Автор: Денис Аветисян
Новый подход позволяет стабилизировать процесс обучения больших языковых моделей на основе предпочтений человека, делая их более надежными и соответствующими ожиданиям.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал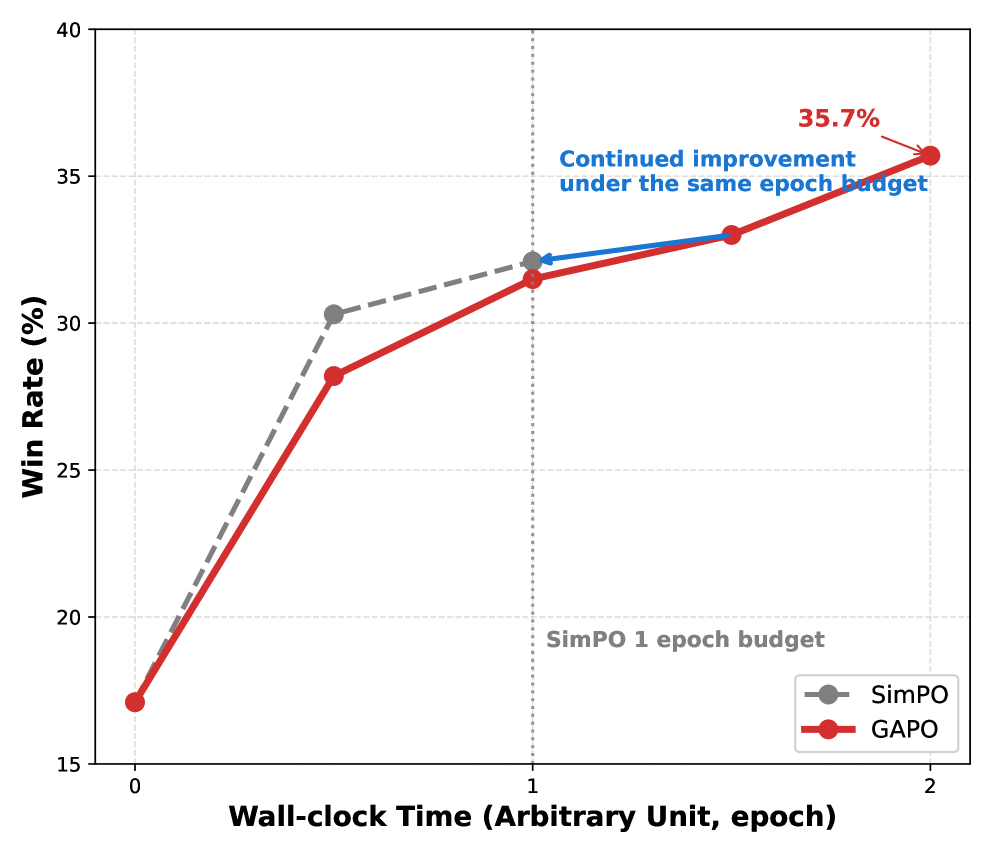
В статье представлена методика геометрического привязывания (GAPO), повышающая устойчивость и качество обучения моделей на основе обратной связи от человека, путем сравнения текущей политики с пессимистичным локальным суррогатом.
Несмотря на успехи методов оптимизации предпочтений, таких как DPO, статичные эталонные политики быстро теряют калибровку, усиливая влияние ложных сигналов в зашумленных данных. В работе ‘Learning Where It Matters: Geometric Anchoring for Robust Preference Alignment’ предложен новый подход — Geometric Anchor Preference Optimization (GAPO), заменяющий фиксированный эталон динамическим «якорем», представляющим собой локальное возмущение текущей политики. Этот метод позволяет адаптировать вес каждого предпочтения, опираясь на его локальную чувствительность и приближая оценку наихудшего локального ухудшения маржи. Способен ли GAPO обеспечить более стабильное и качественное выравнивание больших языковых моделей в условиях реальных зашумленных данных и сложных задач?
Основы Оптимизации Предпочтений: Путь к Интеллекту
В настоящее время обучение языковых моделей всё чаще опирается на непосредственные предпочтения пользователей, выраженные через попарные сравнения — так называемые данные о попарных предпочтениях. Этот подход позволяет моделям не просто генерировать текст, соответствующий статистическим закономерностям, но и адаптироваться к субъективным оценкам качества, таким как полезность, релевантность или креативность. Вместо прямого указания «правильного» ответа, пользователи сравнивают два варианта ответа, выбирая более предпочтительный. Эти данные, аккумулированные в больших объемах, формируют основу для обучения моделей, позволяя им постепенно «улавливать» тонкости человеческих вкусов и генерировать текст, который с большей вероятностью будет воспринят как качественный и полезный. Подобный метод обучения открывает новые возможности для создания действительно «умных» и ориентированных на пользователя языковых моделей.
Методы, такие как DPO (Direct Preference Optimization) и SimPO (Simple Preference Optimization), используют данные о предпочтениях, полученные в результате парных сравнений, посредством минимизации Logistic Loss. Однако, процесс оптимизации, основанный на этом подходе, может быть подвержен определенным сложностям. Нестабильность обучения часто возникает из-за чувствительности к выбору гиперпараметров и начальных условий, что может приводить к колебаниям и замедлению сходимости. Кроме того, значительные различия в структуре данных о предпочтениях или наличие выбросов могут усугубить эти проблемы, требуя применения дополнительных методов регуляризации и адаптации скорости обучения для обеспечения надежной и эффективной оптимизации.
Метод SimPO представляет собой усовершенствование подхода DPO к обучению языковых моделей на основе предпочтений пользователей. В отличие от DPO, требующего наличия эталонной политики Reference Policy, SimPO обходится без неё, что значительно упрощает процесс обучения и повышает его гибкость. Ключевым нововведением является применение нормализации по длине Length Normalization, которая стабилизирует сигналы вознаграждения. Это достигается за счет корректировки оценок, учитывающей длину генерируемого текста, что предотвращает предвзятость в сторону более коротких или длинных ответов и обеспечивает более надежное и эффективное обучение модели, лучше соответствующее предпочтениям пользователей.
Геометрическая Устойчивость: Залог Надежности Оптимизации
Геометрическая устойчивость является ключевым показателем успешной оптимизации предпочтений, определяя способность выученной политики сохранять свою эффективность при небольших возмущениях входных данных или параметров. Данный показатель оценивает, насколько незначительные изменения в обучающей выборке или конфигурации системы влияют на стабильность и предсказуемость поведения модели. Высокая геометрическая устойчивость свидетельствует о том, что политика не переобучена и способна к обобщению на новые, ранее не встречавшиеся данные, что критически важно для надежной работы в реальных условиях.
Стабильная политика, в контексте оптимизации предпочтений, характеризуется способностью избегать переобучения на обучающих данных и, как следствие, демонстрирует улучшенную обобщающую способность на новых, ранее не встречавшихся данных. Переобучение возникает, когда модель слишком точно адаптируется к специфическим особенностям обучающей выборки, что приводит к снижению производительности на независимом наборе данных. Стабильная политика, напротив, сохраняет приемлемую производительность даже при небольших изменениях во входных данных или предпочтениях, что делает ее более надежной и предсказуемой в реальных условиях эксплуатации. Это достигается за счет снижения чувствительности модели к шуму и выбросам в данных.
Высокая плоскостность (Flatness) ландшафта функции потерь, оцениваемая с помощью гессиана \nabla^2 Loss, является сильным индикатором устойчивости (Robustness) обученной политики. Гессиан представляет собой матрицу вторых частных производных функции потерь и характеризует кривизну ландшафта. Низкие собственные значения гессиана указывают на более плоские области, где небольшие возмущения входных данных приводят к небольшим изменениям в значениях функции потерь и, следовательно, в поведении политики. В отличие от этого, высокие собственные значения указывают на крутые, узкие минимумы, которые чувствительны к возмущениям и могут привести к переобучению и плохой обобщающей способности. Таким образом, максимизация плоскостности ландшафта потерь способствует созданию более устойчивых и обобщающих моделей.
GAPO: Стабилизация Обучения Предпочтений через Пессимизм
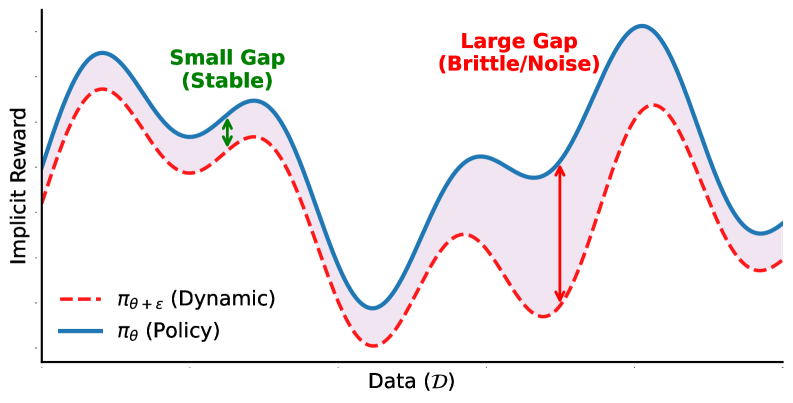
Метод GAPO использует концепцию “пессимистичного локального суррогата” (anchor), представляющего собой локальную аппроксимацию текущей политики в заданном радиусе. Этот anchor формируется таким образом, чтобы моделировать наихудший сценарий поведения в окрестности текущей политики. Фактически, это создает своего рода “пессимистичную” версию политики, которая учитывает потенциальные неблагоприятные изменения в параметрах модели. Использование этого anchor позволяет GAPO более консервативно оценивать качество действий и избегать переобучения, особенно в областях с высокой неопределенностью или нестабильностью.
Разрыв якоря (Anchor Gap) вычисляется как разница между неявной наградой (Implicit Reward), полученной текущей политикой, и неявной наградой, полученной в точке якоря. Этот разрыв используется для адаптивного взвешивания функции логистических потерь (Logistic Loss). Увеличение разрыва якоря приводит к увеличению веса потерь, что способствует более осторожному обновлению политики в областях, где неопределенность высока. Напротив, уменьшение разрыва якоря снижает вес потерь, позволяя политике более свободно исследовать пространство действий. Таким образом, механизм разрыва якоря динамически регулирует процесс обучения, фокусируясь на областях, где политика наиболее чувствительна к изменениям, и обеспечивая более стабильное и надежное обучение.
Метод GAPO способствует обучению политик с повышенной геометрической стабильностью и улучшенной обобщающей способностью, явно учитывая локальную нестабильность в процессе обучения. Это достигается за счет адаптивного взвешивания логистических потерь на основе разницы в неявной награде между текущей политикой и ее «якорем» (Pessimistic Local Surrogate). В ходе экспериментов, GAPO продемонстрировал более высокие результаты в метрике AlpacaEval 2.0 по сравнению с базовыми методами, что подтверждает повышение качества обобщения и устойчивости полученных политик.
Влияние GAPO: Интеграция, Адаптация и Превосходство
Система GAPO разработана с учетом возможности бесшовной интеграции в существующие конвейеры оптимизации предпочтений. В её основе лежит алгоритм Stochastic Gradient Descent (стохастический градиентный спуск), обеспечивающий эффективное и оперативное обновление параметров модели. Такой подход позволяет избежать дорогостоящих переобучений и значительно ускорить процесс адаптации к новым данным и предпочтениям пользователей. Благодаря использованию стохастического градиентного спуска, GAPO демонстрирует высокую производительность даже при работе с большими объемами данных, что делает её идеальным решением для динамически меняющихся сред и приложений, требующих быстрой реакции на изменения.
Адаптивная схема перевзвешивания, основанная на величине “Якорь-Разрыв” Anchor Gap, предоставляет возможность точного контроля над процессом обучения. Данный механизм динамически корректирует веса различных элементов в процессе оптимизации, уделяя больше внимания тем, которые наиболее существенно влияют на достижение желаемого результата. Вместо использования фиксированных весов, система непрерывно оценивает разницу между текущим состоянием модели и заданным “якорем” — целевым значением или предпочтением. Более значительные разрывы приводят к более весомой корректировке соответствующих параметров, что позволяет модели быстро адаптироваться к изменяющимся условиям и эффективно избегать локальных оптимумов. Такой подход обеспечивает не только повышение скорости обучения, но и улучшение обобщающей способности модели, позволяя ей сохранять высокую точность даже при наличии шума или неполных данных.
Экспериментальные исследования последовательно демонстрируют превосходство GAPO над базовыми методами в отношении устойчивости и обобщающей способности. Данный подход позволяет создавать более надежные и предсказуемые модели, сохраняя высокую точность вознаграждения Reward Accuracy даже при увеличении уровня шума. В частности, GAPO показал свою эффективность в различных сценариях, характеризующихся разнообразными типами и степенями зашумленности данных, что подтверждает его способность к адаптации и стабильной работе в сложных условиях. Полученные результаты свидетельствуют о значительном улучшении показателей обобщения, позволяя моделям, использующим GAPO, демонстрировать высокую производительность на ранее не встречавшихся данных и обеспечивая более уверенное поведение в реальных приложениях.
Исследование демонстрирует, что стабильность и надежность в обучении больших языковых моделей напрямую зависят от структуры процесса оптимизации. Как отмечает Тим Бернерс-Ли: «Все начинается с данных». Данная работа, предлагая метод Geometric Anchor Preference Optimization (GAPO), подчеркивает важность сравнения текущей политики с пессимистичным локальным суррогатом. Это позволяет не просто оптимизировать модель, но и обеспечить её устойчивость к изменениям и непредсказуемым данным. Подобный подход, акцентирующий внимание на локальной структуре и кривизне, соответствует принципу эволюции системы без необходимости перестройки всего квартала, что обеспечивает плавное и надежное развитие.
Куда Ведет Дорога?
Предложенный подход, фокусируясь на геометрическом привязке и пессимистичной локальной аппроксимации, безусловно, представляет собой шаг к более надежному выравниванию языковых моделей с предпочтениями человека. Однако, кажущаяся элегантность решения лишь подчеркивает фундаментальную сложность задачи. Каждая новая зависимость от локальной кривизны — это скрытая цена свободы от непредсказуемых отклонений. Вопрос в том, насколько адекватно выбранный суррогат отражает истинный ландшафт предпочтений, и не упустит ли система возможности для более глубокого и полезного взаимодействия.
Очевидным направлением для дальнейших исследований представляется изучение влияния различных метрик геометрического расстояния и стратегий выбора пессимистичной аппроксимации. Необходимо также исследовать, как предложенный метод масштабируется на более сложные задачи и большие модели, и не приведет ли к возникновению нежелательных побочных эффектов. Крайне важно понимать, что стабильность — это лишь один из аспектов, и истинная ценность заключается в способности системы к адаптации и обучению.
В конечном счете, предложенный метод — это лишь инструмент, и его эффективность будет определяться не только техническими деталями, но и пониманием более широкого контекста. Необходимо помнить, что структура определяет поведение, и что любое решение, принятое на одном уровне, неминуемо повлияет на всю систему. Поиск оптимального баланса между стабильностью, адаптивностью и выразительностью остается центральной задачей для исследователей в области обучения с подкреплением на основе обратной связи от человека.
Оригинал статьи: https://arxiv.org/pdf/2602.04909.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Эффективный поиск максимума субмодулярных функций с ограничениями
- Российский рынок: Рубль растет, облигации ждут взлета, а сектор сырья под давлением (27.03.2026 12:32)
- Netflix: Рост Подписчиков и Нарастающие Риски
- Европейский путь Форда: надежда в китайском партнерстве
- Сегежа акции прогноз. Цена SGZH
- РУСАЛ акции прогноз. Цена RUAL
- Прогноз нефти
- Российский рынок акций: позитив под вопросом. Чего ждать инвесторам? (14.05.2026 04:32)
- Золотые Копатели: Взгляд Скептика
2026-02-08 20:08