Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий эффективно переносить навыки, полученные в одной среде, в другую, даже при значительных различиях в динамике.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал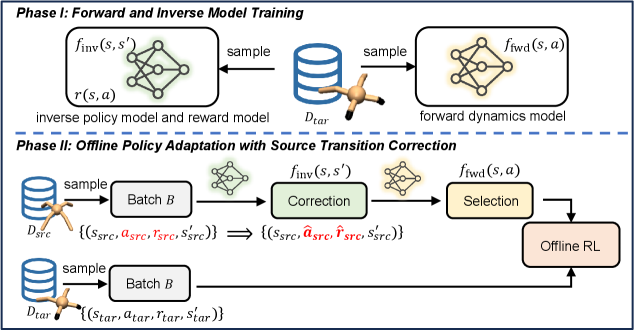
В статье представлен метод Selective Transition Correction (STC) для адаптации политик обучения с подкреплением в офлайн-режиме, использующий модели прямой и обратной динамики для коррекции переходов и уменьшения расхождений между доменами.
Адаптация политик обучения с подкреплением к новым условиям остается сложной задачей, особенно при наличии расхождений в динамике сред. В статье ‘Cross-Domain Offline Policy Adaptation via Selective Transition Correction’ предложен новый подход к кросс-доменному обучению с использованием офлайн-данных, позволяющий эффективно переносить знания из схожей среды-источника в целевую среду. Ключевая идея заключается в коррекции переходов и вознаграждений данных из среды-источника с использованием обратной и прямой моделей динамики, что позволяет уменьшить рассогласование и улучшить адаптацию политики. Насколько предложенный алгоритм Selective Transition Correction (STC) позволит добиться более надежного использования данных из разных источников для обучения интеллектуальных агентов в сложных и изменчивых условиях?
Обучение в офлайн-режиме: вызов несоответствия сред
Обучение с подкреплением вне сети (OfflineRL) представляет собой перспективный подход к созданию интеллектуальных агентов, позволяющий им приобретать навыки исключительно на основе статических наборов данных, без необходимости дорогостоящего и потенциально опасного взаимодействия с окружающей средой в режиме реального времени. Этот метод открывает широкие возможности для применения обучения с подкреплением в тех областях, где сбор данных в режиме реального времени затруднен или невозможен, например, в робототехнике, медицине и финансах. Вместо активного исследования среды, OfflineRL использует существующие записи о взаимодействии, позволяя агенту изучать оптимальную политику, анализируя уже собранную информацию. Такой подход значительно снижает риски, связанные с обучением в реальных условиях, и позволяет использовать данные, полученные от экспертов или из исторических баз данных, для создания высокоэффективных агентов.
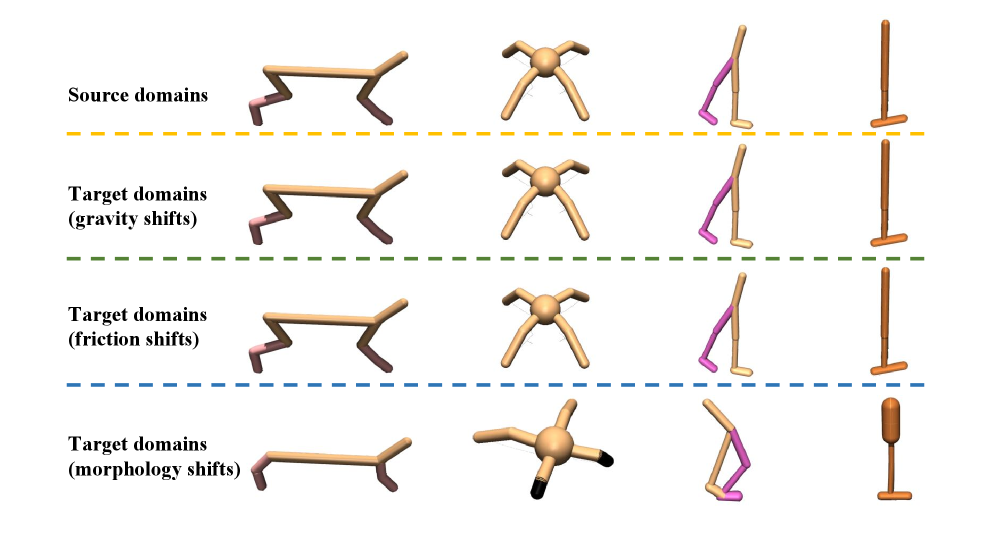
Существенная проблема при применении стратегий, обученных в одной среде — исходной — к другой, целевой, заключается в несоответствии динамики перехода состояний, известном как DynamicsMismatch. Данное расхождение означает, что действия, приводящие к ожидаемому результату в исходной среде, могут приводить к совершенно иным последствиям в целевой. Представьте, что робот обучен вождению по гладкому асфальту, а затем его пытаются использовать на пересеченной местности; изменение условий значительно повлияет на траекторию и эффективность его действий. Данный феномен серьезно ограничивает применимость OfflineRL в реальных сценариях, где условия часто меняются, и требует разработки инновационных методов адаптации и переноса знаний между различными средами.
Существенное ограничение применимости обучения с подкреплением в автономном режиме (OfflineRL) в реальных условиях связано с расхождениями в динамике переходов состояний между обучающей и целевой средами. Иными словами, политика, успешно обученная на одном наборе данных, может демонстрировать неустойчивое или неоптимальное поведение при развертывании в другой среде, где закономерности изменения состояний отличаются. Это несоответствие, известное как DynamicsMismatch, требует разработки инновационных методов адаптации, позволяющих политике эффективно обобщать полученные знания и приспосабливаться к новым, ранее не встречавшимся динамическим условиям. Исследования в этой области направлены на создание алгоритмов, способных выявлять и компенсировать эти расхождения, обеспечивая надежную и безопасную работу автономных систем в разнообразных и непредсказуемых средах.
Существующие подходы и их ограничения: вечный поиск компромисса
Существующие методы адаптации доменов включают в себя такие подходы, как адаптация на основе оптимального транспорта (Optimal Transport for Domain Adaptation, OTDF) и адаптация доменов с использованием обучения с подкреплением (Domain Adaptation with Reinforcement Learning, DARA). OTDF использует концепцию оптимального транспорта для поиска наименее затратного способа преобразования распределения данных из исходного домена в целевой, минимизируя расстояние между ними. DARA, в свою очередь, применяет алгоритмы обучения с подкреплением для обучения агента, способного эффективно функционировать в целевом домене, используя опыт, полученный в исходном домене. Оба подхода направлены на уменьшение расхождения между доменами, однако требуют значительных вычислительных ресурсов и точной настройки параметров для достижения оптимальной производительности.
Многие существующие методы адаптации доменов, такие как Optimal Transport для адаптации доменов (OTDF) и адаптация доменов с использованием обучения с подкреплением (DARA), основываются на выравнивании распределений данных или корректировке функций вознаграждения. Однако, реализация этих подходов часто требует значительных вычислительных ресурсов, особенно при работе с данными высокой размерности или большими объемами данных. Кроме того, для достижения оптимальной производительности необходима тщательная настройка гиперпараметров и архитектуры моделей, что может быть трудоемким и требовать экспертных знаний в предметной области. Недостаточная оптимизация может привести к неэффективному использованию ресурсов и снижению качества адаптации.
Подходы, такие как безопасное обучение с подкреплением с использованием оптимизации политики (SRPO), не решают напрямую проблему различий в динамике между исходной и целевой средами. Вместо этого, SRPO фокусируется на обеспечении безопасности обучения, ограничивая действия агента и штрафуя небезопасное поведение. Хотя это и важно, такая стратегия не учитывает фундаментальные различия в том, как среда реагирует на действия агента, что может приводить к субоптимальной производительности в целевой среде, даже если агент избегает небезопасных действий. Это связано с тем, что политика, обученная в исходной среде, может быть неэффективной в целевой среде из-за отличающихся динамических свойств.
Селективная коррекция переходов: новый взгляд на проблему
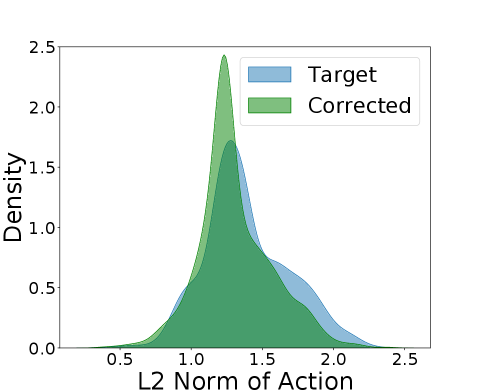
Метод селективной коррекции переходов (STC) представляет собой новый подход в обучении с подкреплением в автономном режиме (OfflineRL) для задач междоменной адаптации. В отличие от существующих методов, STC напрямую корректирует переходы, полученные из исходной области (source domain), для приведения их в соответствие с динамикой целевой области (target domain). Это достигается путем изменения состояний и действий в исходных данных таким образом, чтобы они лучше соответствовали ожидаемым результатам в целевой среде, что позволяет агенту эффективно обучаться на данных, собранных в другой среде, без необходимости взаимодействия с целевой средой в процессе обучения.
Метод Selective Transition Correction (STC) использует модели ForwardDynamicsModel и InversePolicyModel для прогнозирования переходов состояний в целевой среде и выявления расхождений с переходами, полученными из исходной среды. ForwardDynamicsModel предсказывает следующее состояние, основываясь на текущем состоянии и действии, в то время как InversePolicyModel определяет действие, необходимое для достижения определенного целевого состояния. Сравнивая предсказанные переходы целевой среды с переходами исходной среды, STC точно определяет области, где динамика различается, что позволяет применять целенаправленные корректировки для адаптации стратегии к новой среде. Данный подход позволяет эффективно выявлять и количественно оценивать расхождения в динамике между средами, что является ключевым для успешного переноса обучения.
Для оценки влияния вносимых коррекций на траектории, алгоритм Selective Transition Correction (STC) использует разложение Тейлора f(x + \Delta x) \approx f(x) + f'(x)\Delta x. Это позволяет аппроксимировать изменение состояния системы после применения коррекции. Механизм SelectiveCorrection анализирует полученную оценку изменения и применяет коррекцию только в том случае, если прогнозируется улучшение производительности, предотвращая ухудшение результатов обучения и обеспечивая стабильность алгоритма. Коррекции, которые, согласно оценке разложения Тейлора, приводят к снижению ожидаемой награды, отбрасываются.
Метод Selective Transition Correction (STC) эффективно снижает влияние несоответствия динамики (DynamicsMismatch) между исходной и целевой средами, корректируя переходы (transitions) в данных OfflineRL. В ходе тестирования на различных средах, применение STC позволило достичь суммарного нормализованного результата в 1045.2, что демонстрирует значительное улучшение производительности по сравнению с подходами, не учитывающими расхождения в динамике. Данный показатель подтверждает, что фокусировка на коррекции переходов является эффективной стратегией для решения проблемы DynamicsMismatch и повышения надежности обучения в задачах Offline Reinforcement Learning.
Влияние и перспективы: когда теория встречается с практикой
Эффективно решая проблему несоответствия динамики (DynamicsMismatch), разработанный метод STC значительно расширяет возможности обучения с подкреплением в режиме офлайн (OfflineRL) для широкого спектра практических задач. Суть заключается в преодолении ограничений, возникающих при переносе данных, полученных в одной среде, для обучения агента в принципиально иной. Благодаря этому, STC позволяет успешно применять накопленный опыт, например, данные симуляций, к реальным системам, где динамика может существенно отличаться. Это открывает перспективы для автоматизации сложных процессов, обучения роботов в новых условиях и разработки интеллектуальных систем управления, способных адаптироваться к изменяющимся обстоятельствам без необходимости дорогостоящего и длительного сбора данных в каждой конкретной среде.
В отличие от существующих методов адаптации доменов, требующих значительных вычислительных ресурсов для глобальной корректировки данных, разработанный подход делает акцент на целенаправленной коррекции переходов. Это позволяет не только повысить эффективность обучения с подкреплением в условиях расхождений между доменами, но и обеспечить устойчивость к шумам и неточностям в данных. Вместо того, чтобы переобучать модель для каждого нового домена, система фокусируется на исправлении лишь тех переходов, которые существенно отличаются, что значительно снижает вычислительную сложность и позволяет применять алгоритм в задачах с ограниченными ресурсами. Такой подход демонстрирует превосходство над традиционными методами, обеспечивая более быструю адаптацию и надежные результаты даже в сложных условиях.
Предложенный метод STC демонстрирует значительное превосходство над существующими алгоритмами в задачах обучения с подкреплением в офлайн-режиме. В ходе экспериментов STC показал лучшие результаты в двенадцати различных задачах, превосходя все базовые модели по ключевым показателям эффективности. При этом, вычислительные затраты, связанные с применением STC, остаются сопоставимыми с затратами других методов, что делает его практичным решением для широкого круга приложений. Данное сочетание высокой производительности и умеренных вычислительных требований делает STC особенно привлекательным для задач, где ресурсы ограничены, а надежность и точность критически важны.
Дальнейшие исследования сосредоточены на расширении возможностей STC для работы с более сложными динамическими системами и изучении его применимости к задачам непрерывного управления. Ученые планируют исследовать методы адаптации алгоритма к средам, характеризующимся высокой степенью нелинейности и стохастичности, что позволит применять его в более реалистичных и сложных сценариях, таких как робототехника и автономное вождение. Особое внимание будет уделено разработке алгоритмов, способных эффективно корректировать переходы состояний в непрерывном пространстве действий, что является ключевой задачей для успешного применения STC в задачах, требующих высокой точности и плавности управления. Ожидается, что подобные исследования откроют новые возможности для создания более адаптивных и надежных систем обучения с подкреплением, способных бесшовно функционировать в разнообразных условиях.
Представленная работа закладывает основу для создания принципиально новых систем обучения с подкреплением, способных к адаптации и надежной работе в разнообразных условиях. Преодолевая ограничения существующих алгоритмов, которые часто демонстрируют хрупкость при переносе в незнакомые среды, данное исследование открывает перспективы для разработки интеллектуальных агентов, способных эффективно обучаться на одних данных и успешно применять полученные навыки в совершенно иных ситуациях. Это достигается благодаря созданию более гибкой и устойчивой архитектуры, позволяющей системе не просто адаптироваться к новым условиям, но и сохранять высокую производительность, что является ключевым фактором для практического применения в реальном мире, от робототехники до автономных систем управления.
Изучение методов адаптации политик в обучении с подкреплением без учителя неизбежно наталкивает на мысль о хрупкости любой модели. Авторы предлагают Selective Transition Correction (STC) — подход, направленный на исправление переходов в исходной области, чтобы уменьшить расхождение в динамике. Это, конечно, элегантное решение, но оно лишь откладывает неизбежное. Как заметил Дональд Кнут: «Прежде чем ты сможешь оптимизировать что-либо, ты должен сначала измерить». И даже после измерений, продакшен всегда найдёт способ доказать, что теоретическая модель несовершенна. В данном случае, STC пытается скорректировать динамику, но реальный мир всегда будет сложнее любой модели, даже самой изощрённой.
Что дальше?
Представленная работа, безусловно, добавляет ещё один инструмент в арсенал offline обучения с подкреплением. Коррекция переходов — элегантная идея, но, как показывает опыт, элегантность часто разбивается о суровую реальность данных. Неизбежно возникнет вопрос: насколько надежны эти модели динамики, когда речь пойдёт о действительно сложных средах? Будет ли коррекция переходов просто сглаживанием ошибок, маскирующим более глубокие проблемы с представлением мира агентом? В конце концов, багтрекер — это дневник боли, и даже самые изящные алгоритмы не избавят от необходимости копаться в логах.
Очевидно, что ключевым направлением станет работа с неопределённостью. Модели динамики всегда будут лишь приближением к истине. Как эффективно учитывать эту неопределённость при коррекции переходов? Как предотвратить переобучение на шуме и выбросах? Вероятно, потребуются более сложные механизмы регуляризации и методы оценки доверия к предсказаниям моделей. Иначе мы просто построим более изощрённый способ убедить себя, что хаос управляем.
В конечном итоге, стоит помнить: мы не деплоим — мы отпускаем. И никакая коррекция переходов не гарантирует, что агент не найдёт способ сломаться самым неожиданным образом. Поэтому, помимо теоретических изысканий, необходимы инструменты для мониторинга, диагностики и быстрого восстановления после сбоев. Иначе каждая «революционная» технология завтра станет техдолгом.
Оригинал статьи: https://arxiv.org/pdf/2602.05776.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Nvidia: О дроблениях акций и призраках биржи
- Будущее FET: прогноз цен на криптовалюту FET
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- АЛРОСА акции прогноз. Цена ALRS
- Российский рынок: между геополитикой, инфляцией и корпоративной прибылью (23.03.2026 11:33)
- Что такое дивидендный гэп и как на этом заработать
- Российский рынок: Снижение производства, стабильный банковский сектор и ускорение инфляции (26.03.2026 01:32)
- Супернус: Продажа Акций и Нервные Тики
- Будущее SKY: прогноз цен на криптовалюту SKY
2026-02-08 06:38