствиям или неэффективному использованию ресурсов системы. Поэтому, алгоритмы оптимизации должны учитывать эти ограничения как неотъемлемую часть процесса формирования рекомендаций, обеспечивая их соответствие заданным границам и требованиям.
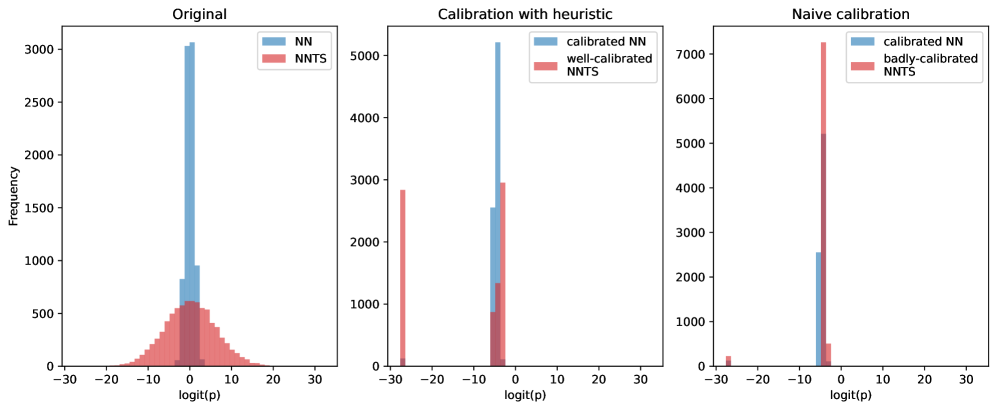
Для эффективной оптимизации в системах рекомендаций необходимо количественно оценить как желаемые результаты, так и нежелательные последствия. Это достигается посредством использования функции вознаграждения (Reward Function), которая численно выражает ценность положительных исходов, например, увеличение кликов или покупок. Одновременно, функция стоимости (Cost Function) определяет величину штрафа за нежелательные эффекты, такие как показ нерелевантного контента или нарушение ограничений, установленных для различных заинтересованных сторон. Оптимизация, таким образом, сводится к поиску баланса между максимизацией функции вознаграждения и минимизацией функции стоимости, что позволяет получить рекомендации, наилучшим образом соответствующие заданным критериям и ограничениям. \text{Optimization} = \arg\max_{x} \text{Reward}(x) - \lambda \text{Cost}(x) , где λ — коэффициент, определяющий вес функции стоимости.
Стохастическая оптимизация представляет собой надежный подход к решению задач в реальных рекомендательных системах, характеризующихся неотъемлемой случайностью и сложностью. В отличие от детерминированных методов, стохастические алгоритмы учитывают вероятностную природу данных и процессов, что особенно важно при работе с большими объемами информации и динамически меняющимися предпочтениями пользователей. Использование стохастических градиентных методов, таких как Adam или RMSprop, позволяет эффективно оценивать градиенты целевой функции на основе случайных подмножеств данных, снижая вычислительные затраты и обеспечивая сходимость к оптимальному решению даже в условиях неполной или зашумленной информации. Применение методов Монте-Карло и симуляций также позволяет оценивать риски и неопределенности, связанные с различными рекомендациями, и выбирать наиболее устойчивые и надежные стратегии.
BanditLP: Алгоритм для Гармонии Многосторонних Интересов
Алгоритм BanditLP объединяет Neural Thompson Sampling (NTS) с линейным программированием (LP) для интеллектуального балансирования целей различных заинтересованных сторон при наличии ограничений. NTS используется для эффективного исследования пространства рекомендаций, позволяя алгоритму быстро адаптироваться к изменяющимся условиям и находить оптимальные решения. Линейное программирование, в свою очередь, обеспечивает соблюдение заданных ограничений, таких как бюджетные ограничения или ограничения на доступные ресурсы, гарантируя, что решения, предложенные NTS, являются осуществимыми и соответствуют установленным правилам. Интеграция этих двух подходов позволяет BanditLP находить компромиссы между конкурирующими целями, максимизируя общую производительность системы при одновременном удовлетворении всех необходимых ограничений.
Алгоритм BanditLP использует Neural Thompson Sampling для эффективного исследования пространства рекомендаций, что позволяет быстро идентифицировать перспективные варианты. В то же время, интеграция с линейным программированием (Linear Program) обеспечивает соблюдение заданных ограничений и целевых показателей, таких как бюджет, квоты или минимальные требования к разнообразию. Neural Thompson Sampling оптимизирует процесс исследования, а линейное программирование гарантирует, что выбранные рекомендации соответствуют установленным рамкам, предотвращая выход за допустимые границы и обеспечивая стабильность системы.
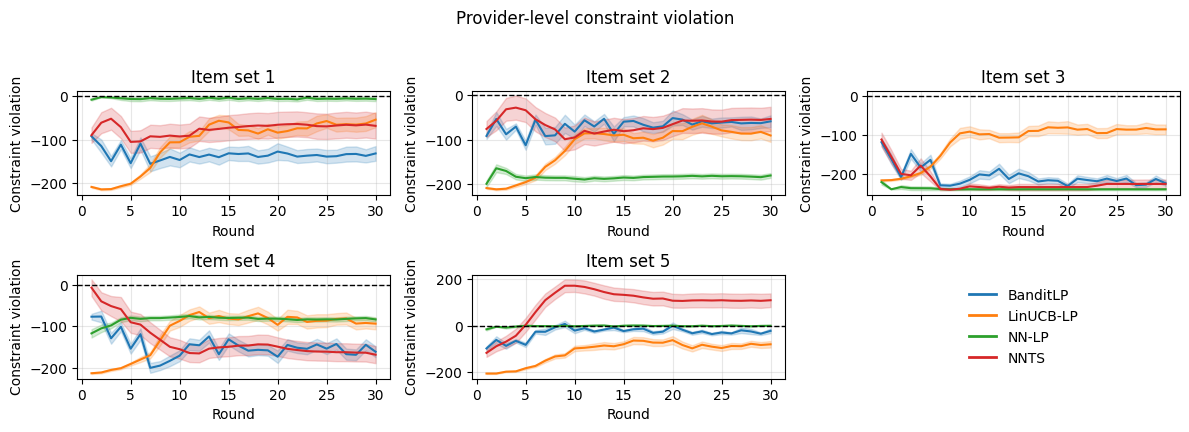
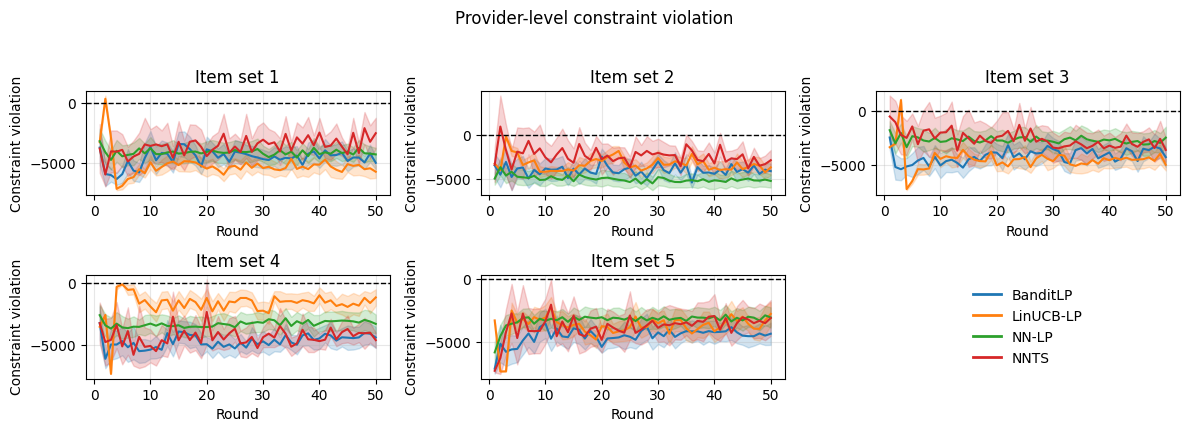
В ходе A/B тестирования на платформе LinkedIn, алгоритм BanditLP продемонстрировал статистически значимое увеличение долгосрочной выручки на 3.08% и снижение оттока пользователей на 1.51%. Полученные результаты подтверждают практическую эффективность BanditLP в оптимизации рекомендаций с учетом множества заинтересованных сторон и ограничений, что позволяет одновременно повышать экономические показатели и улучшать удержание аудитории.
Дилемма Исследования и Эксплуатации: Баланс для Эффективных Рекомендаций
В основе успеха BanditLP лежит тонкий баланс между исследованием и эксплуатацией — фундаментальная проблема, успешно решаемая посредством контекстуальных бандитов. Алгоритм не просто использует уже известные предпочтения пользователей, но и постоянно исследует новые варианты, адаптируясь к меняющимся условиям и приоритетам заинтересованных сторон. Контекстуальные бандиты позволяют BanditLP учитывать индивидуальные характеристики каждого пользователя и динамически корректировать стратегию рекомендаций, обеспечивая оптимальное сочетание проверенных решений и инновационных предложений. Эта способность к адаптации и постоянному обучению является ключевым фактором, определяющим эффективность алгоритма и его способность максимизировать общую удовлетворенность пользователей.
Алгоритм BanditLP не статичен, а постоянно совершенствуется благодаря способности адаптироваться к меняющимся запросам пользователей и приоритетам заинтересованных сторон. Этот процесс непрерывного обучения происходит за счет анализа обратной связи и корректировки стратегии рекомендаций в режиме реального времени. Алгоритм не просто запоминает предпочтения, но и прогнозирует их эволюцию, учитывая контекст и динамику взаимодействия. Такая гибкость позволяет BanditLP оставаться актуальным и эффективным даже при значительных изменениях в поведении пользователей или бизнес-целях, что подтверждается заметным улучшением ключевых показателей, таких как увеличение дохода и снижение оттока клиентов.
Алгоритм BanditLP демонстрирует высокую эффективность в предоставлении надежных и персонализированных рекомендаций благодаря сбалансированному подходу к исследованию и использованию доступной информации. Данная стратегия позволяет системе адаптироваться к меняющимся предпочтениям пользователей и приоритетам заинтересованных сторон, что подтверждается результатами A/B тестирования. В ходе испытаний наблюдалось увеличение дохода на 3.08% и снижение оттока подписчиков на 1.51%, что свидетельствует о значимом влиянии алгоритма на повышение общей удовлетворенности и удержание аудитории. Оптимизация баланса между поиском новых, потенциально лучших решений и использованием уже проверенных стратегий является ключевым фактором успеха BanditLP в динамичной среде.
Представленное исследование демонстрирует элегантность подхода к оптимизации рекомендаций, где сложный процесс выбора стратегии рассматривается как задача линейного программирования. Авторы искусно сочетают методы обучения с подкреплением и мощь линейного программирования для достижения оптимальных результатов в условиях множества ограничений и заинтересованных сторон. Как однажды заметил Марвин Минский: «Лучший способ сделать что-то сложным — это сделать это простым». Этот принцип находит отражение в BanditLP, где кажущаяся сложность проблемы решается через четкую математическую формулировку и эффективные алгоритмы, позволяющие достичь значительных улучшений в практических приложениях, таких как email-маркетинг в LinkedIn. Подход демонстрирует, что ясность и строгость математического моделирования являются ключевыми факторами успешной разработки алгоритмов.
Что Дальше?
Представленный подход, хотя и демонстрирует улучшения в оптимизации рекомендаций, поднимает вопрос о фундаментальной сложности задачи. Сведение многосторонней оптимизации к линейному программированию, безусловно, элегантно, но не избавляет от экспоненциального роста вычислительных затрат при увеличении числа заинтересованных сторон и ограничений. Необходимо искать алгоритмы, обладающие более благоприятной асимптотикой, возможно, используя стохастические аппроксимации или декомпозицию задачи на более управляемые подзадачи.
Особое внимание следует уделить вопросу устойчивости решения. Гарантирует ли предложенный метод сходимость к глобальному оптимуму, или он склонен к локальным экстремумам? Анализ условий сходимости и разработка методов избежания локальных оптимумов представляются критически важными. Кроме того, необходимо исследовать влияние неточности данных и шума на качество рекомендаций, а также разработать робастные алгоритмы, устойчивые к этим факторам.
В конечном счете, истинная красота алгоритма проявляется не в его способности решать конкретную задачу, а в его способности адаптироваться к новым условиям и ограничениям. Дальнейшие исследования должны быть направлены на создание самообучающихся систем, способных автоматически определять оптимальные стратегии рекомендаций в динамически меняющейся среде. Лишь тогда можно будет говорить о действительно элегантном и эффективном решении.
Оригинал статьи: https://arxiv.org/pdf/2601.15552.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Будущее SOL: прогноз цен на криптовалюту SOL
- Мечел акции прогноз. Цена MTLR
- ТГК-14 акции прогноз. Цена TGKN
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- Будущее биткоина к рублю: прогноз цен на криптовалюту BTC
- КуйбышевАзот акции прогноз. Цена KAZT
- Татнефть префы прогноз. Цена TATNP
- Аэрофлот акции прогноз. Цена AFLT
2026-01-23 08:40