Автор: Денис Аветисян
Исследователи предложили метод, позволяющий повысить устойчивость моделей машинного обучения к изменениям в данных и улучшить их обобщающую способность.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал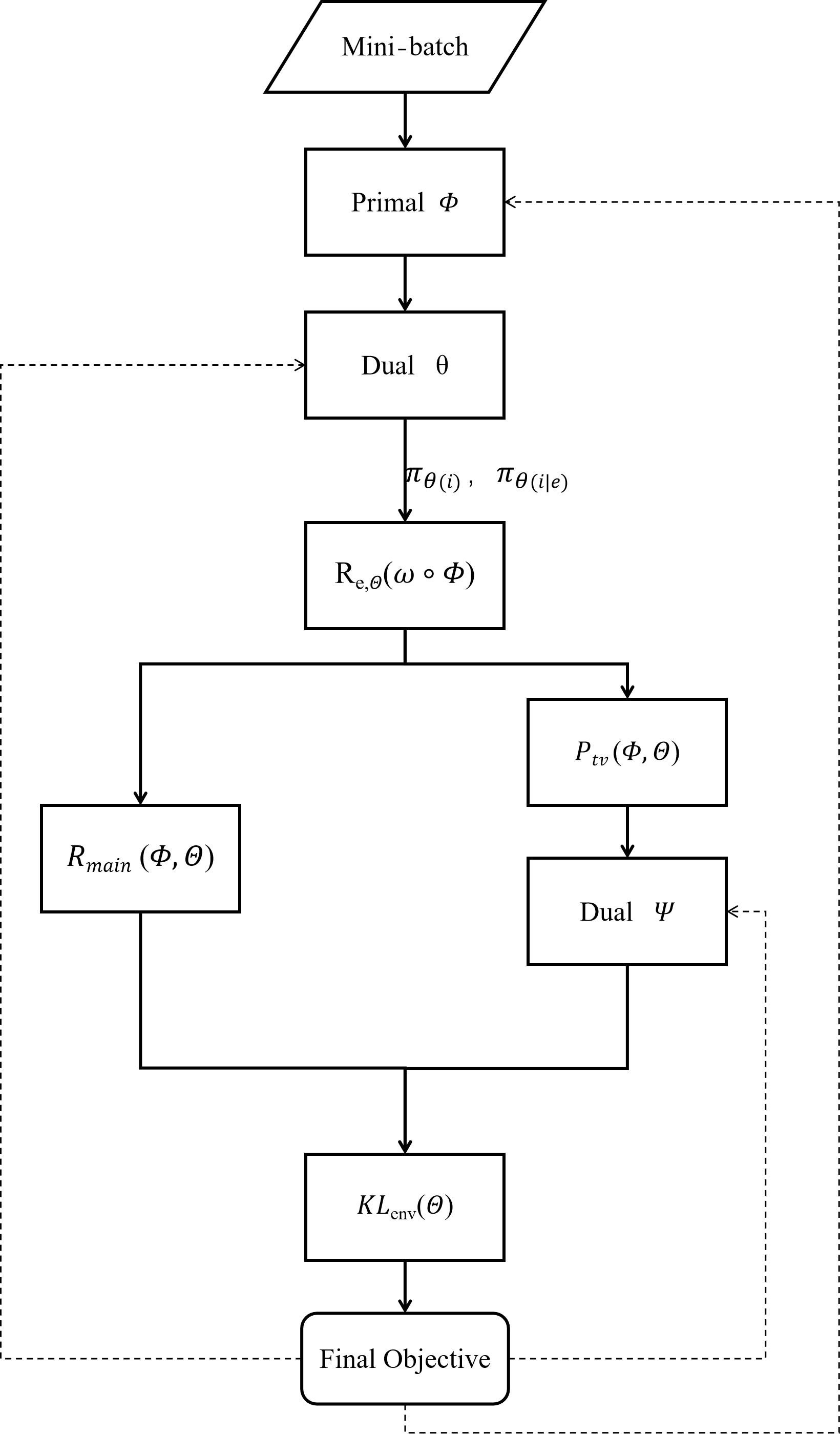
Предложен алгоритм Environment-Conditioned Tail Reweighting (ECTR) для достижения инвариантности к изменениям в распределении данных и повышения устойчивости к выбросам.
Обобщение моделей за пределами обучающей выборки остаётся сложной задачей при одновременном изменении корреляций между средами и появлении редких или сложных образцов. В данной работе, посвященной методу ‘Environment-Conditioned Tail Reweighting for Total Variation Invariant Risk Minimization’, предложен новый подход ECTR, объединяющий инвариантность на уровне сред с устойчивостью к “хвостам” распределений внутри каждой среды. Интегрируя эти два механизма, предложенный подход демонстрирует взаимодополняющий эффект при смешанных сдвигах распределений, а также расширяется на сценарии без явных аннотаций сред посредством минимаксной формулировки. Способны ли подобные методы значительно повысить надежность моделей машинного обучения в реальных, динамически меняющихся условиях?
Проблема Внераспределённого Обобщения: Вызов для Машинного Обучения
Машинное обучение, несмотря на впечатляющие успехи, часто сталкивается с трудностями при применении в условиях, отличающихся от тех, в которых модель была обучена — это явление получило название проблемы обобщения вне распределения (out-of-distribution generalization). Представьте себе систему распознавания изображений, обученную на фотографиях кошек в студийном освещении; при переносе в реальный мир, с естественным освещением и различными ракурсами, точность может значительно снизиться. Данная проблема является критичной для широкого спектра приложений, от автономных транспортных средств до медицинских диагностических систем, поскольку надежность предсказаний напрямую зависит от способности модели адаптироваться к новым, ранее не встречавшимся данным. По сути, модель, прекрасно работающая в лабораторных условиях, может оказаться бесполезной в реальном мире, если не сможет эффективно справляться с изменениями в данных.
Ненадёжность предсказаний моделей машинного обучения в новых, незнакомых условиях часто обусловлена двумя основными причинами: ложными корреляциями и смещениями в распределении данных. Ложные корреляции возникают, когда модель выучивает связь между признаками и целевой переменной, которая является случайной или не причинно-следственной, приводя к ошибочным выводам при изменении контекста. Смещение в распределении данных, в свою очередь, проявляется в различиях между данными, на которых обучалась модель, и данными, с которыми она сталкивается в реальной эксплуатации. Оба эти фактора приводят к тому, что модель, успешно работавшая на тренировочном наборе, демонстрирует значительно худшие результаты в новых сценариях, подчеркивая необходимость разработки методов, устойчивых к таким искажениям и способных к обобщению за пределы исходного распределения данных.
Традиционные методы машинного обучения, основанные на минимизации эмпирического риска, зачастую не учитывают уязвимости, возникающие при столкновении с данными, отличными от тренировочного набора. В стремлении к высокой точности на известных данных, эти подходы игнорируют возможность появления ложных корреляций и смещений в распределении, что приводит к резкому снижению надежности прогнозов в новых, ранее не встречавшихся условиях. В связи с этим, всё большее внимание уделяется разработке более устойчивых стратегий обучения, способных выявлять и компенсировать эти недостатки, и обеспечивать надёжную работу моделей в условиях реального мира, где данные по своей природе изменчивы и непредсказуемы. Исследования в области робастного обучения направлены на создание алгоритмов, нечувствительных к небольшим изменениям во входных данных и способных обобщать знания на принципиально новые сценарии.
Минимизация Инвариантного Риска: Первый Шаг к Устойчивости
Метод минимизации инвариантного риска (IRM) направлен на обучение представлений, которые остаются предсказательными в различных средах. Ключевая идея заключается в отделении истинного сигнала от шума, возникающего из-за ложных корреляций. IRM достигает этого путем поиска представлений, которые минимизируют эмпирический риск во всех рассматриваемых средах, одновременно, что позволяет модели обобщать знания и избегать переобучения на специфических особенностях каждой отдельной среды. По сути, IRM стремится выявить признаки, которые являются причинно-следственными для целевой переменной, а не просто коррелируют с ней в определенной среде, тем самым повышая устойчивость модели к изменениям в окружении.
Метод минимизации инвариантного риска (IRM) демонстрирует чувствительность к выбору обучающих сред и может давать сбои в ситуациях со сложной причинно-следственной структурой данных. На практике, IRM предполагает наличие инвариантных предикторов, общих для всех сред, однако если истинные причинно-следственные связи сложны и не отражаются в выбранных средах, алгоритм может выделить ложные корреляции, приводящие к неробастным решениям. В частности, если причинно-следственная структура различается между средами, минимизация риска в каждой среде может привести к выделению признаков, специфичных для каждой среды, а не инвариантных предикторов, что снижает обобщающую способность модели на новых, невидимых средах.
Расширения IRM, такие как Group DRO (Domain Robust Optimization), направлены на повышение устойчивости моделей путем минимизации наихудшего случая потерь по предопределенным группам данных. В отличие от IRM, который стремится к инвариантности представлений между средами, Group DRO явно оптимизирует производительность на группе с наихудшими показателями. Это достигается путем добавления регуляризационного члена к функции потерь, который штрафует за большие различия в потерях между группами. Таким образом, модель обучается не только предсказывать целевую переменную, но и обеспечивать приемлемый уровень точности для всех заданных групп, что повышает ее обобщающую способность и надежность в различных условиях.
Адаптация к Окружению и Перевзвешивание Хвостов: Приспособление к Неизвестному
Обусловленность средой (Environment Conditioning) представляет собой механизм динамической адаптации процесса обучения на основе выведенной информации об окружающей среде. Этот подход позволяет модели корректировать свои параметры и поведение в зависимости от контекста входных данных, что особенно важно при работе с непредсказуемыми или меняющимися условиями. Вместо жесткой фиксации параметров, модель использует вероятностные оценки принадлежности данных к различным средам, что позволяет ей эффективно обобщать знания и адаптироваться к новым, ранее не встречавшимся вариациям входных данных. Это достигается путем учета информации о среде как дополнительного входного параметра в процессе обучения, что позволяет модели учитывать контекст и делать более точные прогнозы или принимать более обоснованные решения.
Для оценки «мягких» принадлежностей к различным средам используется метод ZIN (Zero-Inflated Negative Binomial regression). ZIN позволяет модели вычислять вероятности принадлежности каждой точки данных к разным контекстам, а не ограничиваться жестким назначением к одной конкретной среде. Это достигается путем моделирования данных как смеси двух процессов: процесса нулевой инфляции (где вероятность наблюдения нулевого значения высока) и процесса, описываемого отрицательным биномиальным распределением. В результате, модель получает возможность учитывать неопределенность и неоднозначность в данных, что повышает ее способность к обобщению и адаптации к новым, ранее не встречавшимся условиям. Использование вероятностных «мягких» назначений позволяет учитывать вклад каждой точки данных в процесс обучения, даже если ее контекст не определен однозначно.
Комбинирование адаптации к окружению (Environment Conditioning) с перевзвешиванием «хвоста» распределения (Tail Reweighting) позволяет значительно повысить устойчивость модели к новым, неизвестным данным. Перевзвешивание фокусируется на сложных и редких примерах, которым модель изначально придает меньший вес при обучении. Сочетание с адаптацией к окружению, определяющей контекст каждой точки данных, позволяет модели более эффективно использовать информацию из этих сложных примеров, поскольку контекст помогает уточнить, какие аспекты данных наиболее важны для правильного решения. В результате, модель становится менее чувствительной к отклонениям в данных и лучше обобщает знания на новые, ранее не встречавшиеся ситуации.
ECTR: Комплексный Подход к Надежному Обобщению
Метод ECTR (Environment-Conditioned Tail Reweighting) для инвариантной к полной вариации минимизации риска объединяет в себе преимущества обусловленного окружением взвешивания хвостов распределения, регуляризации полной вариацией и учета контекста окружающей среды. Обусловленное окружением взвешивание позволяет динамически корректировать веса выборок в зависимости от их принадлежности к определенной среде, что повышает устойчивость обучения. Регуляризация полной вариацией TV способствует стабилизации риска относительно параметра фиктивного классификатора, обеспечивая обобщающую способность модели. Комбинирование этих подходов позволяет ECTR эффективно справляться с проблемами смещения данных и достигать высоких результатов на различных бенчмарках, таких как PACS, Colored MNIST и NICO.
Метод ECTR использует технику Adversarial Reweighting для уточнения весов выборок в процессе обучения. Этот подход заключается в обучении дополнительного классификатора (adversary), который предсказывает, является ли выборка «сложной» для текущей модели. Веса выборок корректируются на основе предсказаний этого классификатора: более сложные выборки получают больший вес, а простые — меньший. Такая процедура позволяет модели фокусироваться на информативных и сложных примерах, что способствует более стабильному обучению и улучшает обобщающую способность, предотвращая переобучение на простых данных и эффективно используя сложные примеры для повышения точности.
Метод ECTR (Environment-Conditioned Tail Reweighting) повышает обобщающую способность за счет применения TV-штрафа (Total Variation Penalty). Данный штраф обеспечивает стационарность риска относительно параметра фиктивного классификатора, что способствует более устойчивому обучению и предотвращает переобучение. В результате, ECTR демонстрирует передовые или конкурентоспособные результаты на стандартных бенчмарках, включая PACS, Colored MNIST и NICO, подтверждая эффективность данного подхода к обобщению.
Представленная работа акцентирует внимание на достижении обобщающей способности моделей машинного обучения в условиях смещения распределений данных. Авторы предлагают подход, основанный на взвешивании «хвостов» распределений с учетом специфики окружающей среды, что позволяет повысить устойчивость к новым, ранее не встречавшимся условиям. Этот метод созвучен идеям, высказанным Давидом Гильбертом: «В математике нет спектра. Есть лишь математика». Подобно стремлению к абсолютной точности в математике, представленное исследование направлено на создание алгоритмов, устойчивых к любым изменениям входных данных, обеспечивая детерминированность и надёжность результатов, а не полагаясь на эмпирические наблюдения и «работу на тестах».
Куда Далее?
Предложенный подход, манипулируя «хвостами» распределений и обуславливая их средой, демонстрирует стремление к созданию робастных алгоритмов. Однако, следует признать, что перенос обучения за пределы распределения — задача, требующая не просто ухищрений с весами, но фундаментального переосмысления принципов инвариантности. Обучение, ориентированное на «среду», неизбежно наталкивается на проблему определения этой самой «среды» — не является ли это лишь заменой одной неопределенности другой? Иллюзия контроля над смещением распределений может оказаться более опасной, чем признание его неизбежности.
Будущие исследования должны сосредоточиться на формализации понятия «хвоста» и его связи с истинной генерализацией, а не просто с производительностью на тестовых данных. Необходимо исследовать, как предложенный метод взаимодействует с различными типами смещений распределений, и в каких случаях он уступает более простым, но более понятным подходам. Особенно важно оценить вычислительную стоимость и практическую применимость предложенного решения, ведь элегантность алгоритма бесполезна, если он недоступен для реального использования.
В конечном счете, настоящим вызовом остается не создание алгоритмов, которые «адаптируются» к новым условиям, а построение таких алгоритмов, которые изначально нечувствительны к этим условиям. Поиск такой абсолютной инвариантности — задача, возможно, недостижимая, но именно она должна быть маяком для будущих исследований в области робастного машинного обучения.
Оригинал статьи: https://arxiv.org/pdf/2601.22944.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Координация Роя: Новый Алгоритм для Планирования Задач и Движений
- Будущее SOL: прогноз цен на криптовалюту SOL
- Стоит ли покупать евро за малайзийские ринггиты сейчас или подождать?
- Сегежа акции прогноз. Цена SGZH
- ТГК-1 акции прогноз. Цена TGKA
- Amazon: Между Надеждой и Разочарованием
- Казаньоргсинтез акции прогноз. Цена KZOS
- ВСМПО-АВИСМА акции прогноз. Цена VSMO
2026-02-02 10:59