Автор: Денис Аветисян
Новый подход к объединению языковых моделей позволяет значительно снизить затраты на обучение и поддержку, не уступая в производительности традиционным методам.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал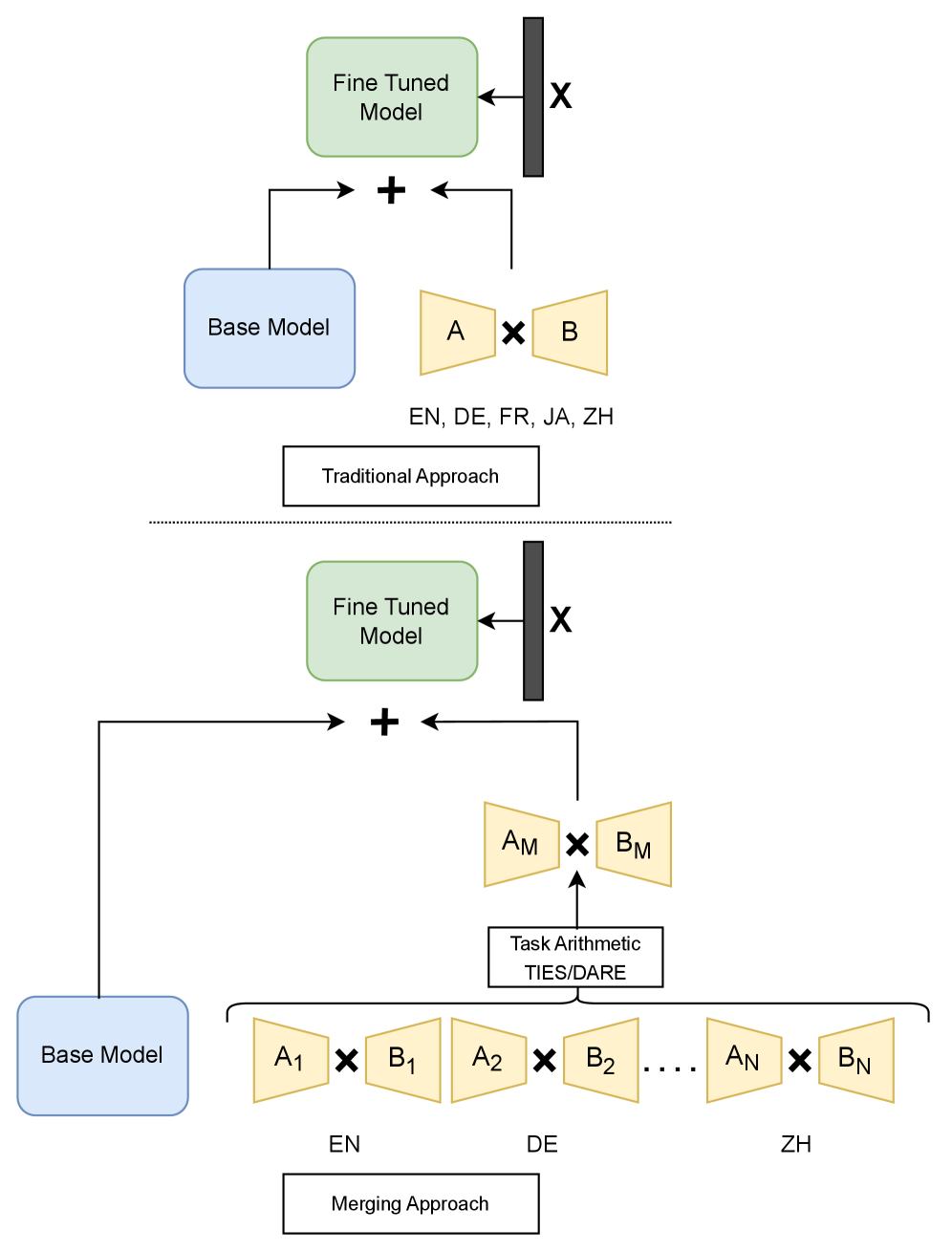
Исследование демонстрирует, что объединение языково-специфичных моделей — эффективная альтернатива полной переподготовке многоязычных систем, обеспечивающая сопоставимые результаты с существенной экономией вычислительных ресурсов.
Обучение и поддержка многоязычных больших языковых моделей (LLM) традиционно связаны со значительными вычислительными затратами и сложностями. В работе ‘Improving Training Efficiency and Reducing Maintenance Costs via Language Specific Model Merging’ предложен альтернативный подход, основанный на слиянии языко-специфических моделей, позволяющий повысить эффективность обучения и снизить издержки поддержки. Показано, что предложенный метод позволяет сократить время первоначального обучения до 50% и более чем на 60% снизить затраты на обновление отдельных языков по сравнению с переобучением всей модели. Открывает ли это новые перспективы для масштабирования и адаптации многоязычных LLM в реальных промышленных задачах?
Вызовы масштабирования многоязычных моделей
Крупномасштабные языковые модели, такие как Llama-3.1-8b-Instruct, стали основой для решения широкого спектра задач в области обработки естественного языка. Однако расширение их возможностей для поддержки множества языков сопряжено со значительными вычислительными затратами. Обучение модели с нуля для каждого нового языка требует огромных ресурсов, включая время, энергию и вычислительные мощности. Этот процесс быстро становится непрактичным по мере увеличения количества поддерживаемых языков, представляя собой серьезную проблему для создания по-настоящему глобальных и многоязычных систем искусственного интеллекта. Необходимость в более эффективных подходах к масштабированию многоязыковых моделей становится все более очевидной, чтобы обеспечить доступность и широкое применение этих технологий.
Традиционный подход к расширению языковой поддержки больших языковых моделей, предполагающий полную переподготовку модели для каждого нового языка, быстро становится непрактичным по мере увеличения их числа. При добавлении даже нескольких дополнительных языков вычислительные затраты и время обучения растут экспоненциально, что делает этот метод крайне ресурсоемким и неэффективным для создания действительно многоязычных систем. По мере увеличения количества языков, необходимых для поддержки, полный пересмотр параметров модели для каждого из них становится непосильной задачей, требующей огромных вычислительных мощностей и значительных временных затрат, что препятствует дальнейшему масштабированию и широкому внедрению многоязычных моделей.
В связи с возрастающими вычислительными затратами при масштабировании больших языковых моделей на множество языков, возникает необходимость в разработке более эффективных методов адаптации, не связанных с простым увеличением размера модели. Предлагаемая стратегия “обучи один раз, объединяй по мере необходимости” представляет собой перспективное решение, направленное на значительное сокращение времени обучения — до 35%. Вместо повторного обучения всей модели для каждого нового языка, этот подход предполагает извлечение и объединение специфичных для языка знаний в уже обученную базовую модель. Это позволяет существенно снизить вычислительную нагрузку и время, затрачиваемое на адаптацию, открывая возможности для создания действительно многоязычных систем обработки естественного языка, доступных для широкого круга пользователей и приложений.
Объединение моделей: более эффективный подход
Объединение моделей представляет собой перспективное решение, позволяющее комбинировать независимо обученные модели без необходимости полной переподготовки. Этот подход заключается в агрегации весов существующих моделей, что существенно снижает вычислительные затраты и время, требуемое для адаптации к новым задачам или языкам. Вместо трудоемкого процесса обучения с нуля, объединение моделей позволяет использовать уже полученные знания, что особенно актуально в условиях ограниченных ресурсов или при необходимости быстрой адаптации к изменяющимся требованиям.
Существуют различные методы объединения весов моделей, такие как TIES, KnOTS и DARE, каждый из которых обладает своими особенностями. TIES (Task Interpolation via Embedding Space) фокусируется на интерполяции весов в пространстве эмбеддингов, что позволяет эффективно переносить знания между моделями. KnOTS (Knowledge-based Neural Overlap Transfer) использует информацию о перекрытии знаний между задачами для взвешивания вклада каждой модели. DARE (Drop And REscale) предполагает отбрасывание некоторых параметров и перемасштабирование оставшихся, что способствует снижению вычислительных затрат и улучшению обобщающей способности. Выбор конкретного метода зависит от характеристик объединяемых моделей и целевой задачи.
Метод объединения моделей предоставляет значительную экономию вычислительных ресурсов и ускоряет адаптацию к новым языкам в многоязычной обработке естественного языка. В частности, при обслуживании моделей и переобучении адаптеров, объединение моделей позволяет снизить затраты до 70% по сравнению с полным переобучением. Это достигается за счет использования знаний, уже содержащихся в предварительно обученных моделях, вместо необходимости обучения с нуля для каждого нового языка или задачи.
Эмпирическое подтверждение: производительность в различных задачах
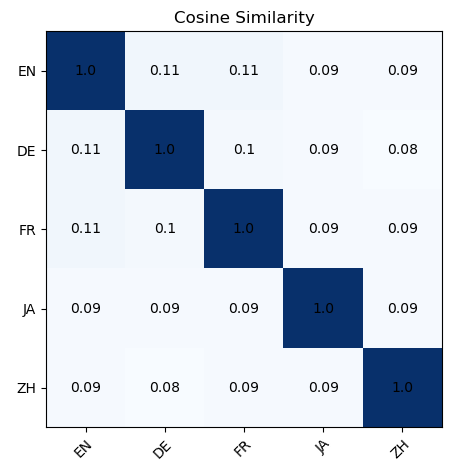
Эксперименты показали эффективность объединения моделей при решении задач анализа тональности, здравого смысла и суммаризации текста. Для анализа тональности использовался датасет MultilingualSentiment, для оценки способности к здравому смыслу — mCSQA, а для суммаризации — WikiLingua. Объединение моделей демонстрирует работоспособность на различных лингвистических задачах и позволяет достичь результатов, сопоставимых с традиционными методами тонкой настройки (fine-tuning) моделей.
Для всесторонней оценки эффективности модели объединения использовался набор метрик, отражающих различные аспекты качества генерации и классификации текста. Для задач анализа тональности применялась метрика Macro-Average F1-Score, позволяющая оценить сбалансированность между точностью и полнотой для каждого класса. В задачах логического вывода использовалась Multi-Class Accuracy, измеряющая долю правильно классифицированных примеров. Качество генерируемых текстов, например, в задачах суммаризации, оценивалось с помощью метрик ROUGE-1 и ROUGE-L, измеряющих перекрытие униграмм и наиболее длинных общих подпоследовательностей между сгенерированным и эталонным текстом. Для более детальной оценки качества генерируемого текста, особенно с точки зрения семантической близости к эталону, также использовалась метрика Bert-Score, основанная на контекстуализированных векторных представлениях слов.
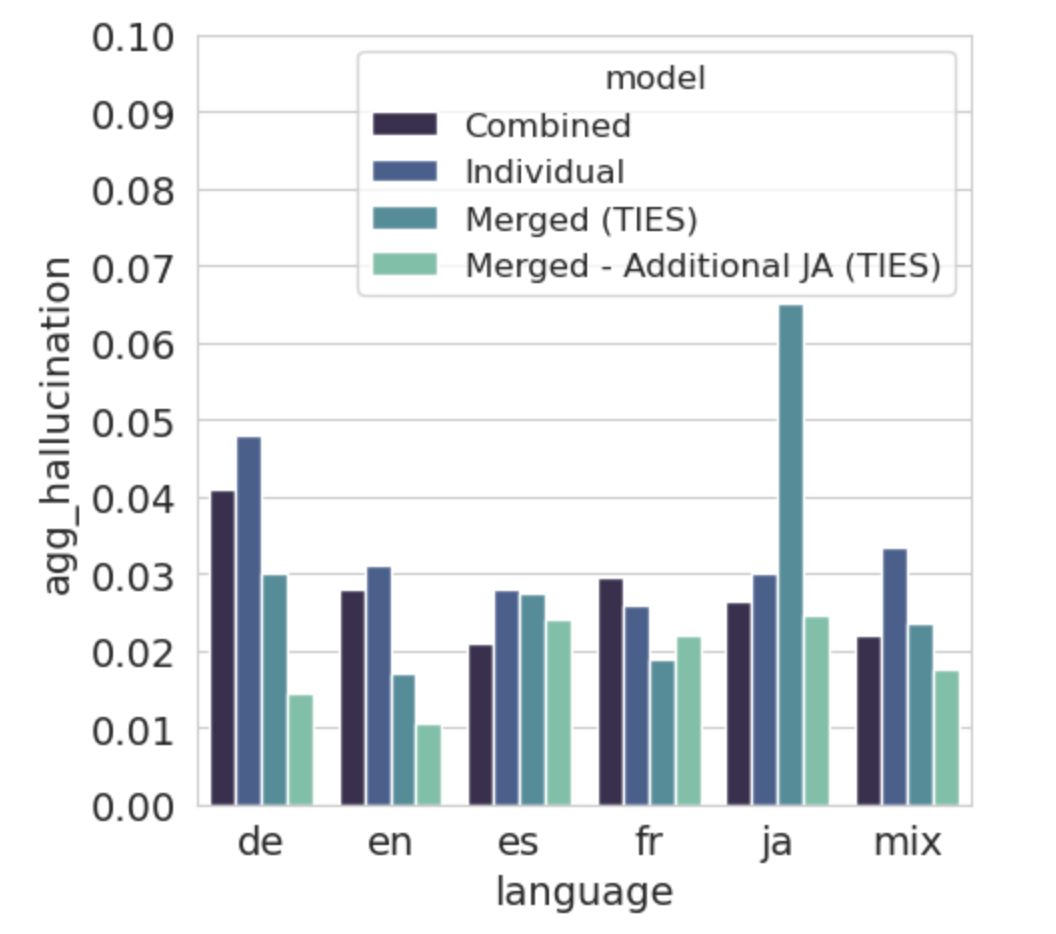
Экспериментальные данные демонстрируют, что объединение моделей достигает сопоставимой производительности с традиционными методами дообучения на задачах анализа тональности, логического вывода и суммаризации текстов. В частности, при суммаризации текстов на английском, японском и китайском языках, использование объединенных моделей показало улучшение метрики BertScore на 0.1-0.6%. Модель TIES (плотность=0.5) продемонстрировала повышение точности на 0.5% в задачах, требующих логического вывода, а максимальная разница в значении F1-score для английского языка в задачах анализа тональности составила до 15%.
Многоязычная обработка естественного языка: расширение горизонтов
Объединение моделей открывает новые горизонты для языков с ограниченными ресурсами, позволяя создавать высококачественные приложения обработки естественного языка даже при недостатке данных и вычислительных мощностей. Этот подход, в отличие от традиционного обучения с нуля, использует знания, полученные при обучении на языках с большим объемом данных, и эффективно переносит их на новые языки. Благодаря этому, исследователи и разработчики могут создавать инструменты для анализа текста, машинного перевода и других задач обработки языка для ранее недостаточно поддерживаемых языков, не прибегая к огромным затратам времени и ресурсов. Вместо длительного и дорогостоящего обучения новой модели, объединение существующих позволяет добиться впечатляющих результатов, значительно расширяя доступ к технологиям обработки языка для различных культур и сообществ.
Метод объединения моделей открывает новые возможности для быстрой адаптации к различным языкам, включая такие распространенные, как английский, французский, немецкий, китайский и японский. Этот подход позволяет значительно расширить охват технологий обработки естественного языка, делая их доступными для большего числа пользователей по всему миру. Благодаря сокращению времени и ресурсов, необходимых для обучения моделей, обеспечивается более широкое включение языков с ограниченными ресурсами в сферу NLP, что способствует большей лингвистической инклюзивности и предоставляет равные возможности для доступа к информации и технологиям на родном языке.
Применение метода объединения моделей демонстрирует значительный вклад в устойчивое развитие искусственного интеллекта. Данный подход позволяет существенно снизить негативное воздействие на окружающую среду, связанное с обучением масштабных языковых моделей. Исследования показывают, что объединение моделей может сократить время обучения до 35%, что, в свою очередь, приводит к существенной экономии вычислительных ресурсов и снижению энергопотребления. Такая оптимизация не только делает разработку и использование NLP-технологий более доступной, но и способствует уменьшению углеродного следа, что особенно важно в контексте глобальных экологических проблем и стремления к ответственному развитию искусственного интеллекта.
Исследование, представленное в статье, демонстрирует, что объединение языковых моделей представляет собой эффективный подход к поддержанию многоязычных систем. Это позволяет избежать дорогостоящего и длительного процесса переобучения всей модели при внесении изменений или адаптации к новым данным. Как однажды заметил Джон фон Нейманн: «В науке нет места для предрассудков, только для логики». В данном случае, логика подсказывает, что разумное использование существующих ресурсов, таких как адаптация и объединение моделей, ведет к оптимизации и повышению устойчивости системы. Это особенно важно в контексте постоянного развития языковых моделей и необходимости минимизации затрат на их поддержание, что, в свою очередь, способствует зрелости всей системы.
Что дальше?
Представленная работа демонстрирует, что объединение языковых моделей — это не столько решение, сколько временное снижение энтропии. Стабильность, достигнутая за счёт специализированного слияния, — иллюзия, закешированная временем. Любая многоязыковая система неизбежно подвержена дрейфу, и вопрос лишь в том, как долго удастся поддерживать её работоспособность без полного переобучения. Утверждение о снижении затрат на обслуживание — это, скорее, отсрочка неизбежного, подобно оплате процентов по кредиту вместо его погашения.
Будущие исследования, вероятно, сосредоточатся на автоматизации процесса слияния моделей и адаптации к новым языкам без существенной потери производительности. Однако, истинный вызов заключается не в оптимизации текущих методов, а в поиске принципиально новых подходов к построению многоязыковых систем, способных к самовосстановлению и адаптации к изменяющимся условиям. Задержка — это налог, который платит каждый запрос, и этот налог будет расти по мере увеличения сложности систем.
В конечном счете, любая система стареет — вопрос лишь в том, делает ли она это достойно. Попытки замедлить этот процесс — это, по сути, борьба с течением времени, обреченная на провал. Истинная ценность заключается в понимании этой неизбежности и в создании систем, способных к элегантному угасанию, а не к болезненному коллапсу.
Оригинал статьи: https://arxiv.org/pdf/2601.16127.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Будущее SOL: прогноз цен на криптовалюту SOL
- ТГК-14 акции прогноз. Цена TGKN
- ТГК-1 акции прогноз. Цена TGKA
- Татнефть префы прогноз. Цена TATNP
- Whoosh акции прогноз. Цена WUSH
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- Крипто-рынок: Bitcoin растет, WLFI в кризисе: Обзор главных событий недели (02.05.2026 10:45)
- Управление рисками в условиях неопределенности: современные подходы
2026-01-25 11:06