Автор: Денис Аветисян
Новый подход позволяет эффективно находить оптимальные стратегии в динамичных средах с неполной информацией о состоянии системы.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал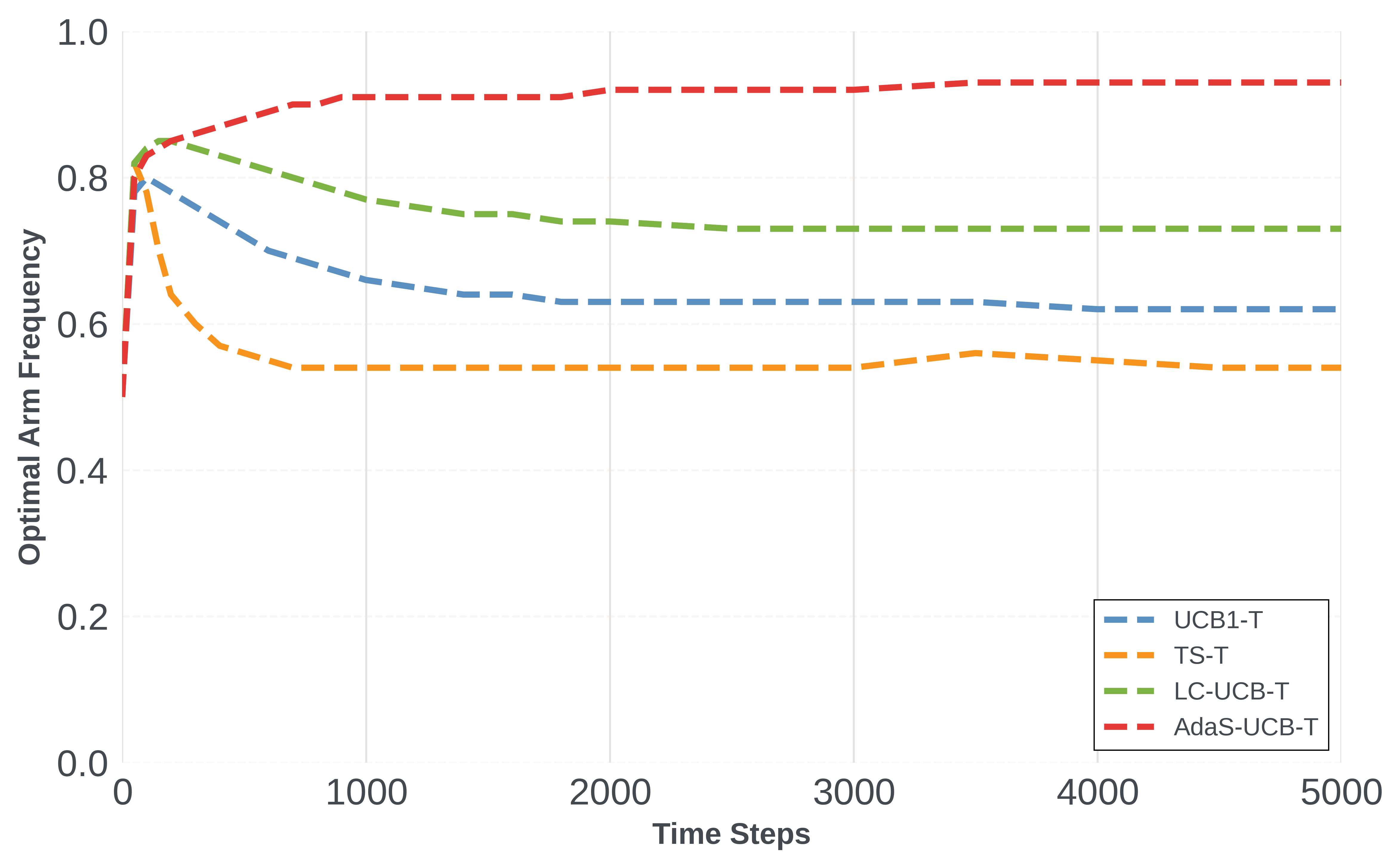
В статье представлен метод адаптивного зондирования для минимизации кумулятивного сожаления в задачах с контекстными бандитами и скрытыми состояниями.
Классические алгоритмы для задач о многоруких бандитах часто демонстрируют неэффективность в динамичных средах со скрытыми состояниями, искажающими оценки вознаграждений. В данной работе, ‘Adaptive Exploration for Latent-State Bandits’, предложен семейство алгоритмов, не требующих явного моделирования состояний, и использующих стратегии адаптивного зондирования для отслеживания латентных переменных. Это позволяет снизить кумулятивное сожаление и повысить эффективность обучения оптимальных политик в нестанционарных условиях. Какие перспективы открываются для применения предложенных методов в реальных задачах, требующих последовательного принятия решений в условиях неопределенности и скрытых факторов?
Нестабильность Решений: Вызов для Современного Искусственного Интеллекта
Многие задачи, с которыми сталкивается современный искусственный интеллект, представляют собой последовательность принимаемых решений, в которых наилучшая стратегия со временем меняется. Например, в динамически меняющихся рекламных кампаниях предпочтения пользователей и эффективность объявлений могут быстро устаревать, требуя постоянной адаптации. Аналогичная ситуация наблюдается в управлении финансовыми портфелями, где рыночные условия и инвестиционные возможности постоянно эволюционируют. Такая непостоянность среды, известная как не стационарность, создает значительные трудности для традиционных алгоритмов, разработанных для работы в стабильных условиях. В таких ситуациях алгоритм, успешно работавший вчера, может оказаться неэффективным сегодня, что требует разработки новых подходов, способных учитывать изменчивость окружающей среды и быстро адаптироваться к новым условиям.
Традиционные алгоритмы, известные как «бандиты», испытывают затруднения в динамически меняющихся условиях, поскольку их эффективность основана на предположении о стационарности распределения вознаграждений. Эти алгоритмы, разработанные для ситуаций, где вероятность получения выигрыша от конкретного действия остается постоянной во времени, не способны эффективно адаптироваться к изменяющимся закономерностям. В результате, при появлении новых, более выгодных действий, или изменении привлекательности уже существующих, «бандиты» продолжают эксплуатировать устаревшие стратегии, что приводит к снижению общей эффективности и упущенным возможностям. Их механизм принятия решений, ориентированный на стабильные условия, оказывается неэффективным в средах, где оптимальная стратегия постоянно эволюционирует.
Для успешной работы в динамически меняющихся условиях, алгоритмы принятия решений должны обладать способностью адаптироваться к новым обстоятельствам и эффективно сочетать исследование (exploration) и использование накопленного опыта (exploitation). Это означает, что алгоритм должен постоянно оценивать текущую ситуацию и корректировать свою стратегию, чтобы максимизировать вознаграждение, не упуская возможности обнаружить более выгодные варианты. Оптимальный баланс между исследованием и использованием является ключевым, поскольку чрезмерное сосредоточение на текущих знаниях может привести к упущению новых, более эффективных стратегий, в то время как постоянное исследование без использования может привести к снижению общей производительности. Разработка таких алгоритмов представляет собой сложную задачу, требующую учета скорости изменения окружающей среды, степени неопределенности и стоимости ошибок.
Скрытые Факторы и Сложность Оценки Вознаграждений
В задачах последовательного принятия решений наблюдаемые награды часто подвержены влиянию ненаблюдаемых, скрытых состояний, которые изменяются во времени. Эти скрытые состояния представляют собой внутренние факторы, неявно определяющие динамику среды или предпочтения пользователя, и не могут быть непосредственно измерены или учтены в процессе обучения агента. Изменение этих состояний приводит к вариативности в наградах, даже при одинаковых действиях, что усложняет задачу определения оптимальной стратегии. Например, в рекомендательных системах скрытое состояние может отражать текущее настроение пользователя, влияющее на его реакцию на предлагаемый контент, или в робототехнике — износ оборудования, влияющий на эффективность действий.
Скрытые состояния в задачах последовательного принятия решений могут отражать различные не наблюдаемые факторы, влияющие на процесс. К таким факторам относятся изменения во внешней среде, например, колебания температуры или освещенности, которые не фиксируются напрямую, но оказывают влияние на наблюдаемые результаты. Кроме того, скрытые состояния могут представлять собой изменения в предпочтениях или состоянии самого пользователя, такие как уровень усталости, мотивации или текущие цели, которые влияют на его поведение и восприятие вознаграждений. Например, в системе рекомендаций скрытое состояние может кодировать текущий интерес пользователя, который меняется со временем и влияет на его реакцию на предлагаемый контент.
Цепь Маркова предоставляет эффективный инструмент для моделирования динамики скрытых состояний, оказывающих влияние на процесс принятия решений. В рамках данной модели, вероятность текущего скрытого состояния определяется исключительно предыдущим состоянием, что соответствует свойству отсутствия памяти. Математически это выражается как P(s_t | s_{t-1}, s_{t-2}, ...) = P(s_t | s_{t-1}), где s_t представляет собой скрытое состояние в момент времени t. Использование цепей Маркова позволяет формализовать зависимость между последовательными состояниями и предсказывать их эволюцию, что критически важно для анализа и оптимизации стратегий в задачах с неполной наблюдаемостью.
Когда скрытые состояния оказывают влияние как на предпринимаемые действия, так и на получаемые вознаграждения, они выступают в роли вмешивающихся переменных (confounding variables). Это приводит к появлению ложных корреляций между действиями и вознаграждениями, поскольку наблюдаемая связь может быть обусловлена не прямым влиянием действия, а общим влиянием скрытого состояния. В результате, алгоритмы обучения, основанные на корреляциях, могут давать неверные оценки ценности действий и, следовательно, препятствовать эффективному обучению агента в среде с неполной наблюдаемостью. Для преодоления этой проблемы используются методы, учитывающие скрытые состояния, такие как частично наблюдаемые марковские процессы принятия решений (POMDPs) или методы вывода скрытых состояний.
Адаптация к Переменам: Алгоритмы для Нестабильных Ссред
Фреймворк «Контекстные бандиты» представляет собой эффективный подход к последовательному принятию решений, основанный на учете контекстных признаков. В отличие от классических задач обучения с подкреплением, где агент взаимодействует со стационарной средой, контекстные бандиты позволяют учитывать информацию о текущем состоянии, что позволяет алгоритму адаптироваться к изменяющимся условиям и выбирать действия, наиболее соответствующие конкретной ситуации. Каждое действие оценивается на основе полученного вознаграждения, а контекстные признаки используются для построения модели, предсказывающей ожидаемое вознаграждение для каждого действия в заданном контексте. Это позволяет алгоритму более эффективно исследовать пространство действий и находить оптимальную политику, максимизирующую суммарное вознаграждение. \mathbb{E}[R] — математическое ожидание вознаграждения.
Использование контекстных признаков в алгоритмах позволяет более точно оценивать базовое распределение вознаграждений и адаптироваться к изменяющимся условиям. Традиционные алгоритмы, не учитывающие контекст, предполагают стационарность среды, что часто не соответствует действительности. Включение информации о текущем состоянии, представленной в виде признаков, позволяет алгоритму формировать более точную модель вероятности получения вознаграждения для каждого действия. Это достигается за счет возможности обучения отдельных моделей для различных контекстов, что повышает эффективность выбора действий и снижает необходимость в длительном периоде исследования для выявления оптимальной стратегии. Фактически, алгоритм может быстро перестраиваться и учитывать изменения в окружающей среде, что особенно важно в нестатичных задачах принятия решений.
Несмотря на использование контекстуальных признаков, алгоритмы контекстуальных бандитов сталкиваются с фундаментальной проблемой баланса между исследованием (exploration) и использованием (exploitation) в динамически изменяющихся средах. Исследование необходимо для обнаружения новых, потенциально более выгодных действий, в то время как использование позволяет максимизировать немедленную награду, основываясь на текущих знаниях. В нестационарной среде, оптимальная стратегия должна динамически адаптировать соотношение между этими двумя подходами: слишком сильный уклон в сторону использования может привести к упущению новых, лучших действий, а чрезмерное исследование — к снижению общей награды. Эффективное решение этой проблемы требует алгоритмов, способных оценивать и учитывать скорость изменения окружающей среды и соответствующим образом корректировать стратегию принятия решений.
Эффективность алгоритмов, применяемых в нестационарных средах, часто оценивается с помощью метрики “Динамическое сожаление” (Dynamic Regret). Данная метрика количественно определяет кумулятивную разницу между суммарным вознаграждением, полученным алгоритмом, и суммарным вознаграждением, которое мог бы получить оптимальный алгоритм, действующий в соответствии с наилучшей политикой. В ходе экспериментов наши адаптивные алгоритмы зондирования — AdaRP-UCB и AdaSP-UCB — продемонстрировали снижение кумулятивного сожаления в 12 из 13 тестовых конфигураций, что подтверждает их эффективность в динамически меняющихся условиях. Dynamic\ Regret = \sum_{t=1}^{T} (r_t^<i> - r_t), где r_t^</i> — вознаграждение оптимальной политики в момент времени t, а r_t — вознаграждение, полученное алгоритмом в момент времени t.
Учет Шума и Обеспечение Надежности
В реальности, получение точного и однозначного сигнала вознаграждения в задачах последовательного принятия решений — скорее исключение, чем правило. Так называемый “шум вознаграждения” является неотъемлемой характеристикой многих практических сценариев, будь то обучение робота, управление финансовыми активами или персонализация рекомендаций. Этот шум может проявляться в виде неточностей сенсоров, субъективности оценок или случайных внешних факторов. Неспособность алгоритмов адекватно учитывать данный шум приводит к принятию неоптимальных решений и снижению общей эффективности системы. Поэтому разработка алгоритмов, устойчивых к “шуму вознаграждения” и способных извлекать полезный сигнал из зашумленных данных, является ключевой задачей современной науки о принятии решений.
Несовершенство сигналов вознаграждения, или так называемый «шум вознаграждения», оказывает существенное влияние на эффективность алгоритмов обучения с подкреплением. По сути, случайные отклонения в получаемых сигналах могут приводить к принятию неоптимальных решений и, как следствие, к разработке стратегий, далеких от наилучших. Алгоритм, подверженный влиянию такого шума, может ошибочно оценивать ценность определенных действий, отдавая предпочтение менее выгодным вариантам или игнорируя наиболее перспективные. Это особенно критично в динамичных средах, где постоянное изменение условий усугубляет проблему, затрудняя адаптацию и приводя к снижению общей производительности системы принятия решений.
Надежные алгоритмы, предназначенные для работы в условиях неопределенности, требуют разработки механизмов, способных эффективно отсеивать случайные помехи и выделять истинный сигнал. В реальных задачах последовательного принятия решений, вознаграждения часто содержат шум, что может существенно ухудшить производительность обучающихся систем и привести к принятию неоптимальных решений. Поэтому, ключевым аспектом является не просто максимизация вознаграждения, а способность алгоритма отличать полезную информацию от случайных отклонений, что позволяет формировать более устойчивые и эффективные стратегии даже в условиях нестабильной среды. Эффективная фильтрация шума позволяет алгоритму более точно оценивать ценность различных действий и, как следствие, принимать более обоснованные решения.
В условиях нестационарных сред, где вознаграждения подвержены шуму и изменяются со временем, минимизация динамического сожаления остается ключевой задачей для алгоритмов принятия решений. Исследования показали, что алгоритм AdaRP-UCB демонстрирует значительное превосходство над RP-UCB, особенно в волатильных условиях. AdaRP-UCB достигает самой высокой частоты выбора теоретически оптимального варианта, что указывает на его способность эффективно отфильтровывать шум и адаптироваться к изменяющимся условиям среды. Этот алгоритм обеспечивает более стабильную и надежную работу в сложных и непредсказуемых ситуациях, где традиционные подходы могут оказаться неэффективными, обеспечивая значительное улучшение общей производительности.
Исследование, представленное в статье, демонстрирует подход к обучению с подкреплением в нестационарных средах, где скрытые состояния требуют активного зондирования. Это напоминает процесс реверс-инжиниринга сложной системы. Как однажды заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». Подобно тому, как преждевременная оптимизация может заблокировать понимание системы, наивное зондирование без адаптации к скрытым состояниям приводит к неэффективности алгоритмов. Статья акцентирует внимание на разработке стратегий, которые минимизируют кумуляльное сожаление, эффективно исследуя пространство состояний и, по сути, взламывая ‘черный ящик’ неопределенности.
Куда двигаться дальше?
Представленные стратегии адаптивного зондирования, несомненно, расширяют возможности обучения в нестационарных средах с латентными состояниями. Однако, подобно любому инструменту, они обнажают новые грани нерешенных проблем. Оценка эффективности зондирования в условиях частичной наблюдаемости или при наличии шума в измерениях остается открытым вопросом. Существующие алгоритмы склонны к оптимизации локальных решений; требуется разработка методов, позволяющих переходить к более глобальному пониманию динамики скрытых состояний.
Очевидным направлением для будущих исследований представляется интеграция с принципами причинно-следственного вывода. Простое обнаружение корреляций между действиями и наградами недостаточно. Необходимо понимать механизмы, управляющие переходом между состояниями, чтобы создавать действительно адаптивные и робастные политики. В конце концов, манипулирование системой требует понимания её внутренних связей, а не просто угадывания закономерностей.
Ограничения текущих подходов в масштабируемости также требуют внимания. При увеличении размерности пространства латентных состояний сложность зондирования возрастает экспоненциально. Разработка приближенных методов, основанных на принципах сжатия информации или разреженных представлений, может стать ключом к практическому применению этих алгоритмов в реальных задачах. В конечном счете, любое ограничение — это приглашение к эксперименту, а не стена.
Оригинал статьи: https://arxiv.org/pdf/2602.05139.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Прогноз нефти
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Сегежа акции прогноз. Цена SGZH
- МФК Займер акции прогноз. Цена ZAYM
- ETF: Двойной успех к 2026 году
- 🤯 Как ход Визы со стейблкоинами заставляет Уолл-стрит нервничать: BitPay раскрывает всё! 🤯
- Самый умный криптовалютный выбор на 500 долларов (XRP)
2026-02-06 22:44