Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий языковым моделям сохранять разнообразие стратегий рассуждений и избегать «коллапса» в процессе обучения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал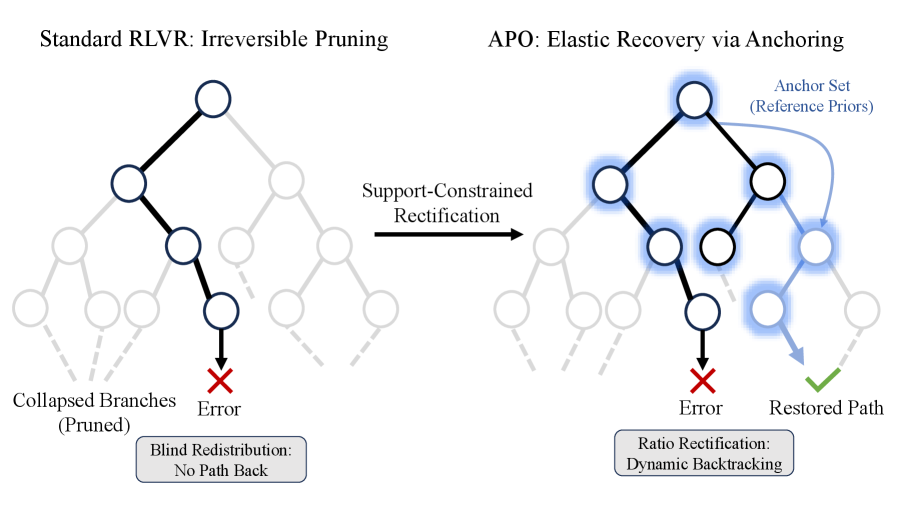
В статье представлена Anchored Policy Optimization (APO) — техника, поддерживающая и восстанавливающая «поддержку» валидных путей рассуждений, что повышает производительность и надежность моделей.
Несмотря на успехи обучения с подкреплением с верифицируемыми наградами (RLVR), часто возникающая проблема — коллапс пространства поиска оптимальных решений. В работе, озаглавленной ‘Anchored Policy Optimization: Mitigating Exploration Collapse Via Support-Constrained Rectification’, авторы исследуют эту проблему и предлагают новый подход — Anchored Policy Optimization (APO), который позволяет поддерживать разнообразие исследуемых стратегий, активно восстанавливая поддержку валидных путей рассуждений. Теоретически обосновано, что APO максимизирует покрытие пространства решений, обеспечивая эластичное восстановление и улучшая показатели точности и разнообразия. Сможет ли предложенный метод стать эффективным инструментом для обучения больших языковых моделей, требующих надежного и гибкого поиска оптимальных стратегий?
Пределы Формы: Рассуждения в Больших Языковых Моделях
Обучение с подкреплением, основанное на проверяемых наградах (RLVR), представляется перспективным подходом к улучшению способности больших языковых моделей к рассуждениям. Однако существующие методы сталкиваются с принципиальными ограничениями, препятствующими полному раскрытию потенциала этой технологии. Несмотря на видимый прогресс в решении конкретных задач, RLVR часто оказывается неспособным обеспечить устойчивый и обобщенный рост логических способностей модели. Проблема заключается в том, что существующие алгоритмы, стремясь к немедленной оптимизации, оказываются слишком жесткими и не позволяют модели исследовать широкий спектр возможных решений, ограничивая её способность к адаптации и творческому мышлению. В результате, несмотря на кажущуюся эффективность в краткосрочной перспективе, RLVR может оказаться неэффективным для решения более сложных и многогранных задач, требующих глубокого анализа и нестандартного подхода.
Существенная проблема обучения с подкреплением и проверяемыми наградами (RLVR) заключается в тенденции усиливать уже существующие пути рассуждений, известной как «обрезка дерева» (Tree Pruning). Вместо поиска новых, альтернативных решений, модель концентрируется на оптимизации знакомых последовательностей шагов. Это происходит из-за того, что система вознаграждения поощряет шаги, которые кажутся логичными в контексте уже пройденного пути, что приводит к игнорированию потенциально более эффективных, но менее очевидных стратегий. Таким образом, RLVR рискует зафиксировать модель в локальном оптимуме, ограничивая её способность к настоящему инновационному решению задач и снижая общую гибкость рассуждений.
Усиление существующих путей рассуждений, вызванное жесткими ограничениями в процессе обучения с подкреплением, приводит к феномену рекурсивного сужения пространства поиска решений. Изначально направленное на оптимизацию, это явление фактически ограничивает способность модели исследовать альтернативные, потенциально более эффективные стратегии. Вместо расширения горизонтов, модель, стремясь к немедленному вознаграждению, концентрируется на уже известных подходах, постепенно «схлопывая» пространство возможных рассуждений. В результате, даже при кажущемся улучшении производительности в конкретных задачах, общая способность модели к гибкому и новаторскому решению проблем существенно снижается, препятствуя ее адаптации к новым и сложным вызовам.
![В отличие от методов регуляризации, ограничивающих плотность вероятности жесткими ограничениями или вызывающих коллапс в узкий путь, наш подход максимизирует покрытие безопасной области [latex]\mathcal{M}_{safe}[/latex], позволяя агрессивное повышение точности и обеспечивая эластичное восстановление при коррекции ошибок для предотвращения выхода за пределы допустимых регионов.](https://arxiv.org/html/2602.05717v1/x1.png)
Патология Сокращения: Почему Стандартные Методы Неэффективны
Попытки противодействовать рекурсивному сжатию пространства с использованием методов, таких как усиление отрицательных примеров (Negative Sample Reinforcement), оказываются неэффективными, поскольку они не затрагивают базовый механизм слепого перераспределения. Данные методы фокусируются на корректировке выходных данных без устранения причины, по которой модель изначально стремится к сжатию пространства признаков. Слепое перераспределение заключается в том, что модель произвольно переназначает векторы признаков, не учитывая семантическую близость или структуру данных, что приводит к потере различительной способности и ухудшению обобщающей способности. В результате, даже при использовании усиления отрицательных примеров, модель продолжает сжимать пространство признаков, игнорируя полезную информацию и ухудшая качество представления данных.
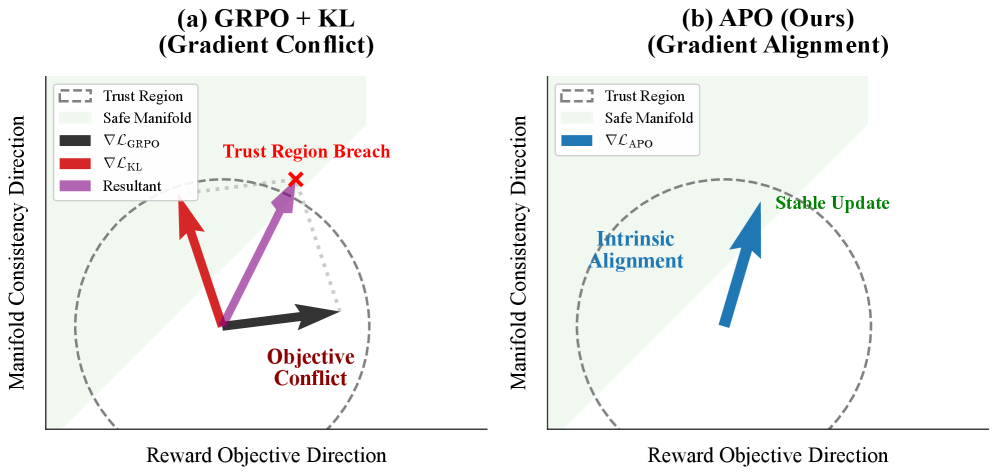
Широко используемая регуляризация Кульбака-Лейблера, предназначенная для стабилизации процесса обучения, парадоксальным образом усугубляет проблему рекурсивного сжатия пространства признаков. Это происходит из-за того, что регуляризация накладывает жесткие ограничения на соответствие форм распределений, заставляя модель стремиться к точному воспроизведению целевых распределений, а не к их исследованию. В результате, даже небольшие отклонения от целевых форм наказываются, что ограничивает способность модели к адаптации и приводит к сужению пространства представлений, препятствуя эффективному обучению и обобщающей способности.
Жесткость, вносимая Kullback-Leibler регуляризацией, приводит к конфликту градиентов, когда штраф за регуляризацию противодействует сигналу вознаграждения. Это происходит из-за того, что регуляризация накладывает строгие ограничения на соответствие форм, что препятствует исследованию пространства решений. В результате, градиент, стремящийся к улучшению модели на основе сигнала вознаграждения, ослабляется или даже нейтрализуется градиентом, вызванным штрафом за отклонение от заданного распределения. Такой конфликт градиентов ухудшает процесс обучения, подавляет способность модели к эффективному исследованию и способствует дальнейшей рекурсивной контракции пространства представлений.
Якорение Оптимизации Политики: Сдвиг к Покрытию
Оптимизация политики с привязкой (APO) представляет собой новый подход, отходящий от жесткого сопоставления форм и направленный на максимизацию покрытия «Безопасного Многообразия» — множества высоконадежных обоснований референсной модели. Вместо того, чтобы ограничивать поиск решений рамками, точно соответствующими референсным данным, APO стремится расширить область исследования, охватывая более широкий спектр возможных, но достоверных, стратегий. Это позволяет политике находить решения, которые могут быть не идентичны референсным, но остаются в пределах области высокой уверенности, определяемой референсной моделью, что повышает надежность и адаптивность системы.
Оптимизация на основе целевой функции покрытия поддержки (Support Coverage Objective) в Anchored Policy Optimization (APO) направлена на расширение области исследования политики за пределы жесткого соответствия форме. Вместо минимизации отклонений от эталонной модели, APO явно стимулирует политику исследовать и поддерживать широкое распределение по пространству уверенного рассуждения эталонной модели. Это достигается путем поощрения политики к посещению разнообразных состояний, в которых эталонная модель демонстрирует высокую уверенность, что позволяет повысить устойчивость и обобщающую способность агента. Фактически, алгоритм максимизирует вероятность выбора действий, которые соответствуют уверенным прогнозам эталонной модели, что ведет к повышению эффективности.
Оптимизация с привязкой (APO) основывается на методе Group Relative Policy Optimization (GRPO), используя его стабильность и расширяя его возможности. В отличие от GRPO, который может ограничивать пространство поиска рассуждений, APO фокусируется на его расширении, поощряя политику исследовать более широкий спектр возможных решений в пределах доверительного пространства эталонной модели. Данный подход позволяет достичь улучшения до 6% в метрике Pass@1, демонстрируя повышение эффективности за счет более полного охвата пространства рассуждений.

Исправление Соотношения: Возвращение Утерянных Путей Рассуждений
В основе алгоритма APO лежит техника, получившая название Ratio Rectification, которая заключается во внедрении корректирующей силы в отношение политики (policy ratio). Эта сила направлена на выравнивание градиентов с сигналом вознаграждения, эффективно противодействуя проблеме конфликта градиентов. Суть подхода заключается в том, чтобы, изменяя отношение политики, подтолкнуть процесс обучения в направлении, где градиенты более точно отражают желаемое поведение модели, тем самым оптимизируя ее способность к рассуждениям и принятию решений. По сути, Ratio Rectification позволяет модели более эффективно использовать информацию о вознаграждении, избегая ситуации, когда градиенты «растягиваются» или «сжимаются» из-за несовпадения между политикой и функцией вознаграждения, что приводит к более стабильному и эффективному обучению.
Механизм, известный как «Эластичное восстановление», позволяет преодолеть проблему рекурсивного сжатия пространства в больших языковых моделях. В отличие от традиционных методов, требующих точного соответствия плотности вероятностей, данная техника восстанавливает ранее упущенные ветви рассуждений, предоставляя модели гибкость в исследовании различных путей решения задачи. Это достигается за счет активного восстановления забытых направлений поиска, что позволяет избежать преждевременной концентрации на ограниченном подмножестве возможных решений. В результате, модель получает возможность более полно охватить пространство вариантов, повышая свою надежность и способность находить оптимальные ответы даже в сложных ситуациях.
Метод APO демонстрирует значительное повышение надежности и расширение спектра рассуждений в больших языковых моделях за счет приоритезации охвата и активной коррекции градиентов. Исследования показывают, что APO позволяет восстановить от 1,5% до 3,3% разнообразия в метрике Pass@K, которое обычно теряется при использовании стандартных методов градиентной политики. При этом, достигается показатель Pass@1 в 50.67%, что свидетельствует о существенном улучшении способности модели находить правильные решения и демонстрировать более широкую перспективу в процессе рассуждений. Данный подход позволяет моделям более эффективно исследовать различные варианты и избегать зацикливания на ограниченном наборе решений.
![Алгоритм APO демонстрирует превосходство над базовыми моделями на Qwen2.5-Math-7B, достигая наилучшей эффективности Pass@1 и восстанавливая разнообразие решений, в отличие от стандартного GRPO, где повышение эффективности приводит к снижению покрытия ([latex]Pareto Improvement[/latex]).](https://arxiv.org/html/2602.05717v1/x4.png)
Исследование, представленное в данной работе, демонстрирует важность поддержания разнообразия в процессе обучения моделей подкрепления. Авторы предлагают подход APO, направленный на предотвращение коллапса поддержки, что критически важно для обеспечения стабильности и эффективности обучения больших языковых моделей. В этой связи вспоминается высказывание Дональда Дэвиса: «Все системы стареют — вопрос лишь в том, делают ли они это достойно». Подобно тому, как система требует постоянного внимания и адаптации для сохранения своей функциональности, так и языковая модель нуждается в активном управлении своим «пространством решений» (support coverage), чтобы избежать деградации и сохранить способность к эффективному рассуждению и генерации. Забота о поддержке валидных путей рассуждений является залогом «достойной старости» модели, обеспечивая её долговечность и устойчивость к изменениям.
Куда же дальше?
Представленная работа, как и любая попытка обуздать сложность, лишь обнажает новые грани нерешенных вопросов. Проблема «коллапса исследования» в контексте больших языковых моделей, хоть и смягчена предложенным подходом к поддержанию «поддержки» валидных путей рассуждений, остается симптомом более глубокой болезни — неспособности систем сохранять разнообразие в процессе адаптации. Время, как среда, в которой неизбежно возникают ошибки, требует не только исправления этих ошибок, но и сохранения памяти о пройденных путях, даже если они оказались тупиковыми.
Очевидно, что дальнейшее развитие потребует не только усовершенствования алгоритмов «восстановления», но и переосмысления самой концепции «исследования». Необходимо исследовать, как можно интегрировать механизмы, имитирующие биологическую «устойчивость» — способность системы сохранять функциональность даже при значительных повреждениях. В конечном итоге, речь идет не о создании «идеального» алгоритма, а о создании системы, способной достойно стареть, извлекая уроки из своих ошибок и адаптируясь к меняющимся условиям.
Предложенный метод, безусловно, является шагом вперед, но он лишь подчеркивает, что истинный прогресс заключается не в устранении случайности, а в ее принятии как неотъемлемой части любого эволюционирующего процесса. Время рассудит, насколько эффективными окажутся эти попытки, но очевидно, что поиск баланса между «исследованием» и «эксплуатацией» останется вечной проблемой для исследователей в области искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.05717.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Россети Центр и Приволжье акции прогноз. Цена MRKP
- Эффективный поиск максимума субмодулярных функций с ограничениями
- Европейский путь Форда: надежда в китайском партнерстве
- Сегежа акции прогноз. Цена SGZH
- Figma: Красота акций и цена, достойная сатиры
- Российский рынок: Рубль растет, облигации ждут взлета, а сектор сырья под давлением (27.03.2026 12:32)
- Netflix: Рост Подписчиков и Нарастающие Риски
- Nu Holdings: 2026 – Год Безумия и Дивидендов
- РУСАЛ акции прогноз. Цена RUAL
2026-02-08 08:18