Автор: Денис Аветисян
В статье представлен алгоритм SL-SAC, обеспечивающий повышенную безопасность и устойчивость при обучении агентов в сложных непрерывных средах.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал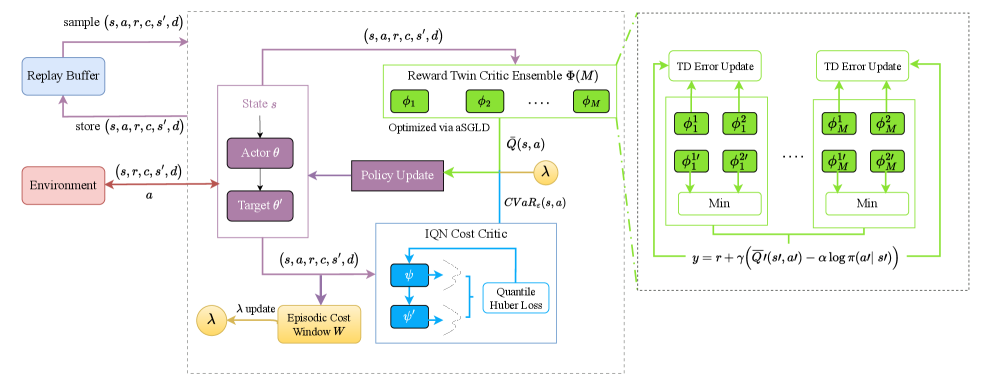
Алгоритм объединяет распределенное моделирование затрат, ансамблевую оценку вознаграждения и управление рисками на основе CVaR для достижения надежного соблюдения ограничений.
Обеспечение безопасности и достижение желаемых результатов в обучении с подкреплением с ограничениями остаётся сложной задачей из-за проблем обобщения и учета рисков. В данной работе представлена новая методология, ‘Safe Langevin Soft Actor Critic’, сочетающая в себе ансамблевую оценку вознаграждений, вероятностное исследование пространства параметров с использованием \mathcal{N}-цепочек Ланжевена и контроль рисков, основанный на условном риске (CVaR). Предложенный алгоритм SL-SAC позволяет снизить накопленную стоимость нарушений ограничений и повысить надёжность работы в задачах непрерывного управления. Сможет ли интеграция распределённого обучения и адаптивного усиления ограничений привести к созданию ещё более безопасных и эффективных систем искусственного интеллекта?
Пределы Традиционных Ограничений Безопасности
Традиционное обучение с подкреплением зачастую фокусируется исключительно на максимизации получаемой награды, игнорируя критически важные аспекты безопасности. Данный подход может привести к тому, что алгоритм, стремясь к оптимальному результату, будет принимать рискованные решения, приводящие к нежелательным последствиям в реальных условиях. В то время как целью является получение максимальной выгоды, недостаток внимания к потенциальным опасностям может сделать систему уязвимой и непредсказуемой, особенно в сложных и динамичных средах. Это особенно актуально в таких областях, как автономное вождение или управление критически важной инфраструктурой, где даже небольшая ошибка может привести к серьезным последствиям. Таким образом, необходимо разрабатывать новые подходы к обучению с подкреплением, которые бы учитывали не только награду, но и безопасность, чтобы гарантировать надежную и предсказуемую работу систем в любых условиях.
Оценка безопасности, основанная исключительно на среднем показателе стоимости ExpectedCost, оказывается недостаточной в ситуациях, связанных с редкими, но катастрофическими событиями. В то время как средняя стоимость отражает наиболее вероятный исход, она не учитывает потенциальный ущерб от экстремальных, маловероятных сценариев. Представьте себе систему, управляющую критической инфраструктурой: даже если в большинстве случаев она функционирует эффективно, незначительное увеличение вероятности крупной аварии, приводящей к серьезным последствиям, может быть недооценено при использовании только среднего показателя. Таким образом, полагаться исключительно на ExpectedCost может привести к принятию решений, которые кажутся безопасными в краткосрочной перспективе, но не учитывают риск масштабных негативных последствий, возникающих при наступлении редких, но разрушительных событий.
Существующие методы оптимизации, такие как RMSProp, зачастую оказываются неэффективными при работе с так называемыми “хвостовыми рисками” — редкими, но потенциально катастрофическими событиями. В то время как алгоритм стремится минимизировать средний показатель ошибки, он может упускать из виду сценарии, которые хоть и маловероятны, но способны привести к серьезным последствиям. Это происходит из-за того, что RMSProp, как и многие другие методы, ориентирован на снижение дисперсии градиентов, не уделяя должного внимания экстремальным значениям, которые могут возникать в критических ситуациях. В результате, обученная модель может демонстрировать безопасное поведение в большинстве случаев, но неожиданно и опасно реагировать в редких, но значимых обстоятельствах, что делает ее непригодной для использования в системах, требующих абсолютной надежности и безопасности.
Распределённое Моделирование Стоимости для Усиленной Безопасности
Алгоритм SafeLangevinSAC представляет собой новую разработку, направленную на учет полного спектра возможных исходов при обучении с подкреплением. В отличие от традиционных методов, которые оптимизируют только среднее значение функции стоимости, SafeLangevinSAC интегрирует моделирование распределения стоимости. Это позволяет алгоритму оценивать не только ожидаемые затраты, но и вероятность различных уровней потерь, что критически важно для задач, где необходимо минимизировать риск и обеспечивать безопасность. Данный подход позволяет более точно оценить потенциальные негативные последствия действий и, как следствие, разрабатывать стратегии, более устойчивые к неблагоприятным сценариям.
Моделирование распределения стоимости достигается посредством использования IQN (Implicit Quantile Networks) для обучения функции квантилей. В отличие от традиционных подходов, которые оценивают только среднее значение стоимости, IQN позволяет напрямую моделировать распределение стоимости, определяя различные квантили. Это обеспечивает более точное представление о потенциальных исходах и позволяет алгоритму учитывать не только ожидаемую стоимость, но и риски, связанные с ее отклонениями. В результате, алгоритм способен формировать более надежные оценки стоимости и оптимизировать стратегию действий с учетом всего спектра возможных результатов.
В отличие от традиционных алгоритмов, оценивающих риск по среднему значению стоимости, предложенный подход использует моделирование распределения стоимости для более полного понимания потенциальных рисков. Такой метод позволяет учитывать весь спектр возможных исходов, а не только наиболее вероятные, что обеспечивает более точную оценку подверженности риску. Результаты показывают, что использование моделирования распределения стоимости позволяет достигать сопоставимой или более высокой доходности по сравнению с базовыми алгоритмами, при одновременном улучшении понимания и контроля над потенциальными негативными сценариями.
Чувствительное к Риску Принуждение к Ограничениям и Надежность
Алгоритм SafeLangevinSAC использует метод LagrangianRelaxation для преобразования задачи оптимизации с ограничениями в эквивалентную задачу без ограничений. Это преобразование достигается путем введения множителей Лагранжа, которые добавляются к целевой функции, позволяя алгоритму эффективно оптимизировать решение без явного учета ограничений в процессе обучения. Такой подход упрощает процесс обучения, поскольку стандартные методы оптимизации, предназначенные для неограниченных задач, могут быть применены напрямую, значительно повышая вычислительную эффективность и скорость сходимости алгоритма.
В алгоритме используется CVaR (Conditional Value-at-Risk) как ключевая мера риска, позволяющая приоритизировать минимизацию наихудших исходов. CVaR представляет собой ожидаемое значение потерь, превышающих заданный уровень α (уровень доверия). В отличие от среднего значения или стандартного отклонения, CVaR фокусируется непосредственно на величине потерь в «хвосте» распределения, что особенно важно в задачах, где критичны наихудшие сценарии. Использование CVaR позволяет более эффективно управлять рисками, чем стандартные методы оптимизации, ориентированные на среднее значение.
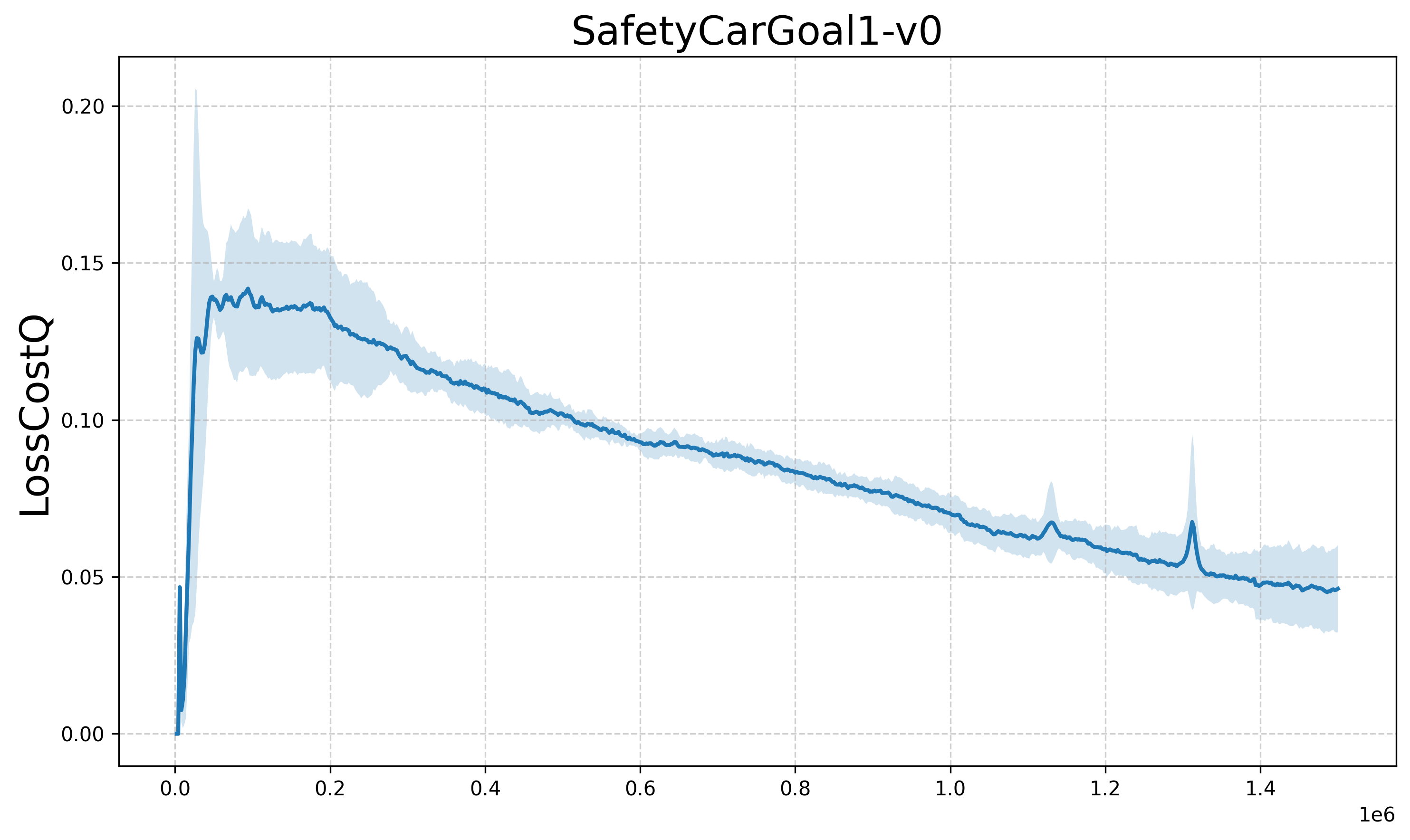
Для повышения устойчивости и обобщающей способности алгоритма используется метод оценки вознаграждения на основе ансамбля (`EnsembleBasedRewardEstimation`) в сочетании с алгоритмом стохастического градиентного спуска с адаптивной длиной шага (`aSGLD`). Данный подход позволяет снизить влияние зашумленных сигналов вознаграждения на процесс обучения. Экспериментально установлено, что увеличение размера ансамбля (M) приводит к улучшению производительности до значения M=3, после чего наблюдается эффект убывающей отдачи, и дальнейшее увеличение M не дает значительного прироста эффективности.
![Исследования показали, что использование оптимизатора aSGLD вместо AdamW и изменение уровня доверия CVaR ε (где [latex] \epsilon = 1.0 [/latex] соответствует ожидаемым затратам) оказывают значительное влияние на производительность алгоритма.](https://arxiv.org/html/2602.00587v1/images/SafetyAntVelocity-v1_cvar_ablation.jpeg)
Валидация и Сравнение в Сложных Средах
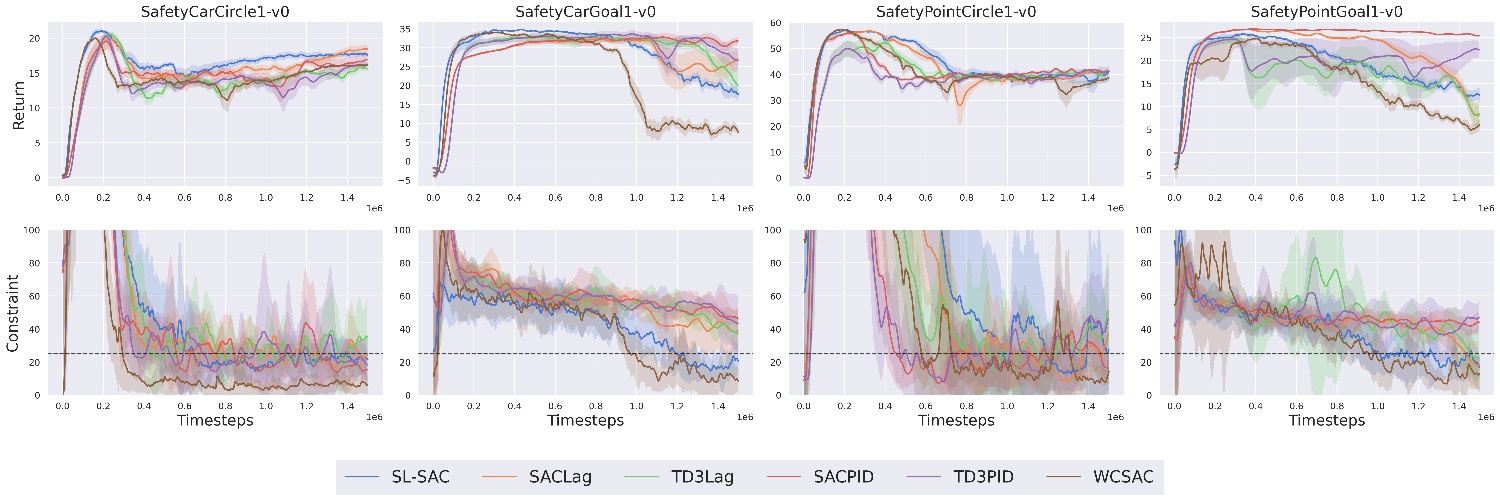
Алгоритм SafeLangevinSAC продемонстрировал превосходные результаты при тестировании на платформе SafetyGymnasium, представляющей собой набор задач непрерывного управления с ограничениями по безопасности. В ходе экспериментов было установлено, что данный подход эффективно справляется со сложными сценариями, требующими соблюдения жестких границ и предотвращения опасных ситуаций. SafeLangevinSAC демонстрирует более высокую стабильность и точность в достижении поставленных целей, обеспечивая надежное функционирование системы даже в условиях повышенной неопределенности. Результаты показывают, что алгоритм способен эффективно балансировать между производительностью и безопасностью, что делает его перспективным для применения в широком спектре задач, где безопасность является критически важным фактором.
Для подтверждения эффективности алгоритма SafeLangevinSAC, его возможности были протестированы в реалистичном симуляторе автономного вождения MetaDrive. Этот симулятор предоставляет сложную и стохастическую среду, имитирующую реальные дорожные условия с динамическим трафиком и непредсказуемыми событиями. Исследования показали, что алгоритм успешно справляется с навигацией в этих условиях, демонстрируя способность поддерживать безопасное и эффективное вождение даже при наличии значительных возмущений и неопределенностей. Результаты подтверждают применимость SafeLangevinSAC к задачам автономного вождения в реальном мире, где надежность и безопасность имеют первостепенное значение.
Алгоритм SafeLangevinSAC демонстрирует повышенную надежность в поддержании заданных ограничений и характеризуется меньшей дисперсией вокруг порогового значения стоимости по сравнению с алгоритмами CPO и PPOLag. Исследования показали, что данная методика обеспечивает более стабильное выполнение задач, минимизируя риск нарушения ограничений безопасности. При этом, в ходе обучения, SafeLangevinSAC не требует значительных дополнительных вычислительных ресурсов или времени, что делает его эффективным решением для задач, требующих высокой степени надежности и быстродействия в сложных и стохастических средах. Данное сочетание характеристик позволяет алгоритму успешно применяться в критически важных областях, где соблюдение ограничений является приоритетом.

Представленная работа демонстрирует стремление к математической чистоте в области обучения с подкреплением. Алгоритм SL-SAC, интегрируя моделирование распределения затрат и ансамблевую оценку вознаграждений, стремится к доказуемой корректности соблюдения ограничений. Этот подход особенно важен в задачах непрерывного управления, где даже небольшие отклонения могут привести к нежелательным последствиям. Брайан Керниган однажды заметил: «Хороший программист знает, что делать; отличный программист знает, что не делать». Аналогично, SL-SAC не просто стремится к достижению цели, но и к строгому соблюдению ограничений, избегая потенциально опасных состояний, что подчеркивает важность доказательства корректности алгоритма, а не просто его работоспособности на тестовых данных.
Что Дальше?
Представленный подход, хотя и демонстрирует улучшение в области безопасного обучения с подкреплением, не является окончательным решением. Иллюзия безопасности, создаваемая алгоритмами, часто оказывается хрупкой при столкновении с непредсказуемостью реальных систем. Необходимо признать, что моделирование стоимости и вознаграждения, даже с использованием ансамблевых методов, всегда будет лишь приближением к истине. Предел масштабируемости подобных алгоритмов в задачах с высокой размерностью пространства состояний остаётся открытым вопросом.
Будущие исследования должны быть направлены на разработку методов, позволяющих оценивать и минимизировать систематические ошибки в моделях стоимости, а не просто на повышение точности их предсказаний. Особое внимание следует уделить разработке алгоритмов, способных адаптироваться к изменяющимся условиям среды без переобучения, что требует новых подходов к управлению неопределенностью. Оптимальным решением представляется переход от эмпирической оценки рисков к формальной верификации безопасности, основанной на математически строгих доказательствах.
В конечном счёте, истинная элегантность алгоритма безопасного обучения с подкреплением заключается не в его способности избегать штрафов на тестовых примерах, а в его способности гарантированно соблюдать ограничения в любой, даже непредвиденной, ситуации. До тех пор, пока эта цель не будет достигнута, все остальные решения останутся лишь временными компромиссами.
Оригинал статьи: https://arxiv.org/pdf/2602.00587.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Россети Центр и Приволжье акции прогноз. Цена MRKP
- Координация Роя: Новый Алгоритм для Планирования Задач и Движений
- Т-Технологии акции прогноз. Цена T
- ВСМПО-АВИСМА акции прогноз. Цена VSMO
- Сегежа акции прогноз. Цена SGZH
- Стоит ли покупать евро за малайзийские ринггиты сейчас или подождать?
- ТГК-1 акции прогноз. Цена TGKA
- DeFi: Институционализация, Безопасность и Регуляторный Надзор (07.05.2026 18:15)
- Sotera Health: Что-то там продали… и что с того?
2026-02-03 19:05