Автор: Денис Аветисян
Новый подход к разреженному вниманию позволяет динамически регулировать вычислительные затраты больших языковых моделей во время работы, оптимизируя их производительность для различных задач.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Исследование динамики обучения механизма Elastic Attention выявило, что разделение общей функции потерь на основную языковую модель и регуляризацию разреженности позволяет модели автоматически различать задачи, устойчивые к разреженности (с использованием [latex]\Omega\_{\mathrm{MSR}}[/latex]) и чувствительные к ней, посредством адаптации коэффициентов λ, что демонстрирует принципиально новый подход к оптимизации разреженности в нейронных сетях.](https://arxiv.org/html/2601.17367v1/x23.png)
Представлен метод Elastic Attention, обеспечивающий адаптивное изменение степени разреженности внимания во время инференса для повышения эффективности и снижения вычислительных издержек.
Квадратичная сложность стандартных механизмов внимания становится серьезным препятствием для масштабирования больших языковых моделей (LLM) при работе с длинными контекстами. В статье ‘Elastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers’ предложен новый подход, позволяющий динамически регулировать степень разреженности модели в процессе инференса, адаптируясь к специфике задачи. Ключевой особенностью является интеграция легковесного Attention Router, определяющего режим вычислений для каждой головы внимания, что позволяет добиться высокой производительности и эффективности. Способна ли данная методика открыть путь к созданию LLM, оптимально адаптированных к различным сценариям использования и ресурсам?
Преодолевая Границы: Масштаб и Ограничения Трансформеров
Архитектура Transformer, несмотря на свою мощь в обработке последовательностей, сталкивается с серьезными ограничениями при работе с очень длинными входными данными. Проблема заключается в квадратичной вычислительной сложности механизма внимания: с каждым увеличением длины последовательности, количество необходимых вычислений растет пропорционально квадрату этой длины O(n^2). Это означает, что обработка длинных текстов, например, объемных научных статей или книг, требует экспоненциально возрастающих ресурсов — памяти и времени вычислений. Такая сложность быстро становится препятствием для эффективного анализа больших объемов информации и ограничивает возможности Transformer в задачах, требующих учета контекста на большом расстоянии, например, в долгосрочном прогнозировании или понимании сложных повествований. Поэтому, для решения проблемы длинного контекста, активно разрабатываются новые подходы к механизмам внимания, направленные на снижение вычислительной сложности без потери точности.
Обработка длинных контекстов представляет собой существенное препятствие для современных моделей обработки естественного языка. По мере увеличения объема входной информации, требуемой для анализа, резко возрастают вычислительные затраты и время обработки. Это особенно заметно в задачах, требующих логического вывода, обобщения и понимания взаимосвязей между отдаленными элементами текста. Например, при анализе больших юридических документов или сложных научных статей, модели часто испытывают трудности с удержанием важной информации и установлением связей между различными частями текста, что приводит к снижению точности и эффективности. Ограничения, связанные с обработкой длинных контекстов, препятствуют применению этих моделей в широком спектре задач, где критически важна способность к глубокому пониманию и анализу больших объемов информации.
Традиционные механизмы внимания, являющиеся основой архитектуры Transformer, сталкиваются с серьезными ограничениями при обработке длинных последовательностей данных. Вычислительная сложность, растущая квадратично с увеличением длины входного текста, делает их применение практически невозможным для задач, требующих анализа больших объемов информации. Эта проблема побуждает исследователей к разработке новых подходов, направленных на снижение вычислительных затрат без потери точности. Альтернативные методы, такие как разреженное внимание и различные техники аппроксимации, активно изучаются для обеспечения эффективной обработки длинных контекстов и расширения возможностей Transformer в задачах, требующих глубокого понимания и анализа обширных текстовых данных. Поиск оптимального баланса между вычислительной эффективностью и качеством представления информации остается ключевой задачей в области обработки естественного языка.
Эластичное Внимание: Динамическая Разреженность в Действии
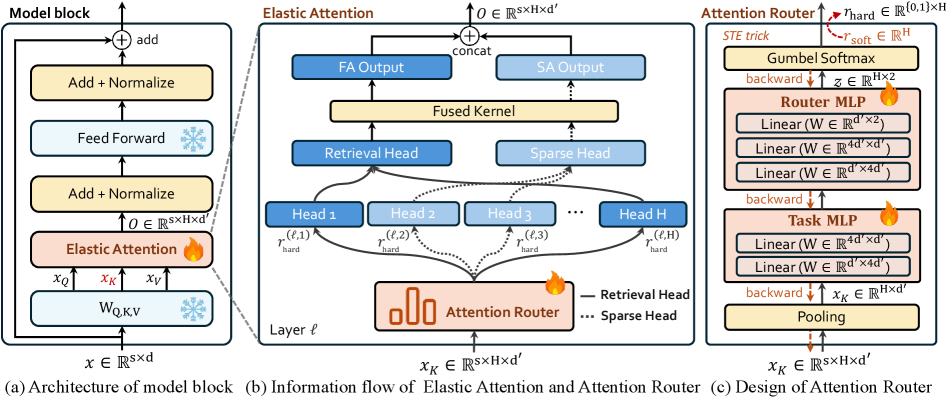
Механизм Elastic Attention представляет собой адаптивную разреженную схему внимания, функционирующую на этапе тестирования. В отличие от статических методов разрежения, Elastic Attention динамически регулирует степень разреженности внимания, основываясь на характеристиках входных данных. Это позволяет модели оптимизировать использование вычислительных ресурсов, фокусируясь на наиболее релевантных частях входной последовательности и избегая ненужных вычислений для менее важных элементов. Изменение степени разреженности происходит автоматически, без необходимости переобучения или ручной настройки, что делает метод гибким и применимым к различным типам входных данных и задачам.
Механизм Elastic Attention реализует динамическую разреженность внимания посредством “Маршрутизатора внимания” (Attention Router), который стратегически переключает отдельные attention heads между режимами полного и разреженного внимания. Этот компонент анализирует входные данные и определяет, какие головы должны обрабатывать информацию в полном объеме для захвата критически важных деталей, а какие могут эффективно работать в разреженном режиме для снижения вычислительной нагрузки и повышения скорости обработки последовательностей. Переключение между режимами происходит на уровне каждой головы внимания, что позволяет модели адаптироваться к специфике каждого входного примера и оптимизировать использование ресурсов.
Механизм Elastic Attention использует так называемые ‘Retrieval Heads’ для повышения эффективности обработки длинных последовательностей. Эти головы внимания предназначены для извлечения релевантной информации из входных данных, что позволяет модели концентрироваться на наиболее значимых частях последовательности. Использование Retrieval Heads приводит к снижению вычислительной сложности по сравнению с полным вниманием, поскольку не все головы внимания обрабатывают всю последовательность. Это, в свою очередь, приводит к ускорению процесса обработки и повышению точности модели, особенно при работе с большими объемами данных и длинными контекстами. Эффективность Retrieval Heads подтверждается экспериментальными данными, демонстрирующими улучшение как скорости, так и качества работы модели.
Оптимизация Разреженности: Методы и Механизмы
Маршрутизатор внимания использует ‘Gumbel-Softmax’ для преобразования дискретных решений о маршрутизации в непрерывные, что позволяет применять градиентные методы оптимизации для управления уровнем разреженности. Вместо жесткого выбора одного маршрута, Gumbel-Softmax вводит случайный шум в процесс принятия решений, создавая вероятностное распределение по всем возможным маршрутам. Это позволяет вычислять градиенты по отношению к параметрам модели, даже когда решения о разреженности являются дискретными, обеспечивая эффективную оптимизацию целевой разреженности и улучшение производительности модели. Фактически, Gumbel-Softmax выступает в роли дифференцируемого приближения к функции argmax, необходимой для выбора оптимального маршрута.
Для обеспечения стабильного и управляемого процесса оптимизации разреженности в механизмах маршрутизации внимания используются множители Лагранжа. Эти множители динамически масштабируют штрафы за отклонение от целевого уровня разреженности. Применение множителей Лагранжа позволяет корректировать штрафные функции в процессе обучения, адаптируясь к текущему состоянию модели и предотвращая чрезмерное или недостаточное сокращение числа активных соединений. Это обеспечивает более плавную и предсказуемую сходимость к желаемому уровню разреженности, избегая резких изменений в структуре модели и поддерживая её производительность. \mathcal{L} = F(x) + \lambda(g(x) - c) , где λ — множитель Лагранжа, F(x) — целевая функция, g(x) — ограничение, а c — целевое значение ограничения.
Для быстрой оценки характера входных данных и формирования начальной конфигурации разреженности используется метод “Boundary Pooling”. Данный подход позволяет модели оперативно определять тип задачи на основе анализа ограниченного контекста. Экспериментально установлено, что оптимальная длина усечения (truncation length) для идентификации задачи составляет 100 токенов. Это означает, что для оценки типа входных данных модель анализирует только первые 100 токенов последовательности, что существенно снижает вычислительные затраты и обеспечивает быстродействие.
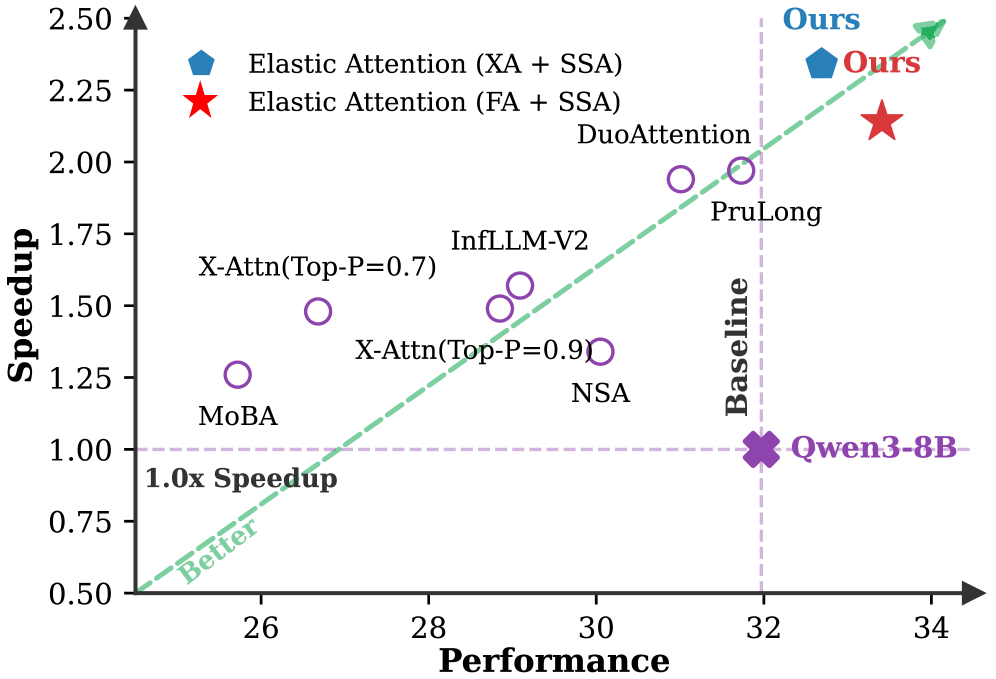
![Сравнительный анализ вариантов Elastic Attention (FA-XA и XA-SSA) с MoBA и NSA на основе модели Llama-3.1-8B-Instruct на бенчмарке RULER (8K-256K) показал, что предложенный метод обеспечивает превосходный баланс между ускорением инференса и [latex] \Omega_{ESR} [/latex], что подтверждается результатами, представленными на графиках (a), (b) и (c).](https://arxiv.org/html/2601.17367v1/x19.png)
Влияние и Обобщение: Надежность в Различных Задачах
Эффективность механизма Elastic Attention напрямую зависит от специфики решаемой задачи. Исследования показывают, что некоторые задачи обладают внутренней устойчивостью к разреженности (Sparsity-Robustness), позволяя алгоритму эффективно отбрасывать незначимые связи без существенной потери производительности. В то же время, существуют задачи, критичные к разреженности (Sparsity-Sensitive Tasks), где неконтролируемое уменьшение плотности связей может привести к заметному снижению точности. Таким образом, способность Elastic Attention адаптировать уровень разреженности становится ключевым фактором, определяющим его применимость и эффективность в различных областях, подчеркивая необходимость индивидуального подхода к настройке для достижения оптимальных результатов.
В задачах, чувствительных к разреженности (Sparsity-Sensitive Tasks), требуется тщательная настройка механизма Elastic Attention для предотвращения снижения производительности. Исследования показывают, что простая оптимизация для общей разреженности недостаточна, поскольку некоторые задачи требуют более тонкого подхода к динамической адаптации. Это означает, что уровень разреженности должен регулироваться в зависимости от специфики входных данных и этапа обработки, чтобы поддерживать высокую точность и эффективность. Неспособность к такой адаптации может привести к значительным потерям в производительности, особенно в сложных задачах, требующих точного анализа и обработки информации. Таким образом, способность динамически подстраивать уровень разреженности является ключевым фактором для успешного применения Elastic Attention в задачах, где сохранение информации критически важно.
Механизм Elastic Attention демонстрирует передовые результаты в задачах, требующих обработки длинных контекстов, благодаря интеллектуальной адаптации разреженности. В ходе тестирования на бенчмарке RULER, система достигла показателя в 68.51, что свидетельствует о высокой эффективности. Конфигурация XA-SSA позволила добиться ускорения вычислений до 3.28 раз, при этом сохранив высокую степень разреженности (эффективное соотношение разреженности, \Omega_{ESR} , составило 0.995). Это указывает на способность Elastic Attention эффективно оптимизировать использование ресурсов и поддерживать высокую производительность даже при обработке больших объемов данных, что делает его перспективным решением для широкого спектра задач обработки естественного языка.

Исследование представляет собой дерзкий вызов устоявшимся представлениям о фиксированной структуре больших языковых моделей. Авторы не просто оптимизируют существующие параметры, а предлагают динамически адаптировать разреженность сети в процессе работы, словно взламывая ограничения аппаратного обеспечения. Этот подход, названный Elastic Attention, позволяет модели самостоятельно определять, какие связи наиболее важны для конкретной задачи, и отбрасывать ненужные, подобно опытному инженеру, разбирающему сложный механизм. Тим Бернерс-Ли однажды заметил: «Веб не должен зависеть от определенных машин или программ». Подобно этой идее о децентрализации и адаптивности, Elastic Attention освобождает модель от жестких ограничений, позволяя ей эффективно работать в различных условиях и с разными типами данных, демонстрируя потенциал для создания действительно универсального и интеллектуального искусственного интеллекта.
Куда же это всё ведёт?
Представленный подход к адаптивной разреженности внимания, безусловно, демонстрирует потенциал к оптимизации больших языковых моделей без необходимости внесения изменений в их базовую архитектуру. Однако, за кажущейся эффективностью скрывается более глубокий вопрос: не является ли стремление к разреженности лишь временным решением, маскирующим фундаментальные неэффективности существующих моделей? По сути, это попытка «выжать» больше из уже существующей системы, вместо того, чтобы переосмыслить её принципы. Предстоит выяснить, насколько далеко можно зайти в динамической адаптации, не столкнувшись с законом убывающей отдачи.
Особое внимание следует уделить исследованию границ применимости данной техники. Утверждение о «устойчивости к задачам» требует более тщательной проверки на действительно разнообразных и сложных данных. Более того, необходимо понять, как Elastic Attention взаимодействует с другими методами оптимизации, такими как квантизация или прунинг. Иными словами, возможно ли создать «оркестр» оптимизаций, где каждый инструмент усиливает эффект других, или же мы достигнем точки, когда дальнейшее усложнение системы приведёт лишь к увеличению энтропии.
В конечном счёте, истинное развитие в данной области, вероятно, потребует отказа от текущей парадигмы «всё больше и больше параметров». Вместо этого, необходимо сосредоточиться на разработке принципиально новых архитектур, которые будут по своей сути более эффективными и компактными. Иначе говоря, вместо того, чтобы «подлаживать» систему, следует её перепроектировать. Ведь, как известно, иногда самое элегантное решение — это не усложнение, а упрощение.
Оригинал статьи: https://arxiv.org/pdf/2601.17367.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Будущее SOL: прогноз цен на криптовалюту SOL
- MegaETH: Падение Токена MEGA и Рост TVL – Что Ждет Инвесторов? (03.05.2026 01:45)
- ТГК-14 акции прогноз. Цена TGKN
- ТГК-1 акции прогноз. Цена TGKA
- Мечел акции прогноз. Цена MTLR
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- Татнефть префы прогноз. Цена TATNP
- Whoosh акции прогноз. Цена WUSH
2026-01-27 06:55