Автор: Денис Аветисян
Новое исследование выявляет опасную тенденцию в обучении больших языковых моделей с использованием обратной связи от человека, когда стремление к точности приводит к потере разнообразия и снижению эффективности.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
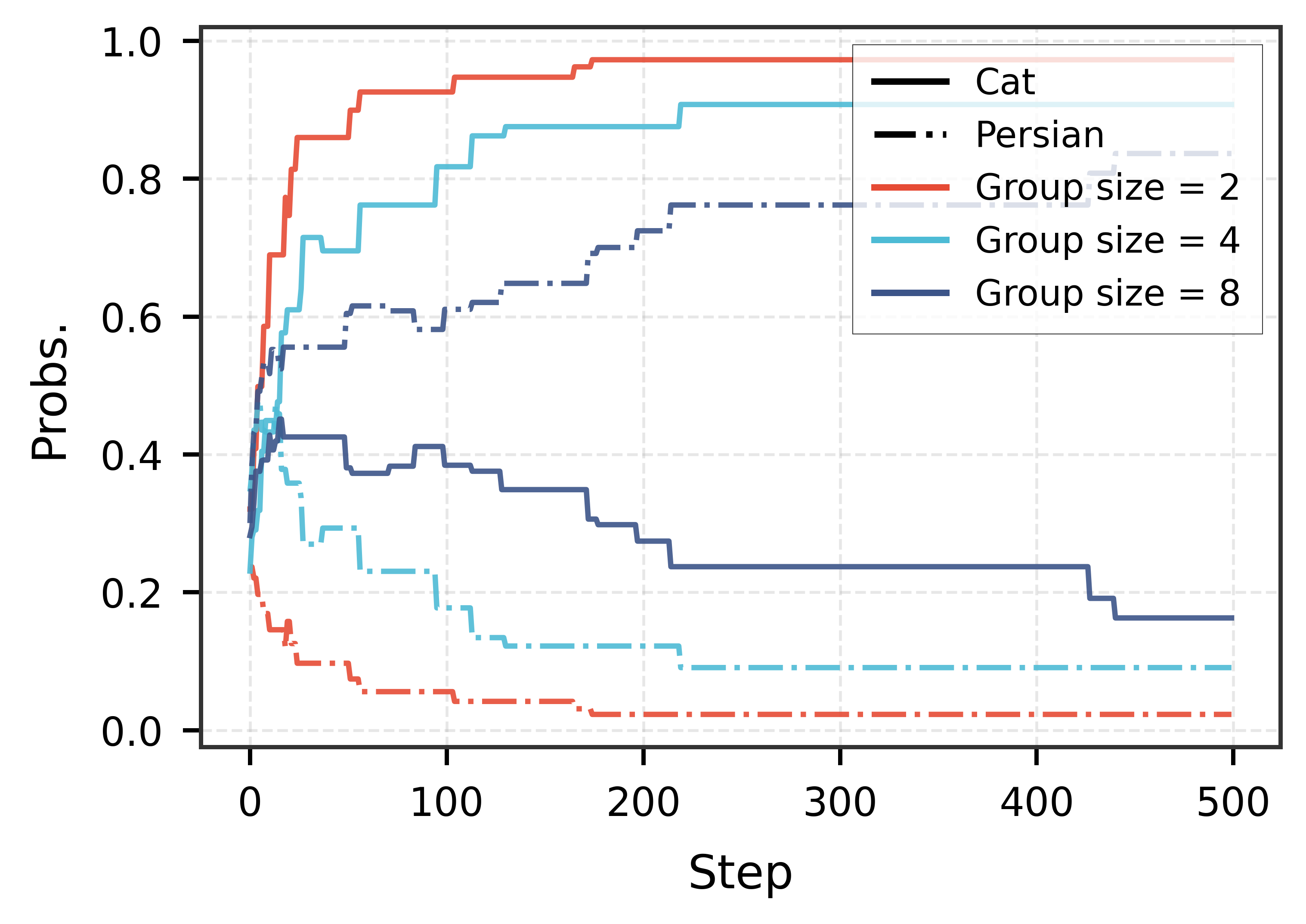
Бесплатный Телеграм канал![Семантическая связь ускоряет ухудшение обобщающей способности модели: при обучении исключительно на персидском языке, более сильная семантическая связь и увеличение размера групп приводят к более быстрому снижению точности распознавания элементов из невидимой сиамской категории, демонстрируя, что [latex] \text{accuracy} \propto \frac{1}{\text{semantic coupling} \times \text{group size}} [/latex].](https://arxiv.org/html/2601.15609v1/imgs/semantic.png)
Работа посвящена анализу и решению проблемы ‘переобучения’ в Reinforcement Learning from Human Feedback (RLHF), предлагая методы калибровки для поддержания баланса между уверенностью и исследованием.
Несмотря на эмпирический успех обучения с подкреплением с проверяемыми наградами (RLVR), остаётся неясным, действительно ли этот подход раскрывает новые возможности или лишь усиливает существующие знания в больших языковых моделях. В работе ‘When Sharpening Becomes Collapse: Sampling Bias and Semantic Coupling in RL with Verifiable Rewards’ исследуется феномен “перезаточки” — коллапса политики на ограниченном множестве режимов, подавляющего допустимые альтернативы. Авторы показали, что обновления в конечных пакетах данных изначально смещают обучение в сторону выбранных режимов, и этот коллапс распространяется глобально посредством семантической связи. Возможно ли разработать стратегии калибровки, которые эффективно улучшат обобщающую способность моделей и позволят найти баланс между уверенностью и исследованием?
Глубина Рассуждений в Больших Языковых Моделях
Современные большие языковые модели демонстрируют впечатляющую способность к распознаванию закономерностей в огромных массивах данных, что позволяет им генерировать текст, имитирующий человеческую речь. Однако, эта сила основана преимущественно на статистическом анализе и сопоставлении, а не на глубоком понимании причинно-следственных связей. В результате, при решении задач, требующих последовательного применения логики и многоступенчатого рассуждения, модели часто сталкиваются с трудностями. Они могут успешно справляться с простыми вопросами, но оказываются неспособными к решению сложных проблем, требующих анализа информации, выявления скрытых связей и построения логических выводов, что ограничивает их применение в областях, требующих критического мышления и интеллектуального анализа.
Несмотря на значительное увеличение масштаба языковых моделей, простое наращивание их размера не гарантирует улучшения способности к рассуждению. Напротив, это зачастую усугубляет существующие проблемы, такие как склонность к «галлюцинациям» — генерации неправдоподобной или противоречивой информации — и повышенная чувствительность к незначительным изменениям в формулировках запросов. Исследования показывают, что модели, обученные на огромных объемах данных, могут выдавать убедительные, но совершенно нелогичные ответы, особенно в задачах, требующих многоступенчатого анализа. Увеличение размера модели, без одновременного совершенствования архитектуры и методов обучения, приводит к запоминанию статистических закономерностей, а не к развитию истинного понимания и способности к абстрактному мышлению, что делает их уязвимыми к манипуляциям и ненадёжными в сложных ситуациях.
Традиционные методы дообучения и промптинга, ранее демонстрировавшие эффективность в улучшении производительности больших языковых моделей, постепенно достигают своего предела в раскрытии истинных способностей к рассуждению. Несмотря на значительные усилия, направленные на оптимизацию этих подходов, наблюдается, что дальнейшее увеличение объема данных для обучения или усложнение конструкций запросов не всегда приводит к существенному прогрессу в решении сложных, многоступенчатых задач. Модели, хоть и способны генерировать правдоподобные тексты, часто демонстрируют неспособность к логическому выводу, требующему анализа взаимосвязей и применения абстрактного мышления. Это указывает на необходимость разработки принципиально новых подходов, выходящих за рамки простого масштабирования и оптимизации существующих методов, для достижения подлинного прогресса в области искусственного интеллекта.
Калибровка Обучения для Устойчивости Модели
Калибровка с использованием обратной оценки успешности (Inverse-Success Advantage Calibration, IAC) решает проблему чрезмерной заостренности (over-sharpening) в процессе обучения больших языковых моделей. Метод заключается в корректировке сигналов обучения на основе сложности запроса. В частности, IAC снижает вес сигналов от примеров, которые модель легко решает, и усиливает вес сигналов от более сложных примеров. Это предотвращает запоминание моделью конкретных обучающих экземпляров и способствует обобщению на новые, ранее не встречавшиеся данные, уменьшая склонность к переобучению и повышая устойчивость к враждебным атакам.
Калибровка на уровне распределения (Distribution-Level Calibration, DLC) использует сеть памяти для формирования распределения выборки, что позволяет поощрять исследование разнообразных путей рассуждений и предотвращать коллапс распределения. В основе DLC лежит механизм, который динамически корректирует вероятности выбора токенов, основываясь на информации, хранящейся в сети памяти о предыдущих шагах генерации. Это позволяет модели избегать зацикливания на доминирующих путях и исследовать менее вероятные, но потенциально полезные альтернативы, что способствует повышению устойчивости и обобщающей способности языковой модели. Сеть памяти функционирует как буфер, сохраняющий информацию о прошлых состояниях и позволяющий модели учитывать более широкий контекст при принятии решений о выборке.
Применение методов калибровки, таких как Inverse-Success Advantage Calibration (IAC) и Distribution-Level Calibration (DLC), представляет собой перспективный подход к повышению обобщающей способности и устойчивости больших языковых моделей (LLM) к враждебным воздействиям. Эти техники позволяют смягчить переобучение и предотвратить заучивание конкретных примеров, что особенно важно при работе с данными, содержащими предвзятости или намеренные искажения. Улучшение калибровки способствует более надежной работе моделей в условиях, отличных от тренировочных, и повышает их устойчивость к незнакомым или специально сконструированным входным данным, снижая вероятность генерации некорректных или предвзятых ответов.
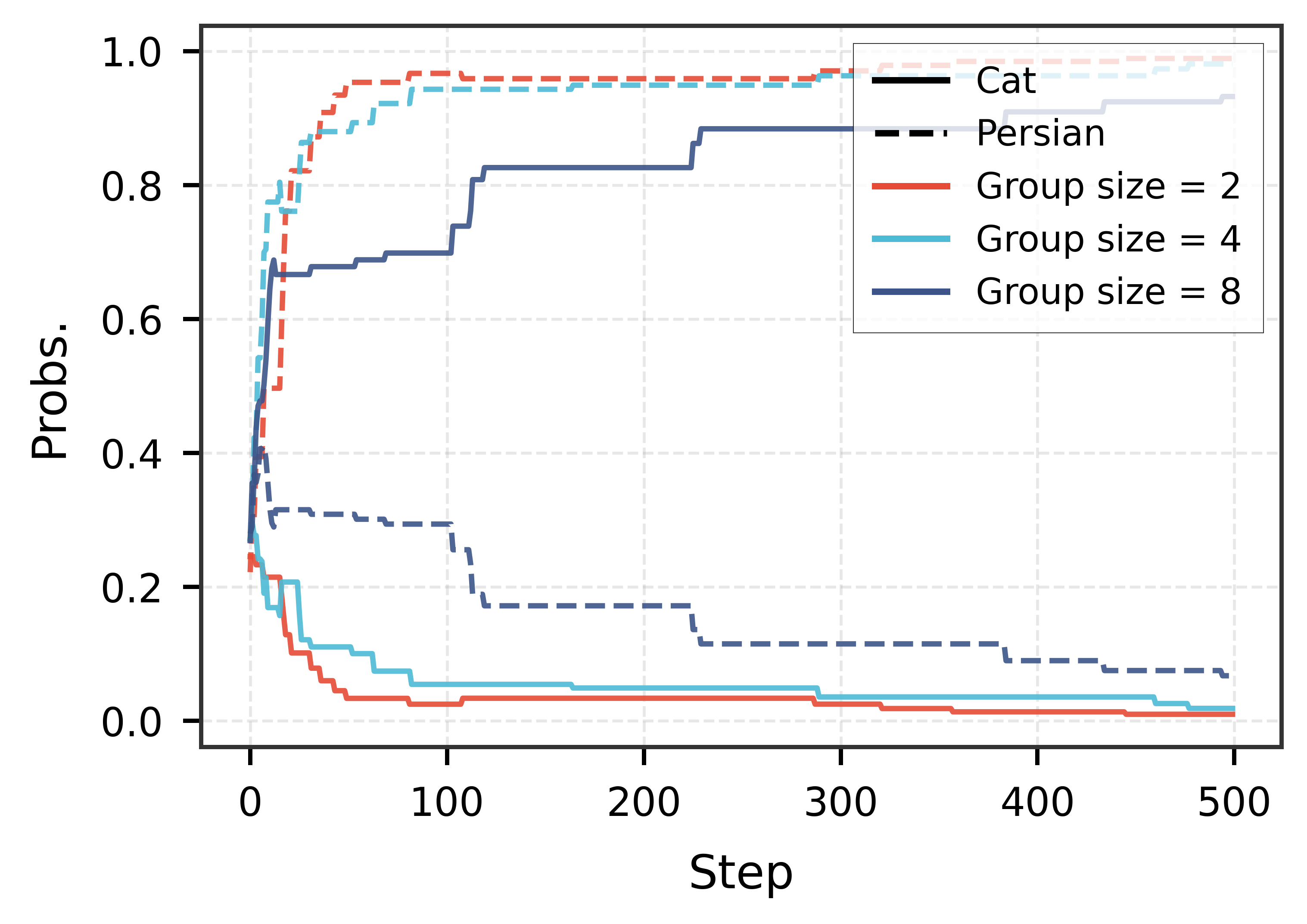
![Применение предложенных нами методов смягчения к примеру Softmax показало, что калибровка преимуществ с использованием обратной успешности замедляет коллапс, а калибровка на уровне распределений с помощью нейронной сети памяти ([latex]\mu=0.5[/latex]) полностью останавливает коллапс и поддерживает разнообразие даже при агрессивных обновлениях AdamW.](https://arxiv.org/html/2601.15609v1/imgs/all_adam.png)
Борьба с Коллапсом Распределения и Снижением Энтропии
Феномен “коллапса распределения” (Distributional Collapse) представляет собой серьезное препятствие для достижения надежного и обоснованного поведения модели. Он характеризуется чрезмерной концентрацией выходных данных, когда модель начинает выдавать узкий спектр ответов, игнорируя другие возможные варианты. Это приводит к снижению способности модели к обобщению и решению разнообразных задач, поскольку она теряет способность исследовать пространство решений и адаптироваться к новым условиям. Ограниченность выходных данных существенно ухудшает качество рассуждений и препятствует достижению желаемого уровня производительности в сложных сценариях.
Феномен коллапса распределения часто обусловлен такими факторами, как семантическая связанность и смещение выборки в процессе обучения. Семантическая связанность возникает, когда модель чрезмерно полагается на небольшое подмножество семантически связанных токенов, что приводит к предсказуемым и однообразным ответам. Смещение выборки, возникающее из-за неравномерного представления данных в обучающем наборе, усиливает эту проблему, заставляя модель отдавать предпочтение определенным шаблонам и ограничивая разнообразие генерируемых ответов. В результате, модель становится менее способной к генерации разнообразных и креативных текстов, что негативно сказывается на ее общей производительности и способности к обобщению.
Методы, такие как регуляризация Kullback-Leibler (KL) и описанные ранее методы калибровки, активно противодействуют коллапсу распределения и снижению энтропии, стимулируя более исследовательское поведение модели. Регуляризация KL добавляет штраф к расхождению между распределением вероятностей, генерируемым моделью, и целевым распределением, предотвращая чрезмерную концентрацию выходных данных. Калибровка, в свою очередь, корректирует оценку преимущества и распределение выборки, обеспечивая более широкое разнообразие генерируемых ответов. Практическая реализация этих методов демонстрирует стабилизацию энтропии политики в диапазоне 0.20-0.24, что значительно выше значения 0.08, наблюдаемого при использовании только DAPO.
Эффективное обучение моделей требует тщательной оптимизации, включающей в себя использование алгоритмов, таких как AdamW, и точную настройку размера пакета (Batch Size) для градиентного спуска. AdamW, являясь вариантом Adam, включает в себя коррекцию веса, предотвращая переобучение и улучшая обобщающую способность модели. Размер пакета напрямую влияет на скорость сходимости и стабильность обучения: слишком большой пакет может привести к неточным оценкам градиента, в то время как слишком маленький — к нестабильности и медленной сходимости. Оптимальный размер пакета подбирается эмпирически, учитывая специфику задачи и архитектуру модели, и часто требует проведения серии экспериментов для достижения наилучших результатов.
Калибровка оценки преимущества и распределения выборки демонстрирует улучшенную обобщающую способность и поддержание разнообразия генерируемых ответов. В ходе экспериментов удалось стабилизировать энтропию политики в диапазоне 0.20-0.24, что значительно превышает значение 0.08, полученное при использовании только метода DAPO. Данный результат указывает на эффективность предложенного подхода в предотвращении коллапса распределения и увеличении вероятности генерации разнообразных и релевантных ответов, что является критически важным для надежного функционирования модели.
Специализация Языковых Моделей с Верифицируемыми Наградами
Метод обучения с подкреплением и проверяемыми наградами (RLVR) представляет собой новую структуру для специализации больших языковых моделей (LLM) в областях, где точность ответа может быть объективно проверена. В отличие от традиционных подходов, ориентированных на достижение высокой лингвистической беглости, RLVR позволяет LLM развивать навыки, необходимые для решения задач, требующих не только генерации текста, но и подтверждаемого рассуждения. Эта методика позволяет модели сосредотачиваться на корректности и обоснованности своих ответов, что особенно важно в таких сферах, как математика, логика и научные исследования, где важна не только формальная правильность, но и соответствие фактическим данным и принципам. В результате, LLM, обученные с использованием RLVR, способны не просто имитировать интеллектуальное поведение, но и демонстрировать подлинное понимание и способность к решению проблем.
Метод обучения с подкреплением и проверяемыми наградами (RLVR) активно использует формирование наград для целенаправленного управления процессом обучения языковых моделей. Вместо простого поощрения за беглость речи, RLVR фокусируется на вознаграждении за точность и возможность проверки рассуждений. Это достигается путем разработки системы наград, которая оценивает не только конечное решение, но и логическую последовательность шагов, приводящих к нему. Таким образом, модель стимулируется к построению обоснованных и верифицируемых цепочек рассуждений, что существенно повышает её надежность и точность в областях, где требуется достоверность информации. Использование подобного подхода позволяет создавать искусственный интеллект, способный не только генерировать текст, но и подтверждать его правильность.
В ходе применения предложенных методов специализации больших языковых моделей с использованием проверяемых вознаграждений, достигнуты значительные результаты на бенчмарке Math500. Модель продемонстрировала средний балл AVG@8, равный 71.15, и процент успешных решений PASS@8, составивший 78.81. Данные показатели свидетельствуют о высокой эффективности разработанного подхода в обучении моделей точным математическим рассуждениям и проверке корректности получаемых решений, что открывает перспективы для создания надежных и заслуживающих доверия систем искусственного интеллекта, способных решать сложные задачи в области математики и логики.
Исследования показали, что оптимальная сила калибровки, обозначенная значением α=1, обеспечивает максимальную производительность модели в последующих задачах. Этот параметр, регулирующий степень уверенности модели в своих ответах, оказался ключевым фактором для достижения наилучших результатов. При значении α=1, модель демонстрирует сбалансированный подход между уверенностью и точностью, избегая как излишней самоуверенности в неверных ответах, так и чрезмерной неуверенности, препятствующей эффективному решению задач. Данный результат подчеркивает важность точной настройки параметров калибровки для создания надежных и эффективных языковых моделей, способных демонстрировать высокую производительность в различных областях применения.
Разработанный подход открывает возможности для создания больших языковых моделей (LLM), которые отличаются не только высокой производительностью, но и подтвержденной надежностью в конкретных областях применения. Вместо простого достижения беглости речи, данный метод позволяет обучать модели, способные демонстрировать точные и проверяемые рассуждения. Это достигается за счет использования обучения с подкреплением и четко определенных, верифицируемых наград, что гарантирует приоритет корректности и обоснованности ответов. В результате, создаваемые LLM способны не только генерировать текст, но и предоставлять доказательства своей правоты, что особенно важно в критически важных сферах, таких как математика, логика и научные исследования, где требуется не просто результат, но и гарантия его достоверности.
Сочетание надежных методов обучения и проверяемых наград открывает путь к созданию действительно заслуживающих доверия и ответственных систем искусственного интеллекта. Данный подход позволяет не просто обучать модели, демонстрирующие впечатляющую беглость речи, но и гарантировать, что их рассуждения можно проверить и подтвердить. В отличие от традиционных методов, где оценка качества часто субъективна, использование проверяемых наград обеспечивает объективную метрику прогресса и надежности. Это особенно важно в критически важных областях, где ошибки могут иметь серьезные последствия, таких как медицина, финансы или право. В результате, создаваемые системы не только демонстрируют высокую производительность, но и предоставляют пользователям уверенность в обоснованности и надежности принимаемых ими решений, что является ключевым фактором для широкого внедрения и доверия к искусственному интеллекту.
Исследование, представленное в данной работе, демонстрирует, что без чёткого определения критериев успешности, процесс обучения с подкреплением на основе обратной связи от человека склонен к коллапсу разнообразия. Модель, стремясь к максимальной уверенности в своих ответах, теряет способность исследовать альтернативные решения. Это явление, названное «переобучением», требует пристального внимания к балансу между эксплуатацией и исследованием. Как точно заметил Андрей Колмогоров: «Математика — это искусство невозможного». В контексте RLHF, достижение оптимального баланса между уверенностью и разнообразием требует не менее искусного математического подхода, чем решение сложной теоремы.
Что Дальше?
Наблюдаемое явление «переточки» в обучении с подкреплением на основе обратной связи от человека (RLHF) указывает на фундаментальную проблему: стремление к мгновенной «правильности» часто приводит к потере обобщающей способности. Предложенные методы калибровки, безусловно, представляют собой шаг вперёд, но лишь смягчают симптомы, а не устраняют причину. Истинная элегантность алгоритма не измеряется количеством набранных баллов на текущем наборе тестов, а его способностью сохранять непротиворечивость в условиях изменяющейся неопределенности.
Необходимо отделить метрики «успеха», которые отражают лишь поверхностное соответствие человеческим предпочтениям, от истинной полезности модели. Вопрос в том, как разработать алгоритмы, которые не просто имитируют человеческое поведение, но и способны к самостоятельному исследованию пространства решений, даже если это временно приводит к снижению «рейтинга». Важно помнить, что математическая красота решения не зависит от языка реализации, а лишь от его внутренней логики.
Дальнейшие исследования должны быть сосредоточены на разработке более надёжных метрик диверсификации и методов, которые позволяют модели оценивать не только «вероятность успеха», но и «ценность исследования». В конечном счёте, цель состоит не в том, чтобы создать «идеального имитатора», а в том, чтобы построить систему, способную к самостоятельному обучению и адаптации, даже если это требует отказа от привычных представлений о «правильности».
Оригинал статьи: https://arxiv.org/pdf/2601.15609.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Будущее SOL: прогноз цен на криптовалюту SOL
- ТГК-1 акции прогноз. Цена TGKA
- ТГК-14 акции прогноз. Цена TGKN
- Ethereum: Безупречная работа сети. Shiba Inu: Проблемы ликвидности. Bitcoin: Спекулятивный ралли. (02.05.2026 18:15)
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- Татнефть префы прогноз. Цена TATNP
- Whoosh акции прогноз. Цена WUSH
- Казаньоргсинтез акции прогноз. Цена KZOS
2026-01-26 05:42