Автор: Денис Аветисян
Исследователи разработали метод, объединяющий обучение с подкреплением и моделирование, позволяющий роботам эффективно адаптироваться к сложным условиям.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал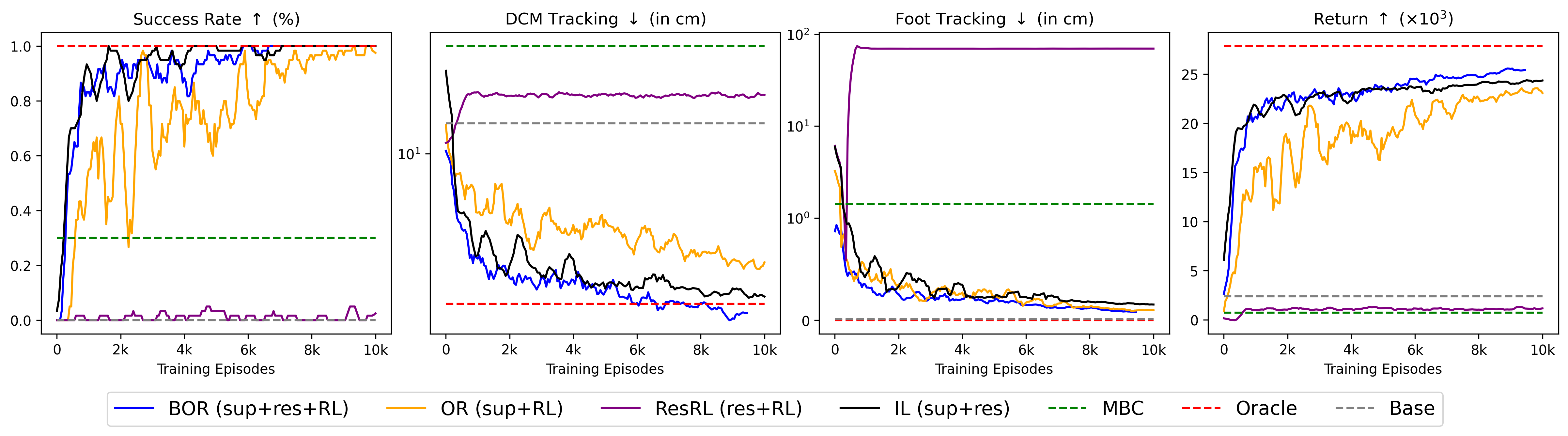
Предложен фреймворк, сочетающий обучение с подкреплением, управляемое моделями, и «оракул» для повышения устойчивости и эффективности управления крутящим моментом у гуманоидных роботов.
Несмотря на значительный прогресс в области робототехники, создание устойчивого и адаптивного двуногого передвижения в реальных условиях остается сложной задачей. В работе ‘Efficiently Learning Robust Torque-based Locomotion Through Reinforcement with Model-Based Supervision’ предложен фреймворк, объединяющий управление на основе модели с обучением с подкреплением для повышения надежности и адаптивности при ходьбе. Ключевым является использование «оракульной» политики на основе модели, направляющей обучение остаточной политики, что позволяет эффективно компенсировать немоделируемые эффекты и улучшить обобщающую способность. Возможно ли масштабирование данного подхода для решения более сложных задач двуногого передвижения и достижения полной автономии роботов в неструктурированных средах?
Когда Идеальная Модель Встречает Реальность
Создание устойчивого двуногого передвижения для роботов сталкивается с серьезными трудностями, обусловленными неизбежными неточностями в моделях и непредсказуемостью окружающей среды. Даже самые совершенные математические представления о динамике робота и его взаимодействии с поверхностью не могут полностью учесть все нюансы реального мира — от незначительных изменений в коэффициенте трения до неровностей пола и внезапных возмущений. Эти расхождения между моделью и физической реальностью приводят к ошибкам в управлении, что, в свою очередь, негативно сказывается на стабильности и эффективности передвижения робота. Успех в этой области требует разработки алгоритмов, способных адаптироваться к этим непредсказуемым условиям и компенсировать неизбежные погрешности моделирования, что является сложной, но решаемой задачей современной робототехники.
Несоответствие между математической моделью робота и его реальным воплощением является критическим фактором, ограничивающим возможности управления и стабильность передвижения. В процессе проектирования, неизбежно возникают погрешности в оценке массы, трения, упругости компонентов и других параметров, которые, даже будучи незначительными, накапливаются и приводят к существенным отклонениям в поведении робота. Например, неточности в определении центра масс могут вызывать колебания и потерю равновесия при ходьбе, а недоучет внешних возмущений, таких как неровности поверхности или порывы ветра, могут приводить к падениям. Эти расхождения между моделью и реальностью требуют разработки сложных алгоритмов управления, способных адаптироваться к неопределенностям и компенсировать ошибки, чтобы обеспечить надежную и эффективную локомоцию робота в реальном мире.
Управление на Основе Модели: Теория и Практика
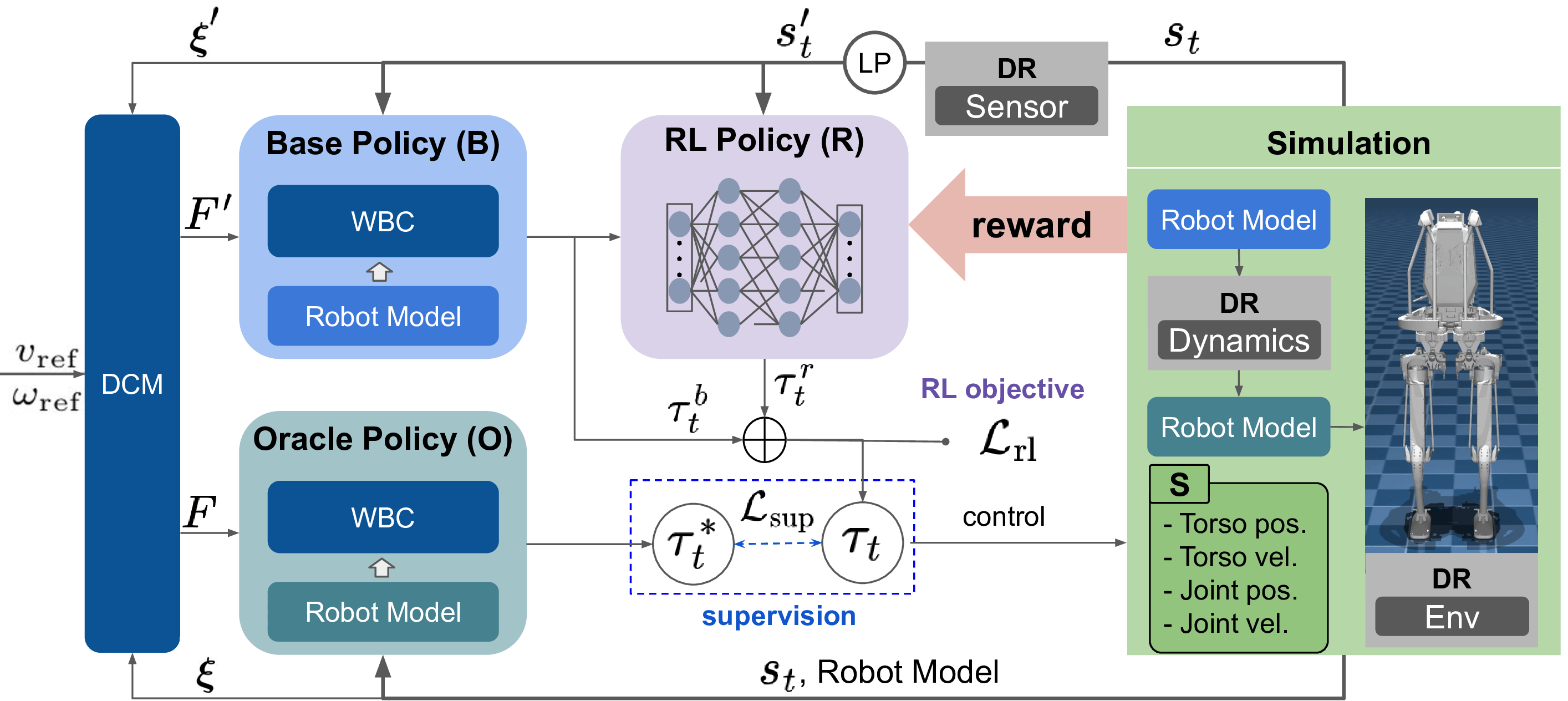
В основе нашего подхода лежит управление на основе модели, использующее точные данные о динамике робота и оценку состояния для планирования и управления. Это предполагает построение математической модели, описывающей взаимосвязь между входными сигналами (например, моментами на суставах) и результирующим движением робота. Точность этой модели критически важна для эффективности управления; неточности могут приводить к отклонениям от планируемой траектории и снижению производительности. Оценка состояния, как правило, включает в себя использование сенсорных данных (например, от энкодеров суставов, инерциальных измерительных блоков) для определения текущего положения, скорости и ускорения робота, что необходимо для корректного выполнения алгоритмов планирования и управления.
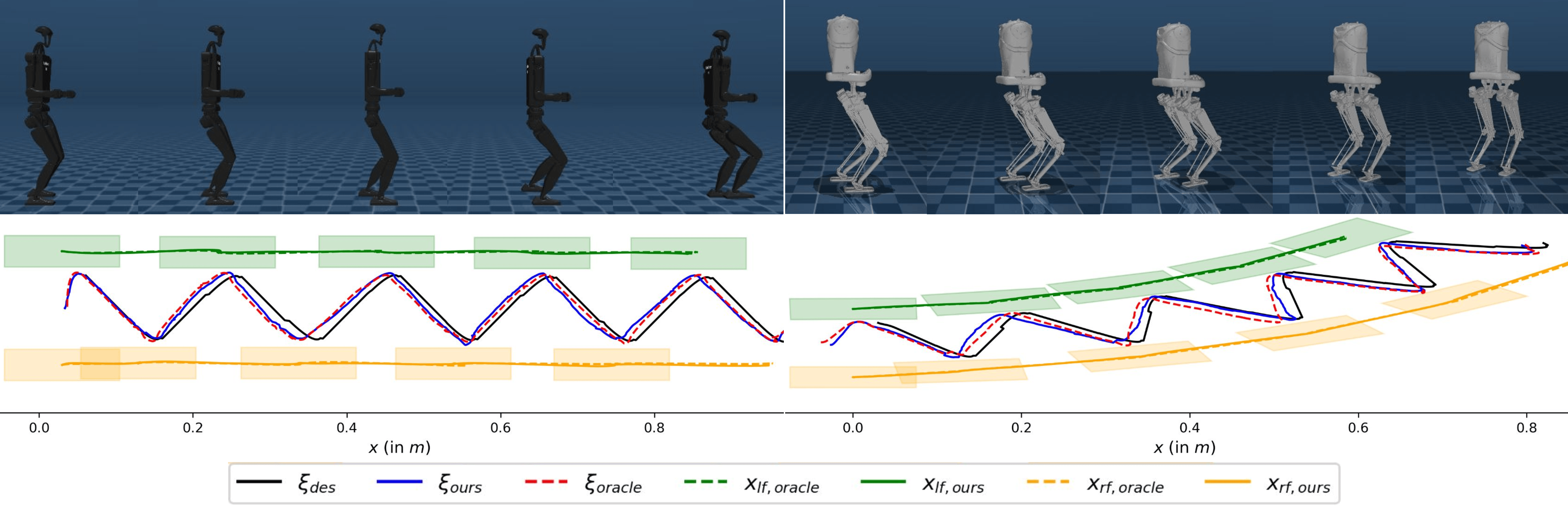
В основе планирования траекторий движения используется фреймворк, базирующийся на понятии расходящейся компоненты движения (DCM — Divergent Component of Motion). DCM представляет собой векторное поле, определяющее желаемое направление и скорость движения центра масс робота. Использование DCM позволяет генерировать стабильные и эффективные траектории, поскольку обеспечивает управление положением и ориентацией центра масс без явного решения сложных задач оптимизации. Данный подход позволяет добиться устойчивого движения, минимизируя отклонения от запланированной траектории и обеспечивая эффективное использование энергии при движении робота.
Реализация данной схемы управления осуществляется посредством контроллера, основанного на обратной динамике, который вычисляет необходимые моменты сил, воздействующие на все звенья робота, для точного следования запланированным траекториям. Данный подход предполагает решение уравнений обратной динамики для каждого момента времени, учитывая инерцию, гравитацию, кориолисовы и центробежные силы, а также внешние воздействия. Вычисленные моменты сил передаются на исполнительные механизмы робота, обеспечивая требуемое движение. Точность и стабильность управления напрямую зависят от точности модели динамики робота и эффективности алгоритма решения обратной динамической задачи.
Остаточная Политика: Корректировка Неизбежных Ошибок
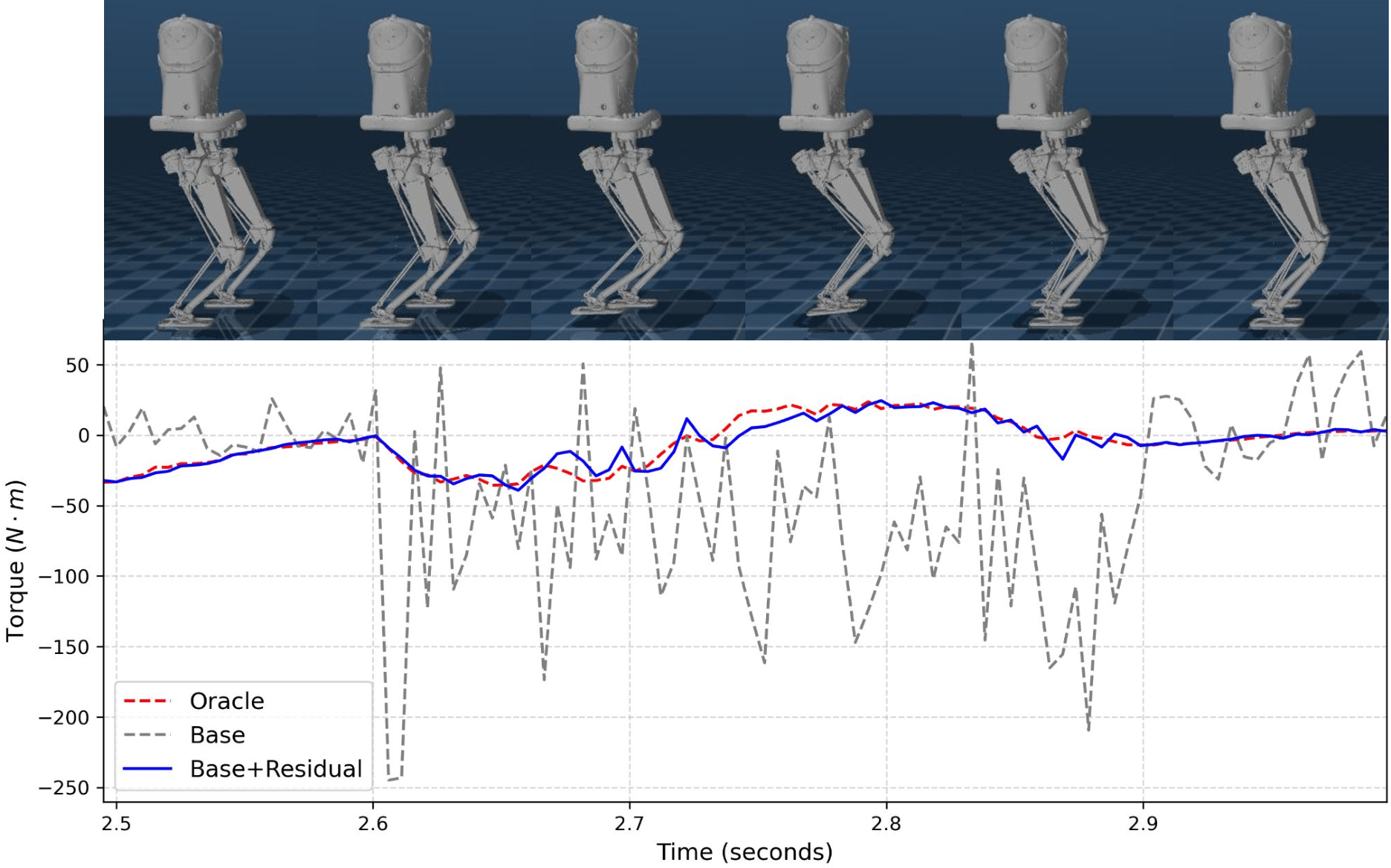
В рамках предложенного подхода вводится понятие “остаточной политики” (residual policy) — это обученная корректировка, применяемая поверх базового контроллера, основанного на модели. Основная цель — компенсировать неточности, присущие модели, используемой в базовом контроллере. Остаточная политика фактически предсказывает разницу между выходом базового контроллера и желаемым результатом, и корректирует выход таким образом, чтобы минимизировать эту разницу. Данный подход позволяет улучшить общую точность и надежность системы управления, не требуя полной переработки или замены базовой модели.
Обучение корректирующей политики осуществляется посредством комбинации обучения с учителем и глубокого обучения с подкреплением. Для генерации идеальных корректирующих действий используется так называемая “оракульная политика” — предварительно обученная модель, предоставляющая эталонные значения. Обучение с учителем применяется для инициализации политики на основе данных, полученных от оракульной политики, в то время как глубокое обучение с подкреплением позволяет ей адаптироваться и улучшать свои корректирующие действия в процессе взаимодействия со средой, повышая точность и надежность системы управления.
Остаточная политика обучается предсказывать и компенсировать ошибки, возникающие в выходных данных базового контроллера, что повышает его устойчивость и точность. Обучение происходит путем анализа расхождений между прогнозируемым состоянием и фактическим состоянием системы, после чего политика генерирует корректирующие действия для минимизации этих расхождений. Эффективно, остаточная политика выступает в роли адаптивного фильтра, корректирующего выходные данные базового контроллера в реальном времени, что позволяет системе функционировать более надежно в условиях неточностей модели и внешних возмущений. Такой подход позволяет улучшить общую производительность системы, не требуя полной переработки базового контроллера.
Надежность в Реальном Мире: Симуляция и Валидация
В процессе обучения применялась методика доменной рандомизации, заключающаяся в намеренном варьировании параметров симуляции. Политика остаточного управления подвергалась воздействию широкого спектра виртуальных сред и условий, включая изменения в трении поверхности, массе робота и внешних возмущениях. Этот подход позволил значительно повысить способность модели к обобщению, то есть к успешной адаптации к реальным условиям, отличающимся от тех, в которых она была изначально обучена. Создание разнообразного симуляционного окружения стимулировало развитие устойчивости к непредсказуемым факторам, что критически важно для надежной работы робота в реальном мире.
Эффективность предложенного подхода была подтверждена на различных роботизированных платформах, включая Unitree H1-2, Bruce и Kangaroo. В ходе экспериментов удалось достичь 100% успешности выполнения задач на каждой из указанных систем. Это демонстрирует высокую адаптивность и обобщающую способность разработанного алгоритма управления, позволяя ему эффективно функционировать вне зависимости от конкретной аппаратной реализации робота. Такой результат свидетельствует о потенциале использования данной методики для широкого спектра роботизированных устройств и задач, требующих надежного и универсального управления.
Исследования показали значительное улучшение ключевых показателей производительности благодаря предложенному подходу. В частности, наблюдается существенный рост процента успешных попыток, снижение ошибки отслеживания центра масс (DCM) и повышение точности отслеживания положения опорных точек. Полученные результаты демонстрируют, что разработанная система достигает уровня производительности, сопоставимого с “оракулом” — идеальным контроллером, — при этом требуя всего 4,16 часа (1500 эпизодов) симуляции для достижения более чем 80%-го успеха. Это свидетельствует о высокой эффективности предложенного метода и его потенциале для практического применения в робототехнике.
Исследования показали, что предложенный метод демонстрирует превосходство над обучением с имитацией на неровной местности. В отличие от обучения с имитацией, которое ограничено способностью «оракула» (экспертного контроллера) предвидеть неровности рельефа, данная разработка проявляет адаптивное поведение, выходящее за рамки простого копирования. Способность системы к обучению в разнообразных симулированных средах позволяет ей эффективно реагировать на неожиданные изменения в ландшафте, обеспечивая стабильное передвижение даже при наличии препятствий и неровностей, что делает её более надежной и универсальной в реальных условиях эксплуатации.

Наблюдатель отмечает, что стремление к созданию устойчивых систем локомоции для гуманоидных роботов, описанное в статье, неизбежно сталкивается с прагматикой реализации. Авторы предлагают подход, сочетающий обучение с подкреплением и управляемое моделью обучение, стремясь к повышению эффективности и надёжности. Однако, опыт подсказывает, что даже самые изящные алгоритмы рано или поздно требуют компромиссов при внедрении в реальные условия. Как заметил Алан Тьюринг: «Мы можем только надеяться на то, что машины не станут слишком умными». В контексте данной работы, эта фраза напоминает о необходимости баланса между теоретической элегантностью и практической устойчивостью, особенно учитывая неизбежные погрешности и шумы, возникающие в реальном мире робототехники. Все эти «доменные разбросы» — лишь новая упаковка старых проблем.
Что дальше?
Представленная работа, безусловно, элегантна в своей попытке примирить модельно-ориентированный контроль и обучение с подкреплением. Однако, история показывает, что любое «обучение» рано или поздно сталкивается с реальностью. Всё это выглядит многообещающе в симуляции, но производственный цех всегда найдет способ заставить даже самый изящный алгоритм споткнуться о непредсказуемость реального мира. Вопрос не в том, научится ли робот ходить, а в том, сколько ресурсов потребуется, чтобы поддерживать иллюзию надежности в условиях износа механизмов и вариативности окружающей среды.
Вполне вероятно, что фокус сместится в сторону более эффективных методов доменной рандомизации — не просто случайных изменений, а осознанного моделирования наиболее вероятных сценариев отказа. Или же, возможно, придется вернуться к более простым решениям. Иногда монолитный контроллер, пусть и менее «умный», оказывается надежнее, чем сотня микросервисов, каждый из которых лжёт по-своему. Проблема не в алгоритме, а в сложности его внедрения и поддержки.
В конечном итоге, вся эта гонка за «робастностью» напоминает попытку построить неуязвимую крепость. Всегда найдется лазейка, всегда найдется способ обойти защиту. Поэтому, вместо того чтобы стремиться к идеальному решению, возможно, стоит сосредоточиться на разработке систем, способных быстро адаптироваться к неизбежным ошибкам. Ведь в конечном счёте, даже самый «умный» робот — это всего лишь сложный механизм, подверженный старению и поломкам.
Оригинал статьи: https://arxiv.org/pdf/2601.16109.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Будущее SOL: прогноз цен на криптовалюту SOL
- ТГК-14 акции прогноз. Цена TGKN
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- ТГК-1 акции прогноз. Цена TGKA
- Ethereum Is Up 30% But Shorts Refuse to Let Go – The Last Time This Setup Didn’t End Quietly
- Татнефть префы прогноз. Цена TATNP
- Управление рисками в условиях неопределенности: современные подходы
- Whoosh акции прогноз. Цена WUSH
2026-01-24 09:50