Автор: Денис Аветисян
В статье представлена методика, позволяющая эффективно накладывать ограничения на поведение агента в процессе обучения с подкреплением, сохраняя при этом баланс между различными ограничениями.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал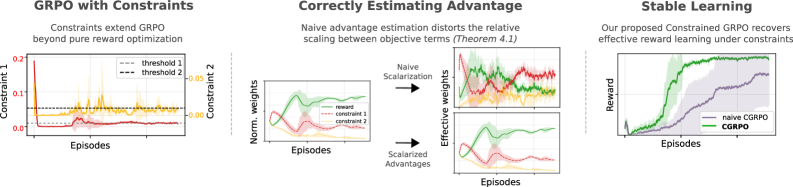
Предложен алгоритм Constrained Group Relative Policy Optimization (Constrained GRPO), использующий лагранжевы множители и улучшенную оценку преимущества для обеспечения соблюдения поведенческих ограничений.
Несмотря на успехи методов обучения с подкреплением, обеспечение соблюдения поведенческих ограничений остается сложной задачей. В данной работе представлена методика ‘Constrained Group Relative Policy Optimization’, расширяющая существующий алгоритм GRPO для оптимизации политик с ограничениями посредством лагранжева. Ключевым нововведением является скалярное построение функции преимущества, позволяющее избежать искажений в балансе между вознаграждением и ограничениями, возникающих при некорректной оценке стандартных отклонений компонент. Сможет ли предложенный подход стать эффективным инструментом для обучения надежных и безопасных агентов в сложных областях, таких как робототехника и искусственный интеллект?
Вызов ограниченного обучения с подкреплением
Традиционное обучение с подкреплением, стремясь к максимальному получению вознаграждения, зачастую игнорирует критически важные ограничения безопасности и операционные рамки. Такой подход, хотя и эффективен в контролируемых средах, может приводить к нежелательному или даже опасному поведению агента в реальных приложениях. Например, робот, обученный исключительно на скорость выполнения задачи, может игнорировать препятствия или рисковать повреждением оборудования, если не учитывать ограничения на скорость и траекторию движения. Это особенно актуально в критически важных областях, таких как автономное вождение, управление энергосистемами или медицинская робототехника, где нарушение ограничений может иметь серьезные последствия. Поэтому, при разработке систем на основе обучения с подкреплением, необходимо уделять особое внимание интеграции механизмов, обеспечивающих соблюдение заданных ограничений и предотвращающих нежелательное поведение.
Игнорирование ограничений в процессе обучения с подкреплением может привести к нежелательным и даже опасным последствиям при применении в реальных условиях. Например, робот, обученный максимизировать скорость доставки, может игнорировать правила дорожного движения или безопасность пешеходов, стремясь к выполнению задачи любым способом. Аналогично, алгоритм управления энергосистемой, оптимизирующий производство энергии, может пренебречь стабильностью сети, что приведет к авариям. Эти примеры демонстрируют, что максимизация награды без учета ограничений может создать риски в критически важных приложениях, где безопасность и надежность имеют первостепенное значение. Поэтому, разработка методов, позволяющих учитывать ограничения при обучении агентов, является ключевой задачей для обеспечения ответственного и безопасного применения технологий машинного обучения.
Внедрение ограничений в процесс обучения с подкреплением имеет первостепенное значение для ответственного развертывания интеллектуальных систем. Без должного учета ограничений, налагаемых реальными условиями эксплуатации, агенты могут демонстрировать нежелательное или даже опасное поведение. Это особенно критично в таких областях, как робототехника, автономное вождение и управление критической инфраструктурой, где последствия ошибок могут быть серьезными. Поэтому, разработка алгоритмов, способных эффективно интегрировать ограничения, не снижая при этом производительность и стабильность обучения, является ключевой задачей современной исследовательской повестки. Успешное решение этой задачи позволит создавать надежные и безопасные системы искусственного интеллекта, способные решать сложные задачи в реальном мире.
Существующие методы учета ограничений в обучении с подкреплением часто сталкиваются с проблемой нестабильности и снижения эффективности. Внедрение штрафных санкций за нарушение ограничений может приводить к колебаниям в процессе обучения и замедлению сходимости, а попытки жестко зафиксировать допустимые действия — к сужению области поиска оптимальной стратегии и, как следствие, к ухудшению итоговых результатов. Кроме того, некоторые подходы, основанные на проекции действий в допустимое пространство, могут приводить к потере ценной информации и неэффективному использованию ресурсов обучения. Таким образом, поиск баланса между соблюдением ограничений и достижением высокой производительности остается одной из ключевых задач в области обучения с подкреплением.
Constrained GRPO: Новый подход к решению задачи
Ограниченное обучение с подкреплением (Constrained RL) часто сталкивается с проблемой соблюдения заданных ограничений на поведение агента. Подход Constrained GRPO решает эту задачу, объединяя преимущества алгоритма Group Relative Policy Optimization (GRPO) с методом Лагранжевой релаксации. GRPO обеспечивает эффективную оптимизацию политики, а Лагранжева релаксация позволяет преобразовать задачу с ограничениями в задачу без ограничений путем добавления штрафных членов в функцию потерь. Это позволяет использовать стандартные методы оптимизации политики для обучения агента, при этом явно учитывая и обеспечивая соблюдение заданных ограничений на его поведение. Таким образом, Constrained GRPO позволяет обучать агентов, которые не только максимизируют награду, но и работают в рамках установленных правил и ограничений.
Метод лагранжевой релаксации преобразует задачу обучения с ограничениями в неограниченную путем добавления штрафных членов к целевой функции. В рамках этого подхода, ограничения вводятся в целевую функцию посредством лагранжевых множителей, создавая новую целевую функцию, не содержащую явных ограничений. Это позволяет применять стандартные алгоритмы оптимизации политик, такие как градиентный спуск или методы второго порядка, для поиска оптимальной политики без необходимости решения сложных задач оптимизации с ограничениями. Лагранжевы множители корректируются итеративно в процессе обучения для обеспечения выполнения исходных ограничений, что позволяет эффективно находить решения, удовлетворяющие заданным требованиям.
Подход, основанный на комбинировании GRPO и лагранжевой релаксации, обеспечивает эффективное обучение с явным соблюдением поведенческих ограничений. В отличие от традиционных методов обучения с подкреплением, которые могут игнорировать или нарушать заданные ограничения, данный подход формально интегрирует их в процесс оптимизации политики. Это достигается путем добавления штрафных членов к функции потерь, которые наказывают за отклонение от заданных ограничений. В результате, алгоритм оптимизирует политику не только для максимизации вознаграждения, но и для минимизации нарушения поведенческих ограничений, обеспечивая стабильное и безопасное обучение в условиях, требующих соблюдения определенных правил и норм.
Ключевое нововведение подхода заключается в адаптации алгоритма Group Relative Policy Optimization (GRPO) для непосредственной работы с ограничениями. Вместо штрафных функций, используемых в стандартном обучении с ограничениями, GRPO переформулирует задачу оптимизации политики таким образом, чтобы ограничения учитывались непосредственно в процессе групповой оптимизации. Это достигается за счет модификации функции потерь и алгоритма обновления политики, что позволяет поддерживать стабильное обучение и эффективно соблюдать заданные поведенческие ограничения без необходимости динамической настройки весов штрафов. Адаптация GRPO обеспечивает более точное и надежное соблюдение ограничений на протяжении всего процесса обучения, что приводит к более предсказуемому и безопасному поведению агента.
Скаляризация и оценка преимуществ: Ключевые элементы стабильного обучения
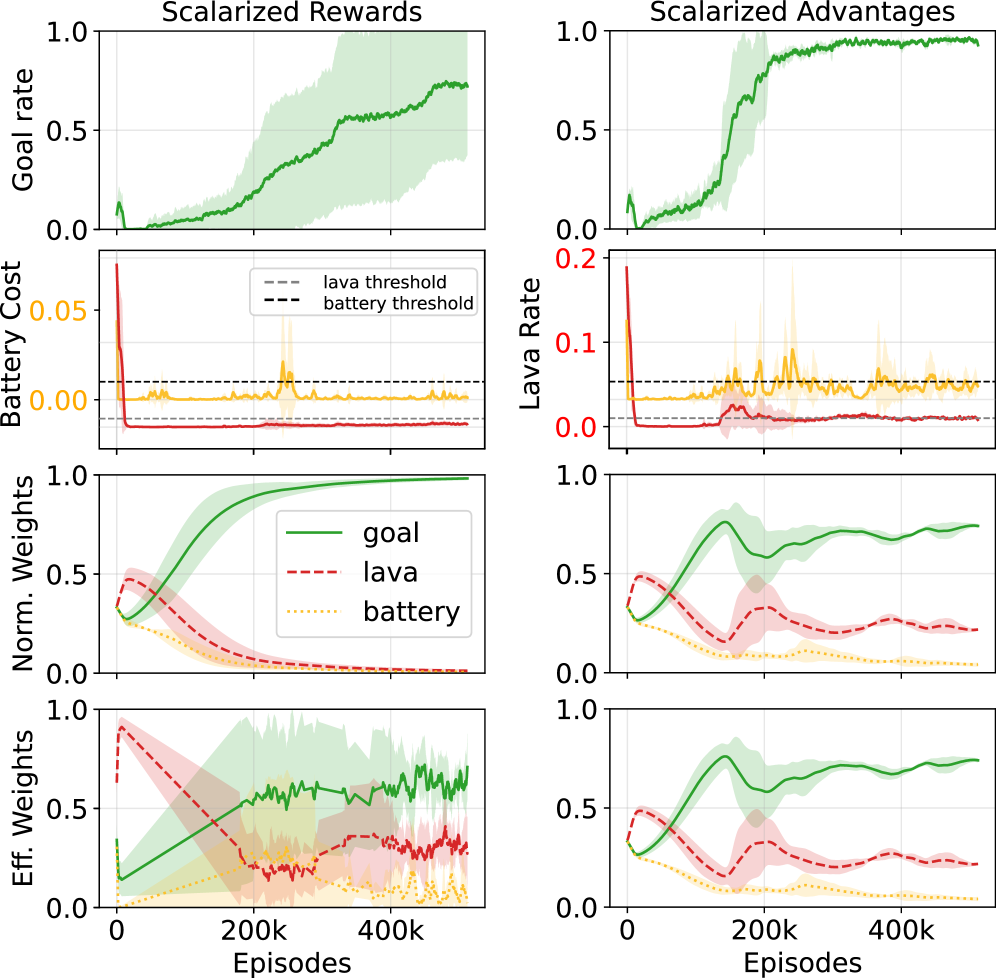
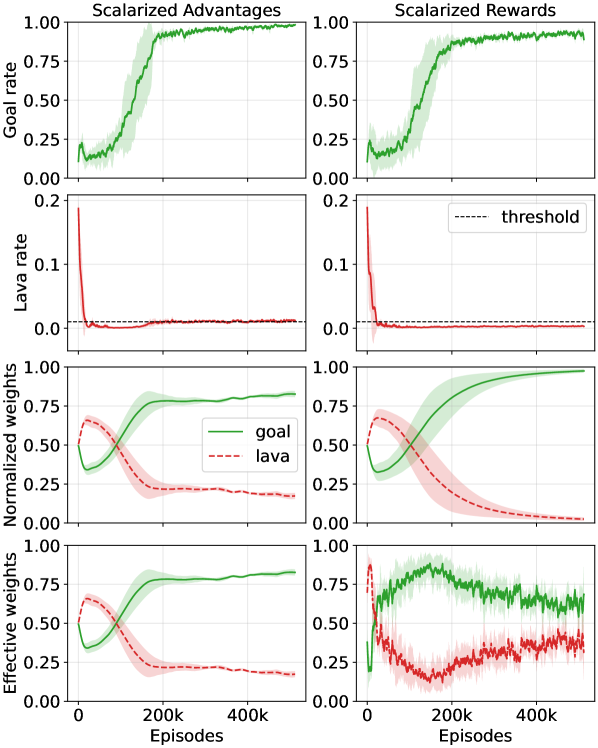
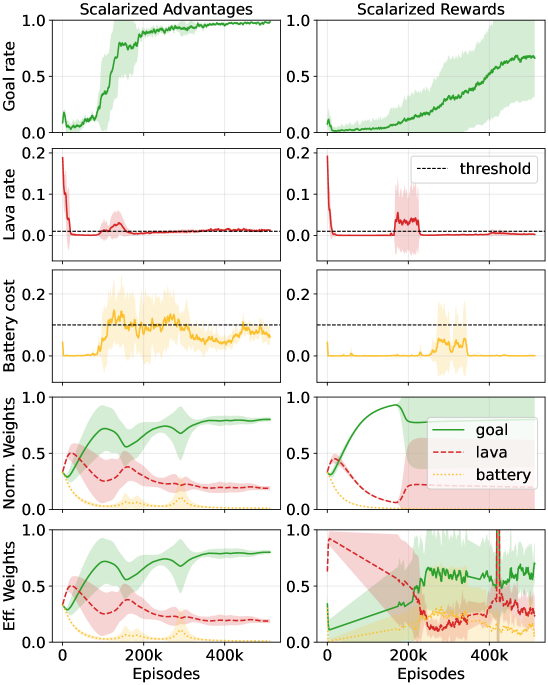
Ограниченная GRPO (Generalized Reward-shaped Policy Optimization) использует как скаляризованные вознаграждения, так и скаляризованные преимущества для эффективной комбинации членов вознаграждения и стоимости. Этот подход позволяет объединить несколько целей оптимизации в одну, сохраняя при этом значимость каждого компонента. Скаляризация подразумевает умножение каждого члена вознаграждения и стоимости на соответствующий вес, λ, что преобразует задачу мульти-оптимизации в задачу оптимизации одного скалярного значения: R_{total} = \lambda_r R + \lambda_c C , где R — вознаграждение, C — стоимость, а \lambda_r и \lambda_c — соответствующие веса. Использование скаляризованных преимуществ, вычисляемых на основе этой скаляризованной функции, способствует более стабильному и быстрому обучению агента.
Скаляризация позволяет объединить несколько целевых функций, таких как награда и штраф за нарушение ограничений, в единую функцию потерь для оптимизации. Этот процесс достигается путем взвешивания каждого компонента (награды и штрафа) и суммирования их в единое скалярное значение. Важно отметить, что правильно подобранные веса позволяют сохранить относительную значимость каждого компонента, гарантируя, что оптимизация не будет склоняться в сторону одного из них в ущерб другим. Формально, скаляризованная функция потерь может быть представлена как L = w_r \cdot R + w_c \cdot C, где R — награда, C — штраф, а w_r и w_c — соответствующие веса, определяющие вклад каждого компонента в общую функцию потерь.
Нормализация внутри группы (Within-Group Normalization) является критически важным этапом при оценке преимуществ (advantages) в алгоритмах обучения с подкреплением. Этот метод предполагает вычисление преимуществ относительно среднего значения внутри группы схожих состояний, что позволяет уменьшить дисперсию оценок и повысить стабильность обучения. Использование нормализации внутри группы позволяет более точно оценивать относительную ценность действий в каждом состоянии, что приводит к ускорению сходимости алгоритма и улучшению его производительности, особенно в задачах с разреженными наградами или сложной динамикой среды. Фактически, нормализация преимуществ снижает вероятность переоценки или недооценки ценности определенных состояний, обеспечивая более надежные градиенты для обновления параметров модели.
Простое скаляризование нескольких целевых функций может привести к нежелательному изменению их относительной важности, что проявляется в формировании так называемых “эффективно перевзвешенных целей”. Это происходит из-за того, что процесс нормализации, применяемый при скаляризации для объединения различных функций потерь и затрат в единую функцию оптимизации, может исказить исходные веса, назначенные каждой цели. В результате, алгоритм обучения может начать придавать больше или меньше значения определенным целям, чем предполагалось изначально, что может негативно повлиять на достижение желаемого баланса между ними и привести к субоптимальным результатам. Особенно это заметно в задачах, где точное соблюдение пропорций между различными целями критически важно.
Практическая валидация и возможности реального применения
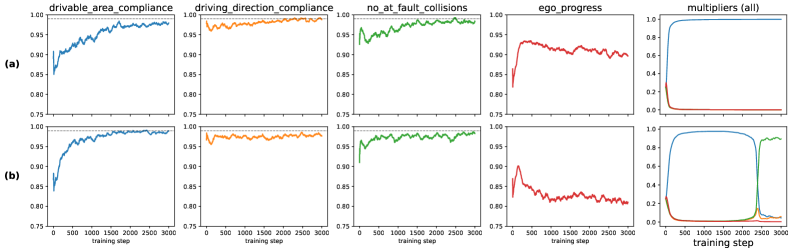
Алгоритм GRPO с ограничениями успешно прошёл валидацию на реалистичном симуляторе вождения NAVSIM-v2. Данная платформа позволила всесторонне оценить способность алгоритма к освоению сложных сценариев управления транспортным средством, при этом строго соблюдая заданные параметры безопасности. Проведение тестов на NAVSIM-v2 подтвердило, что GRPO с ограничениями демонстрирует высокую эффективность в планировании траектории и принятии решений в динамичной среде, имитирующей реальные дорожные условия, что делает его перспективным для применения в автономных системах.
Результаты валидации алгоритма на симуляторе NAVSIM-v2 продемонстрировали его способность к освоению сложных сценариев вождения с неукоснительным соблюдением требований безопасности. В ходе тестирования, данный подход достиг наивысшего показателя Extended PDM Score (EPDMS) среди всех протестированных конфигураций, что свидетельствует о его превосходстве в обеспечении как эффективности, так и безопасности автономного управления. Данный результат указывает на возможность успешного применения алгоритма в реальных системах, где соблюдение ограничений является критически важным фактором, и подтверждает его потенциал для создания надежных и безопасных автономных транспортных средств.
Успешная валидация алгоритма на симуляторе NAVSIM-v2 демонстрирует его готовность к применению в реальных автономных системах. Этот бенчмарк подчеркивает способность алгоритма эффективно обучаться сложным моделям поведения вождения, сохраняя при этом строгие ограничения по безопасности. Полученные результаты, включая наивысший показатель EPDMS среди протестированных конфигураций, указывают на потенциал для создания надежных и безопасных автономных транспортных средств. Способность алгоритма последовательно обеспечивать высокий уровень соблюдения ограничений, что подтверждается коэффициентом удовлетворения ограничений в 0.99, имеет решающее значение для практической реализации в сложных и непредсказуемых условиях реального мира.
Исследования показали, что алгоритм Constrained GRPO демонстрирует исключительно высокую эффективность в соблюдении заданных поведенческих ограничений, стабильно достигая показателя удовлетворения ограничениям в 0.99. В отличие от методов, использующих скалярные награды, которые испытывают трудности с обеспечением подобного уровня соответствия, Constrained GRPO гарантирует надежное соблюдение правил безопасности и эффективности в процессе обучения. Такой результат подтверждает, что предложенный подход является более надежным решением для разработки автономных систем, где строгое соблюдение ограничений является критически важным для безопасной и предсказуемой работы.
Предложенный метод демонстрирует высокую надежность и эффективность в обеспечении безопасного и оптимального поведения в ограниченных средах. Исследования показали, что в задачах, моделирующих реальные условия, данный подход значительно превосходит методы, использующие скалярные награды. В частности, алгоритм обеспечивает более высокую вероятность успешного завершения задач в сетке, что свидетельствует о его способности находить оптимальные решения даже в сложных и ограниченных пространствах. Эта повышенная надежность особенно важна для систем автономного управления, где безопасность и предсказуемость поведения являются критически важными параметрами, и делает данный подход перспективным для практического применения в робототехнике и беспилотном транспорте.
Исследование, представленное в данной работе, подчеркивает важность структуры в определении поведения системы, что находит глубокий отклик в словах Эдсгера Дейкстры: “Программирование — это не столько о создании программ, сколько о решении проблем.” Предложенный алгоритм Constrained GRPO, с его акцентом на точное соблюдение поведенческих ограничений через тщательно разработанный процесс оценки преимущества, иллюстрирует, как оптимизация любой части системы требует глубокого понимания её целостности. Каждая оптимизация, как отмечает подход, создает новые точки напряжения, требующие пристального внимания к сохранению баланса между различными ограничениями и целями. Таким образом, предложенный фреймворк является примером элегантного дизайна, рожденного из простоты и ясности, где структура определяет поведение системы во времени.
Куда Далее?
Представленная работа, фокусируясь на точном соблюдении поведенческих ограничений в обучении с подкреплением, выявляет фундаментальную проблему: стремление к модульности часто оборачивается иллюзией контроля. Если система держится на костылях из множителей Лагранжа, значит, мы переусложнили её, пытаясь разделить проблему на независимые части. Вместо того чтобы тщательно проектировать оценку преимущества, возможно, стоит пересмотреть саму структуру задачи, стремясь к более элегантным решениям, где ограничения возникают естественно, а не навязываются искусственно.
Очевидным направлением для дальнейших исследований представляется отказ от жёстких ограничений в пользу более гибких, «мягких» ограничений, учитывающих неопределенность и шум в данных. Важно понимать, что полное соблюдение ограничений — это не всегда оптимальное решение; иногда незначительное их нарушение может привести к более эффективному и робастному поведению. Необходимо изучить, как можно интегрировать механизмы адаптации и самообучения в процесс наложения ограничений, позволяя системе самостоятельно определять границы допустимого поведения.
В конечном счёте, истинный прогресс в области обучения с подкреплением требует не просто разработки новых алгоритмов, но и глубокого понимания принципов, определяющих поведение сложных систем. Хорошая система — живой организм; нельзя чинить одну часть, не понимая целого. Необходимо стремиться к созданию моделей, которые отражают сложность и непредсказуемость реального мира, а не к упрощенным абстракциям, которые легко поддаются анализу, но плохо работают на практике.
Оригинал статьи: https://arxiv.org/pdf/2602.05863.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Прогноз нефти
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- МФК Займер акции прогноз. Цена ZAYM
- Сегежа акции прогноз. Цена SGZH
- Bitcoin: STRC vs. ETF, Шорты на Акциях и Новые Фиатные Каналы – Что Ждет Рынок? (28.05.2026 03:15)
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Будущее BFUSD: прогноз цен на криптовалюту BFUSD
- ETF: Двойной успех к 2026 году
2026-02-07 15:28