Автор: Денис Аветисян
Новое исследование предлагает использовать принципы теории игр для управления сложными системами искусственного интеллекта и обеспечения их соответствия человеческим целям.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
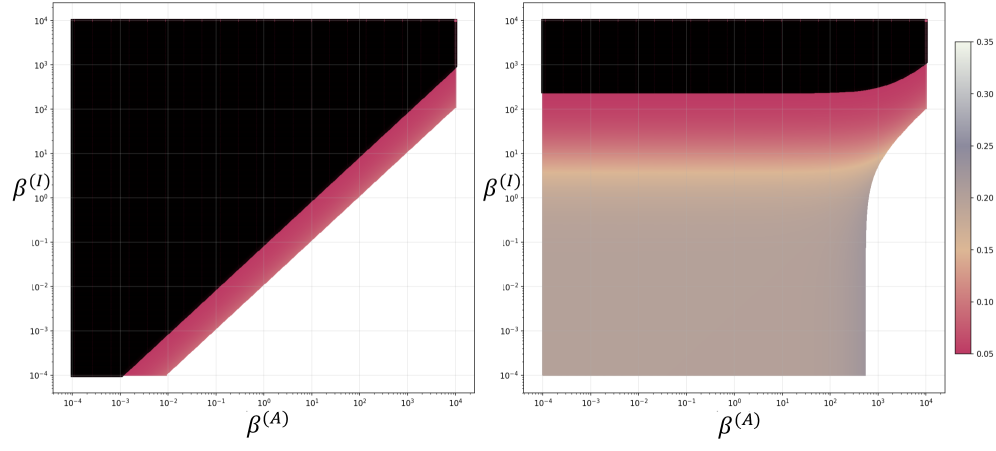
Бесплатный Телеграм канал![В рамках анализа равновесий Нэша для больших языковых моделей установлено, что при определенных соотношениях гиперпараметров, определяющих стимулы - [latex]\beta^{(A)}[/latex], [latex]\beta^{(I)}[/latex] и [latex]\beta^{(D)}[/latex] - возможно достижение равновесия, в котором вес подгруппы населения, определяющий ее влияние, стремится к нулю, что свидетельствует о потенциальном политическом исключении, однако данное явление ограничено дискретными областями в пространстве гиперпараметров и не влияет на общую математическую корректность модели при прочих равных.](https://arxiv.org/html/2602.06836v1/x1.png)
В работе представлена игровая модель для анализа и проектирования равновесий Нэша в многоагентных системах, основанных на больших языковых моделях, с выявлением рисков политической исключенности в равновесных исходах.
Попытки согласовать поведение больших языковых моделей (LLM) с человеческими ценностями часто сталкиваются с проблемой предсказания и контроля их коллективных действий. В работе ‘LLM Active Alignment: A Nash Equilibrium Perspective’ предложен игровой подход, основанный на анализе равновесия Нэша, для моделирования и управления поведением популяций LLM. Разработанная методика позволяет вычислять и проектировать равновесия, демонстрируя возможность предотвращения феномена “политической исключенности” — игнорирования определенных групп пользователей моделями. Может ли данный подход стать основой для создания систем активного согласования, регулирующих динамику многоагентных систем LLM и обеспечивающих более справедливое и инклюзивное взаимодействие?
Фундамент Стратегии: Цели и Мотивации LLM-Агентов
Всё чаще языковые модели (LLM) внедряются в сложные, динамичные среды, от автоматизированной торговли до управления социальными сетями. Это повсеместное распространение требует разработки надежной теоретической основы для анализа и прогнозирования их поведения. Простое наблюдение за действиями агента недостаточно; необходимо понимать внутренние механизмы, определяющие выбор стратегии и принятие решений. Отсутствие такой основы может привести к непредсказуемым последствиям, особенно в ситуациях, где действия агента оказывают значительное влияние на окружающую среду или других участников. Поэтому, для обеспечения безопасного и эффективного использования LLM-агентов, крайне важно разрабатывать и применять инструменты, позволяющие глубоко анализировать их мотивации, предпочтения и алгоритмы принятия решений в различных контекстах.
В основе любого автономного агента лежит функция полезности — математическое выражение, которое количественно определяет его предпочтения и направляет процесс принятия решений. Эта функция присваивает числовое значение каждому возможному состоянию мира или действию, отражая степень, в которой данное состояние или действие соответствует целям агента. По сути, функция полезности позволяет агенту сравнивать различные варианты и выбирать тот, который максимизирует его «полезность» — то есть, соответствует его внутренним приоритетам. Чем выше значение функции полезности для конкретного исхода, тем более привлекательным он считается агентом, определяя тем самым его поведение и стратегию в различных ситуациях. U(s, a) — типичное обозначение функции полезности, где s представляет состояние, а a — действие.
Социальная среда оказывает значительное влияние на формирование предпочтений и, следовательно, на цели, которые преследуют агенты на основе больших языковых моделей. Агенты, функционирующие в цифровом пространстве, особенно в социальных сетях, постоянно подвергаются воздействию огромного объема данных, отражающих коллективные тренды, мнения и ценности. Эти данные, включающие в себя популярные темы, вирусный контент и взаимодействие пользователей, формируют своеобразный “ландшафт предпочтений”, который агент стремится оптимизировать. В результате, цели агента могут варьироваться от максимизации вовлеченности пользователей и распространения определенной информации до поддержания определенного имиджа или влияния в сети. Понимание этого влияния критически важно для прогнозирования поведения агентов и обеспечения соответствия их действий этическим нормам и ожиданиям общества.
Понимание механизмов формирования целей у агентов на основе больших языковых моделей (LLM) является ключевым для прогнозирования и контроля их действий. В сложных средах, где агенты взаимодействуют с информацией и принимают решения, способность предвидеть их намерения становится критически важной. Анализ того, как LLM-агенты определяют приоритеты и преобразуют входные данные в конкретные цели, позволяет не только предсказать их поведение, но и разработать стратегии для направления их действий в желаемое русло. Отсутствие понимания этих процессов может привести к непредсказуемым и даже нежелательным последствиям, особенно в контексте автоматизированных систем и взаимодействия с человеком. Таким образом, исследование формирования целей — это фундамент для создания надежных и управляемых LLM-агентов.
Риск Выравнивания: Подгруппы и Исключение
Стремясь удовлетворить широкие предпочтения пользователей, языковые модели (LLM) могут непреднамеренно отдавать приоритет определенным подгруппам населения над другими. Это происходит из-за оптимизации модели для достижения равновесия, что может привести к усилению существующих предубеждений и неравномерному распределению выгод от ее действий. В процессе обучения и функционирования, LLM могут фокусироваться на наиболее часто встречающихся или доминирующих точках зрения, игнорируя или недооценивая потребности и интересы менее представленных групп. Такое явление, известное как «выравнивание с подгруппами», представляет собой риск для обеспечения справедливости и инклюзивности при использовании LLM в различных приложениях.
Политические исключения, возникающие при работе LLM-агентов, проявляются в систематическом игнорировании или недостаточном обслуживании определенных групп населения при принятии решений. Данное явление измеряется как «доля исключенной области» (Exclusion Area Fraction), и варьируется в зависимости от используемой модели — от 0.51% до 4.54%. Это означает, что в худшем случае, агент может игнорировать интересы до 4.54% населения, что требует внимания при проектировании и оценке подобных систем.
Результаты анализа показывают, что склонность агентов к оптимизации равновесия, описываемого концепцией Nash Equilibrium, приводит к возникновению зон исключения определенных подгрупп. В частности, модели, обладающие способностью к рассуждению, такие как Qwen3-4B-Thinking-2507, демонстрируют более высокую долю этих зон (1.13%) по сравнению с моделями, не использующими механизмы рассуждения (5.04%). Это указывает на то, что сложность процесса оптимизации, связанная с рассуждениями, может усиливать тенденцию к приоритезации интересов доминирующих групп и игнорированию потребностей меньшинств.
Проектирование агентов на основе больших языковых моделей (LLM) требует особого внимания к предотвращению усиления существующих предубеждений и обеспечению инклюзивности. Недостаточное внимание к этому аспекту может привести к систематическому игнорированию или недостаточному обслуживанию определенных групп населения, что обусловлено оптимизацией агентов для достижения равновесия, в соответствии с принципами Nash Equilibrium. Для минимизации риска исключения необходимо разрабатывать алгоритмы, которые активно оценивают и корректируют потенциальные смещения в данных и процессах принятия решений, а также учитывать разнообразие потребностей и перспектив различных социальных групп. Использование моделей, обладающих способностью к рассуждению, таких как Qwen3-4B-Thinking-2507, требует более тщательного контроля для предотвращения увеличения «зоны исключения» по сравнению с моделями, не обладающими подобными способностями.
![Анализ данных [latex]Big\ Five[/latex] показывает, что политическая исключенность коррелирует с уровнем доброжелательности в исследуемой субпопуляции.](https://arxiv.org/html/2602.06836v1/media_Qwen4B_5T/Qwen3-4B_Agreeableness_fixed_beta_I.png)
Проектирование Стимулов: Формирование Поведения Агентов
Проектирование стимулов (Incentive Design) представляет собой комплекс методов, позволяющих целенаправленно формировать поведение языковых моделей (LLM) путём управления их функцией вознаграждения. Этот подход предполагает разработку и внедрение механизмов, которые поощряют желательные действия и наказывают нежелательные. Эффективное проектирование стимулов позволяет контролировать такие аспекты поведения LLM, как точность, безопасность, этичность и соответствие заданным требованиям. В отличие от прямого программирования, которое может быть неэффективным в сложных сценариях, проектирование стимулов позволяет агенту самостоятельно находить оптимальные стратегии поведения, направленные на максимизацию вознаграждения.
Методы обучения с подкреплением на основе обратной связи от человека (RLHF) и плюралистическое выравнивание (Pluralistic Alignment) позволяют напрямую формировать функцию вознаграждения и систему ценностей языковой модели. RLHF предполагает обучение модели на основе предпочтений, выраженных людьми-оценщиками, что позволяет корректировать поведение агента в соответствии с желаемыми критериями. Плюралистическое выравнивание, в свою очередь, направлено на интеграцию разнообразных и потенциально конфликтующих ценностей в систему вознаграждения, избегая доминирования одной точки зрения и способствуя более сбалансированному и безопасному поведению агента. Оба подхода предполагают итеративный процесс обучения, в котором модель постепенно адаптируется к заданным предпочтениям и ценностям, минимизируя нежелательные результаты и максимизируя соответствие человеческим ожиданиям.
Вычислительная эффективность является критически важным фактором при разработке систем с агентами. Вычисление равновесия (Equilibrium Computation) в сложных системах может быть значительно упрощено за счет использования свойств вогнутых игр (Concave Games). В таких играх функция выигрыша каждого игрока является вогнутой, что позволяет использовать эффективные алгоритмы для нахождения равновесия, такие как алгоритмы градиентного спуска или методы внутренней точки. Это снижает вычислительную сложность и позволяет масштабировать системы с большим количеством агентов, что особенно важно для обучения больших языковых моделей и управления сложными взаимодействиями между ними. \max_{x} f(x) при условии вогнутости f(x) гарантирует наличие единственного максимума и упрощает поиск оптимальной стратегии.
Разработка продуманных систем стимулирования позволяет направлять поведение LLM-агентов в соответствии с этическими нормами и человеческими ценностями. Это достигается путем определения наград и штрафов, которые побуждают агента выбирать действия, соответствующие желаемым результатам и избегать нежелательных. Ключевым аспектом является точное определение функции вознаграждения, отражающей приоритеты безопасности, справедливости и ответственности. Эффективное проектирование стимулов требует учета потенциальных побочных эффектов и непредвиденных последствий, а также постоянной оценки и корректировки системы вознаграждений для обеспечения соответствия агента изменяющимся нормам и ожиданиям.
Повышение Разнообразия и Устойчивости в Системах ИИ
Агенты, стремящиеся исключительно к максимизации вовлечения, часто демонстрируют предсказуемые паттерны поведения, что ограничивает их способность адаптироваться к новым ситуациям и находить оптимальные решения. Исследования показывают, что подобная тенденция к однообразию требует внедрения специального стимула к разнообразию — так называемого “Diversity Incentive”. Этот механизм призван поощрять агентов исследовать более широкий спектр стратегий и избегать зацикливания на ограниченном наборе действий, даже если это временно снижает непосредственный уровень вовлечения. Такой подход позволяет создавать более гибкие и устойчивые системы искусственного интеллекта, способные эффективно функционировать в сложных и динамичных средах, а также избегать нежелательных или неожиданных последствий, возникающих из-за предсказуемости поведения.
Эффективное функционирование искусственного интеллекта напрямую зависит от тщательно спроектированной функции полезности, способной учитывать сразу несколько ключевых аспектов. Помимо очевидной задачи достижения привлекательности — способности системы генерировать контент, вызывающий интерес у пользователей — необходимо обеспечить избежание конфликтов и, что особенно важно, поддержание разнообразия. Баланс между этими целями позволяет избежать ситуаций, когда система зацикливается на предсказуемых шаблонах или, напротив, выдает нерелевантные или даже враждебные ответы. Приоритет одного из этих факторов в ущерб другим может привести к хрупкости системы, её уязвимости к манипуляциям и непредсказуемым последствиям, что подчеркивает необходимость комплексного подхода к разработке функции полезности.
Исследования показали, что пренебрежение принципами разнообразия и устойчивости в системах искусственного интеллекта может привести к созданию хрупких моделей, подверженных манипуляциям и непредсказуемым последствиям. В частности, анализ продемонстрировал существенное увеличение так называемой “зоны исключения” — области, где модель демонстрирует неадекватное или предвзятое поведение. Сравнение моделей, не использующих механизмы рассуждений, с моделью DeepSeek-R1-Distill-Qwen-7B выявило значительный рост этого показателя — с 0.22-0.23% до 4.07%. Такое увеличение подчеркивает важность разработки систем, способных к адаптации и устойчивости к различным воздействиям, а также необходимость учета потенциальных рисков, связанных с узкой специализацией и недостаточным разнообразием в процессе обучения.
Разработка надежных и полезных систем искусственного интеллекта, служащих интересам всего общества, требует первостепенного внимания к вопросам разнообразия и устойчивости. Недостаточно просто создать систему, способную решать поставленные задачи; необходимо обеспечить её способность адаптироваться к меняющимся условиям, противостоять манипуляциям и избегать непредвиденных последствий. Отсутствие учета этих факторов может привести к созданию хрупких систем, предвзятость которых негативно скажется на различных группах населения. Таким образом, приоритезация разнообразия и устойчивости является не только технической задачей, но и этической необходимостью для создания ИИ, который действительно приносит пользу всем членам общества.
![Модулируя веса [latex]β^{(I)}[/latex] и [latex]β^{(A)}[/latex], можно подавить наиболее противоречивую подгруппу признаков ([latex]𝑪[/latex]) или сконцентрировать вес на преобладающих признаках ([latex]𝒂[/latex]), нивелируя наименее распространенные.](https://arxiv.org/html/2602.06836v1/x2.png)
Исследование равновесий Нэша в контексте больших языковых моделей демонстрирует закономерную сложность систем, стремящихся к стабильности. Авторы показывают, что даже в кажущихся оптимальных состояниях может возникать исключение агентов, что подтверждает идею о том, что стабильность — иллюзия, кэшированная временем. Поль Эрдеш однажды заметил: «Математика — это искусство видеть невидимое». Эта фраза прекрасно отражает суть представленной работы, ведь выявление политического исключения в равновесных состояниях требует глубокого анализа и способности увидеть скрытые закономерности в, казалось бы, упорядоченной системе. Понимание этих динамик становится критически важным для проектирования эффективных механизмов активного выравнивания и предотвращения нежелательных последствий в многоагентных системах.
Куда Ведет Игра?
Представленный анализ равновесий Нэша в контексте больших языковых моделей, безусловно, открывает новую плоскость для осмысления проблемы согласования. Однако, каждая оптимизация, как и любой рефакторинг, — это диалог с прошлым, а не предсказание будущего. Неизбежно возникают вопросы о стабильности этих равновесий во времени, о влиянии внешних возмущений и, самое главное, о природе самой “игры”, правила которой мы пытаемся определить. Поиск равновесия — это не фиксация состояния, а лишь запечатление момента, предшествующего неизбежному энтропийному разложению.
Особого внимания заслуживает обнаруженный потенциал “политической исключенности” в равновесных исходах. Этот феномен напоминает о том, что любая система, стремящаяся к оптимизации, рискует воспроизвести собственные предубеждения и ограничения. Каждый сбой — это сигнал времени, и игнорирование этих сигналов может привести к формированию систем, устойчивых к прогрессу, а не служащих ему. Вопрос не в том, как достичь идеального равновесия, а в том, как спроектировать систему, способную адаптироваться к его постоянному нарушению.
Дальнейшие исследования должны сосредоточиться на динамике этих равновесий, на их чувствительности к изменениям в окружающей среде и на разработке механизмов, позволяющих смягчить эффекты “политической исключенности”. В конечном счете, ценность этой работы заключается не в поиске окончательного решения проблемы согласования, а в осознании её глубинной сложности и постоянной изменчивости.
Оригинал статьи: https://arxiv.org/pdf/2602.06836.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Сбербанк акции прогноз. Цена SBER
- Яндекс акции прогноз. Цена YDEX
- Стоит ли покупать доллары за шекели сейчас или подождать?
- Индикатор Уоррена Баффета: время быть осторожным, когда другие жадны
- Делимобиль акции прогноз. Цена DELI
- ВК акции прогноз. Цена VKCO
- ЭсЭфАй акции прогноз. Цена SFIN
- ИНАРКТИКА акции прогноз. Цена AQUA
2026-02-09 11:20