Автор: Денис Аветисян
Новая система RuleSmith использует возможности больших языковых моделей для автоматической балансировки асимметричных стратегий, открывая новые горизонты в дизайне игровых правил.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал
Исследователи представили RuleSmith — фреймворк, сочетающий самообучение языковых моделей и байесовскую оптимизацию для автоматической балансировки асимметричных игр.
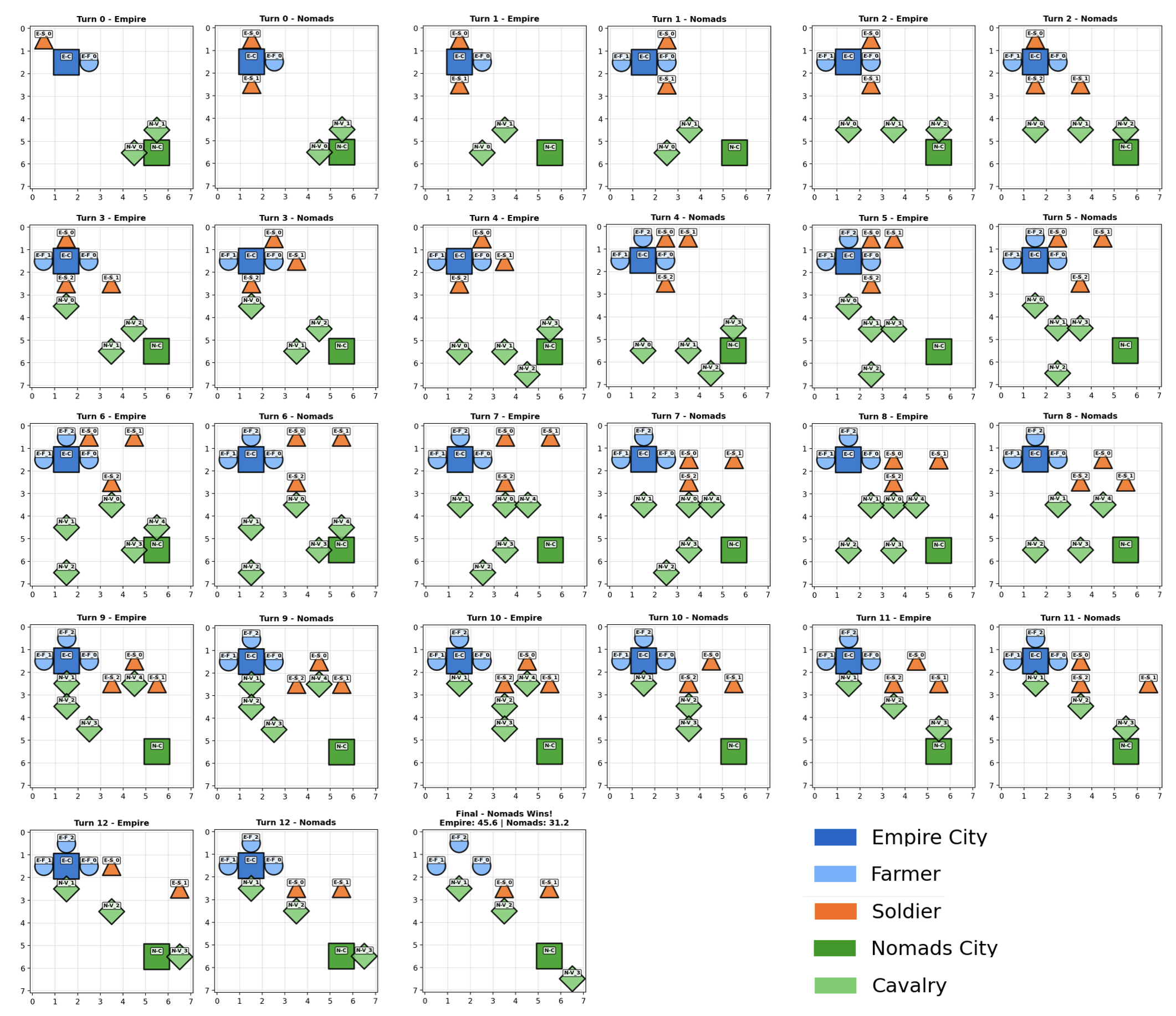
Балансировка игровых механик традиционно требует трудоемких итераций тестирования и экспертных оценок. В статье ‘RuleSmith: Multi-Agent LLMs for Automated Game Balancing’ представлена инновационная система, использующая многоагентное взаимодействие больших языковых моделей (LLM) и байесовскую оптимизацию для автоматической настройки параметров асимметричных стратегий. Предложенный фреймворк, протестированный на упрощенной цивилизационной игре, демонстрирует возможность достижения сбалансированных конфигураций и выявления интерпретируемых изменений в правилах. Может ли подобный подход LLM-симуляции стать эффективным инструментом для автоматизации проектирования и балансировки сложных многоагентных систем в различных областях?
Сложность Асимметричного Баланса в Играх
Разработка сбалансированной игры, особенно когда фракции обладают асимметричными возможностями, представляет собой сложную задачу, требующую постоянной итеративной настройки игровых параметров. Неравенство в силах и уникальные способности каждой фракции создают каскад взаимосвязей, которые трудно предсказать и учесть при ручной балансировке. Каждый параметр — от скорости передвижения юнитов до стоимости апгрейдов — оказывает влияние на общую стратегическую картину, и даже незначительные изменения могут привести к непредсказуемым последствиям. Процесс требует тщательного анализа результатов тестирования, выявления дисбаланса и внесения корректировок, что часто превращается в долгий и трудоемкий цикл. Именно поэтому автоматизированные методы балансировки, способные эффективно адаптировать параметры игры, становятся все более востребованными в индустрии.
Традиционные методы балансировки игровых проектов, основанные на опыте и интуиции разработчиков, зачастую оказываются трудоемкими и не всегда эффективными. Ручная настройка параметров игры, требующая многочисленных итераций тестирования, не способна в полной мере учесть сложность взаимодействий между различными элементами игрового процесса. Особенно остро эта проблема проявляется в асимметричных играх, где фракции обладают уникальными способностями и стратегиями. В результате, достижение оптимального баланса, обеспечивающего справедливую и увлекательную игру для всех участников, может занять значительное время и потребовать больших ресурсов, а итоговый результат может оставаться далёким от идеала, из-за неспособности учесть все возможные комбинации и сценарии развития событий.
Оценка дисбаланса является ключевым аспектом при создании сбалансированных игр, особенно когда речь идет о фракциях с неравными возможностями. Простого анализа показателя побед недостаточно, поскольку он не учитывает сложность взаимодействия между игроками и фракциями. Предложенная разработка использует усовершенствованную функцию оценки потерь баланса, позволяющую точно измерять степень дисбаланса и направлять процесс оптимизации. Данный подход демонстрирует высокую эффективность: даже при намеренно несбалансированных исходных настройках, система способна достигать близких к идеальным результатам, обеспечивая показатели побед в диапазоне 50% ± 5%, что свидетельствует о значительном улучшении в области автоматической балансировки игровых систем.
![Метод RuleSmith использует байесовскую оптимизацию для поиска оптимальной конфигурации правил θ в асимметричной пошаговой стратегии (CivMini), оценивая баланс сил между игроками (Empire и Nomads) через функцию потерь [latex] \mathcal{L}(\theta) [/latex] и адаптируя количество игр [latex] N_t [/latex] для точной оценки перспективных кандидатов с помощью функции ожидаемого улучшения, а дискретизация непрерывных предложений осуществляется оператором [latex] D(\cdot) [/latex].](https://arxiv.org/html/2602.06232v1/figures/method.png)
RuleSmith: Автоматизированная Система Балансировки
В основе RuleSmith лежит метод байесовской оптимизации, позволяющий эффективно исследовать пространство параметров игры для достижения оптимального баланса. В отличие от методов полного перебора или случайного поиска, байесовская оптимизация использует вероятностную модель для прогнозирования производительности различных конфигураций параметров. Эта модель обновляется после каждой итерации, направляя поиск к наиболее перспективным областям пространства параметров. В результате, RuleSmith способен находить близкие к оптимальным значения параметров, значительно сокращая количество необходимых итераций по сравнению с традиционными подходами к балансировке игр.
В основе RuleSmith лежит методология LLM самообучения (LLM Self-Play), где два агента, управляемых большими языковыми моделями, соревнуются друг с другом в игровой среде CivMini. В процессе игры агенты генерируют стратегии и действия, а результаты этих взаимодействий используются для оценки и улучшения их производительности. Итеративный характер самообучения позволяет RuleSmith автоматически исследовать различные варианты игровых параметров и находить оптимальные балансировочные настройки, основываясь на результатах соревнований между агентами.
Для обеспечения обоснованного принятия решений в процессе игры, фреймворк RuleSmith использует систему извлечения и генерации (RAG). Эта система предоставляет LLM-агентам актуальные правила игры CivMini, позволяя им учитывать эти правила при формировании стратегий. Важно отметить, что для достижения близких к сбалансированным результатам, фреймворку требуется всего 100 итераций оптимизации, что свидетельствует о высокой эффективности подхода и скорости сходимости к оптимальным параметрам баланса игры.
Оптимизация Исследования и Эксплуатации с Помощью Байесовских Методов
В RuleSmith для определения следующей точки для оценки используется функция приобретения Expected Improvement (Ожидаемое Улучшение). Эта функция количественно оценивает потенциал улучшения текущего лучшего результата при исследовании новых параметров. Она сочетает в себе два ключевых аспекта: исследование (exploration) — поиск областей пространства параметров, где ожидается значительное улучшение, и эксплуатацию (exploitation) — фокусировку на параметрах, которые уже показали многообещающие результаты. Expected Improvement учитывает как величину потенциального улучшения, так и вероятность его достижения, что позволяет динамически балансировать между поиском новых, перспективных конфигураций и оптимизацией существующих.
Для повышения эффективности поиска оптимальных параметров в RuleSmith используется метод адаптивной выборки (Adaptive Sampling). Этот метод динамически распределяет вычислительные ресурсы, выделяя больше оценочных игр (от 16 до 64 за итерацию) для областей параметрического пространства, демонстрирующих высокий потенциал. Данная стратегия позволяет RuleSmith сосредоточиться на наиболее перспективных участках, сокращая время, необходимое для достижения оптимальной конфигурации и повышая общую эффективность исследования.
Агенты, управляющие игровым процессом в RuleSmith, базируются на модели InternVL3.5, что обеспечивает надежное принятие решений в условиях сложной игровой среды. InternVL3.5 представляет собой многомодальную языковую модель, способную эффективно обрабатывать визуальную и текстовую информацию, необходимую для оценки игровых ситуаций и выбора оптимальных стратегий. Использование данной модели позволяет агентам адаптироваться к различным игровым сценариям и демонстрировать стабильно высокие результаты, что критически важно для эффективного исследования и эксплуатации игрового пространства.
Значение и Перспективы Развития
Разработка RuleSmith знаменует собой существенный прорыв в области асимметричного баланса в играх, предлагая масштабируемое и автоматизированное решение для задачи, которая традиционно требовала значительных усилий и экспертной оценки. В отличие от ручных методов или алгоритмов, ограниченных конкретными игровыми механиками, RuleSmith использует самообучение больших языковых моделей и байесовскую оптимизацию, что позволяет ему адаптироваться к различным игровым условиям и находить оптимальные параметры для достижения сбалансированного игрового процесса. Такой подход не только снижает затраты времени и ресурсов, необходимые для балансировки, но и открывает возможности для создания более сложных и динамичных игровых систем, где баланс постоянно корректируется в ответ на действия игроков и изменения в игровой среде. В перспективе, эта технология способна трансформировать процесс разработки игр, позволяя сосредоточиться на творческих аспектах, а рутинные задачи по балансировке доверить автоматизированным системам.
Принципы, лежащие в основе RuleSmith, а именно использование самообучения больших языковых моделей (LLM) в сочетании с байесовской оптимизацией, демонстрируют значительный потенциал за пределами задач балансировки игровых стратегий. Данный подход позволяет эффективно исследовать и оптимизировать сложные пространства параметров, возникающие в различных областях, таких как проектирование инженерных систем, разработка финансовых моделей или даже оптимизация логистических цепочек. Способность системы автоматически находить оптимальные решения, используя лишь заданные критерии и процесс самообучения, делает её универсальным инструментом для решения широкого спектра задач, где традиционные методы оптимизации оказываются неэффективными или трудоемкими. Таким образом, RuleSmith представляет собой не просто фреймворк для игрового дизайна, но и перспективную платформу для автоматизированного решения сложных оптимизационных проблем в различных областях науки и техники.
Дальнейшие исследования в рамках RuleSmith направлены на усовершенствование архитектур игровых агентов, с целью повышения их адаптивности и стратегической глубины. Особое внимание уделяется разработке методов, позволяющих системе эффективно функционировать в динамически меняющихся игровых средах, где баланс сил может смещаться со временем. Важно отметить, что достигнутая стабильность баланса — около 50% выигрышей с погрешностью в 5% — демонстрируется независимо от размера используемых языковых моделей (2B, 8B) и конфигурации игровых фракций, что подтверждает масштабируемость и надежность предложенного подхода к автоматической балансировке игр.
Исследование представляет собой элегантный пример того, как масштабируемость достигается не за счет увеличения вычислительных мощностей, а благодаря ясности идей. RuleSmith, как система, демонстрирует, что структура действительно определяет поведение. Автоматический баланс асимметричных игр, достигнутый благодаря взаимодействию LLM и байесовской оптимизации, подчеркивает важность целостного подхода к разработке. Как отмечал Г.Х. Харди: «Математика — это не просто решение задач, а поиск истины». Подобно этому, RuleSmith не просто решает задачу балансировки игр, но и открывает новые горизонты в области проектирования гибких и адаптивных систем.
Что дальше?
Представленная работа, безусловно, демонстрирует потенциал многоагентных систем, управляемых большими языковыми моделями, для автоматической балансировки игровых правил. Однако, не стоит обманываться кажущейся простотой решения. Если система держится на костылях байесовской оптимизации, значит, мы переусложнили задачу, не до конца поняв внутреннюю логику самой игры. Модульность, как иллюзия контроля, может привести к тому, что балансировка будет локальной, а глобальная целостность игровой экосистемы — нарушена.
В будущем необходимо сосредоточиться не только на улучшении алгоритмов оптимизации, но и на разработке более глубокого понимания принципов, определяющих игровой баланс. Искусственный интеллект должен не просто подбирать параметры, а понимать, почему определенные правила работают лучше других. Иначе мы рискуем создать системы, способные лишь имитировать баланс, но не способные к истинному пониманию.
Ключевым направлением представляется исследование возможности интеграции формальных методов верификации с самоигрой. Ведь, если система сложна, а ее поведение непредсказуемо, никакие алгоритмы оптимизации не смогут гарантировать ее устойчивость. Истинная элегантность рождается из простоты и ясности, а не из бесконечного нагромождения правил.
Оригинал статьи: https://arxiv.org/pdf/2602.06232.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Прогноз нефти
- Сегежа акции прогноз. Цена SGZH
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- МФК Займер акции прогноз. Цена ZAYM
- 🤯 Как ход Визы со стейблкоинами заставляет Уолл-стрит нервничать: BitPay раскрывает всё! 🤯
- Стоит ли покупать доллары за гонконгские доллары сейчас или подождать?
- Мосбиржа акции прогноз. Цена MOEX
2026-02-09 16:24