Автор: Денис Аветисян
Исследователи предлагают инновационную методику, позволяющую стабилизировать и ускорить процесс обучения больших языковых моделей, несмотря на значительные различия между политиками, используемыми для сбора данных и обучения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал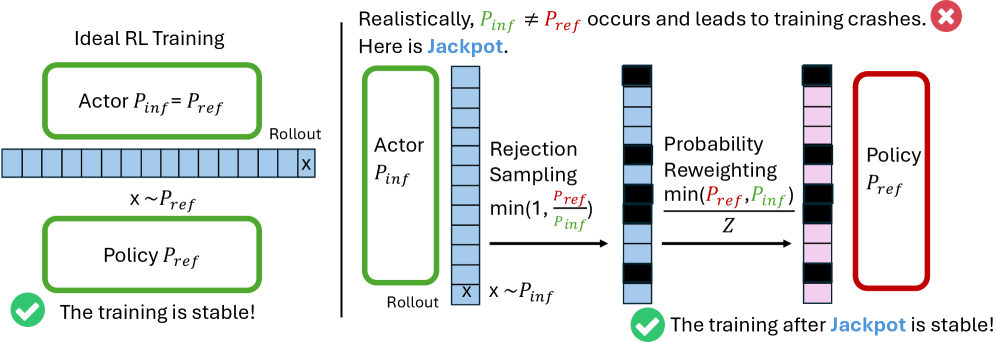
Представлен алгоритм Jackpot, использующий оптимальную выборку с отклонением по бюджету для эффективной подгонки распределений политик в задачах обучения с подкреплением.
Обучение с подкреплением для больших языковых моделей (LLM) сталкивается с ограничениями, обусловленными высокой стоимостью этапа генерации траекторий. В работе ‘Jackpot: Optimal Budgeted Rejection Sampling for Extreme Actor-Policy Mismatch Reinforcement Learning’ предложен новый фреймворк, использующий оптимальную выборочную приемку с фиксированным бюджетом (OBRS) для снижения расхождения между политикой генерации траекторий и обучаемой политикой. Это позволяет добиться стабильного обучения и эффективности, сопоставимой с on-policy методами, даже при значительном расхождении между политиками. Может ли предложенный подход стать ключевым шагом к практическому разделению этапов генерации траекторий и оптимизации политики в обучении LLM с подкреплением?
Ограничения Больших Языковых Моделей: Теория и Реальность
Несмотря на впечатляющие достижения в различных областях, современные большие языковые модели (БЯМ) демонстрируют существенные ограничения в способности к сложному рассуждению и обобщению знаний. Хотя БЯМ способны генерировать связные и грамматически правильные тексты, их понимание контекста и логических связей зачастую поверхностно. Модели могут успешно решать задачи, аналогичные тем, что встречались в обучающей выборке, но испытывают трудности при столкновении с новыми, нетипичными ситуациями или при необходимости применения знаний в нестандартных комбинациях. Это связано с тем, что БЯМ, по сути, оперируют статистическими закономерностями в данных, а не глубоким пониманием смысла, что препятствует их способности к настоящему интеллектуальному анализу и адаптации к меняющимся условиям. Таким образом, несмотря на кажущийся интеллект, БЯМ нуждаются в дальнейшем совершенствовании для преодоления этих фундаментальных ограничений.
Непосредственное увеличение масштаба языковых моделей, хотя и привело к впечатляющим результатам, сталкивается с растущими вычислительными издержками и неэффективностью. Обучение и развертывание моделей с миллиардами параметров требует огромных ресурсов, что делает этот подход unsustainable в долгосрочной перспективе. В связи с этим, активно разрабатываются новые подходы, направленные на повышение эффективности использования данных — так называемая «sample efficiency». Эти методы включают в себя, например, обучение с подкреплением, мета-обучение и использование синтетических данных, позволяя моделям достигать сравнимых или даже превосходящих результатов, используя значительно меньшие объемы обучающих данных и требуя меньше вычислительных ресурсов. Повышение «sample efficiency» является ключевым шагом на пути к созданию более доступных и устойчивых языковых моделей.
Существенное расхождение между распределением данных, используемых при обучении языковых моделей, и реальной средой, в которой они применяются, представляет собой серьезную проблему для обеспечения надежной работы. В процессе обучения модели усваивают закономерности, характерные для определенного набора данных, который может не отражать всего разнообразия ситуаций, с которыми она столкнется в будущем. Это несоответствие, известное как смещение распределений, приводит к снижению точности и предсказуемости модели в новых, незнакомых условиях. Например, модель, обученная на формальном письменном языке, может испытывать трудности с пониманием разговорной речи или сленга. Поэтому, для повышения надежности языковых моделей необходимо разрабатывать методы адаптации к изменяющимся условиям и уменьшения влияния смещения распределений, что является ключевой задачей в области искусственного интеллекта.
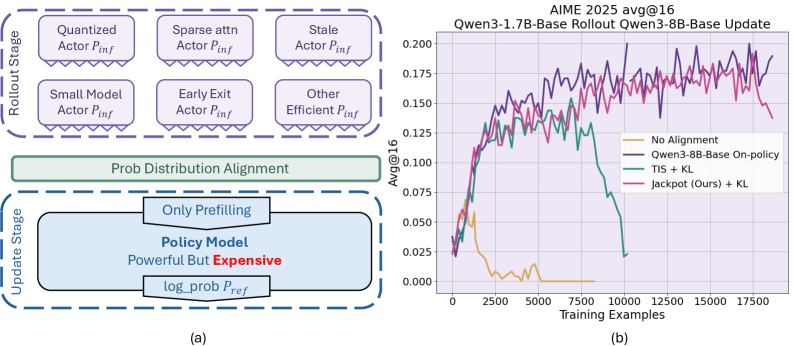
![Численное моделирование показало, что предложенный метод Jackpot ([latex] ext{Jackpot} [/latex]) эффективно снижает расхождение Кульбака-Лейблера ([latex] KL [/latex]) между распределениями вероятностей актора и политики, поддерживая его на низком уровне в процессе обучения, в отличие от методов без выравнивания и TIS, при этом обеспечивая высокую скорость принятия (>90%) даже при значительном различии между распределениями.](https://arxiv.org/html/2602.06107v1/x2.png)
Обучение с Подкреплением: Настройка Поведения Языковых Моделей
Обучение с подкреплением (RL) представляет собой перспективный подход к согласованию больших языковых моделей (LLM) с желаемым поведением и улучшению их способности принимать решения. В отличие от традиционных методов обучения с учителем, RL позволяет модели обучаться посредством взаимодействия со средой и получения обратной связи в виде наград или штрафов. Это позволяет LLM оптимизировать стратегии генерации текста, направленные на достижение конкретных целей, таких как максимизация полезности ответа, минимизация вредных или предвзятых высказываний, или повышение согласованности с инструкциями пользователя. Применение RL позволяет преодолеть ограничения, присущие обучению на статичных наборах данных, и адаптировать LLM к динамическим требованиям и сложным задачам.
Метод PPO (Proximal Policy Optimization) является широко используемым алгоритмом обучения с подкреплением для тонкой настройки больших языковых моделей (LLM) благодаря своей стабильности и эффективности. Однако, методы обучения вне политики (off-policy methods), такие как Q-learning и его варианты, предлагают потенциальные преимущества, включая более эффективное использование данных и возможность обучения на данных, собранных из предыдущих версий модели или других источников. В отличие от PPO, который требует сбора данных непосредственно из текущей политики, off-policy методы позволяют использовать данные, полученные из любой политики, что может ускорить процесс обучения и повысить общую производительность модели. При этом, реализация off-policy методов для LLM требует тщательного контроля для предотвращения проблем, связанных с оценкой ценности и смещением распределений.
Основная сложность применения обучения с подкреплением (RL) к большим языковым моделям (LLM) заключается в эффективном отборе выборок (sampling) из модели и минимизации расхождения распределений между данными, используемыми в процессе обучения, и данными, с которыми модель сталкивается при реальном использовании. Неадекватный отбор выборок может привести к предвзятости и снижению обобщающей способности модели. Расхождение распределений, возникающее из-за различий в данных обучения и развертывания, может значительно ухудшить производительность LLM в новых, ранее не встречавшихся ситуациях. Для смягчения этих проблем используются такие методы, как важность отбора проб (importance sampling) и адаптация распределений, направленные на снижение влияния нерепрезентативных выборок и обеспечение стабильности обучения.
Оптимизация Выборки: Эффективное Обучение с Подкреплением
Оптимальная выборка с отклонением по бюджету (OBRS) представляет собой метод снижения расхождений в траекториях обучения с подкреплением путем выборочного принятия только наиболее информативных примеров. В отличие от стандартной практики принятия всех сгенерированных траекторий, OBRS оценивает каждую траекторию на основе определенного критерия (например, ожидаемой награды) и принимает ее только в том случае, если она соответствует заданному бюджету. Это позволяет отсеивать траектории с низкой вероятностью успеха или высокой дисперсией, что, в свою очередь, способствует повышению стабильности обучения и снижению вариативности результатов. Использование OBRS особенно эффективно в задачах, где процесс генерации траекторий является стохастическим и подвержен значительным колебаниям.
Комбинирование метода Optimal Budget Rejection Sampling (OBRS) с Top-k Sampling позволяет значительно повысить эффективность обучения с подкреплением за счет фокусировки на наиболее вероятных токенах при генерации траекторий. Top-k Sampling ограничивает пространство поиска наиболее вероятными k токенами, что снижает вычислительные затраты по сравнению с полным перебором. Применение OBRS совместно с Top-k Sampling позволяет выборочно принимать только наиболее качественные траектории, отфильтровывая менее информативные, что дополнительно снижает вычислительную нагрузку и ускоряет процесс обучения. Такой подход позволяет достичь оптимального баланса между качеством сэмплирования и вычислительными ресурсами, делая обучение больших моделей более практичным.
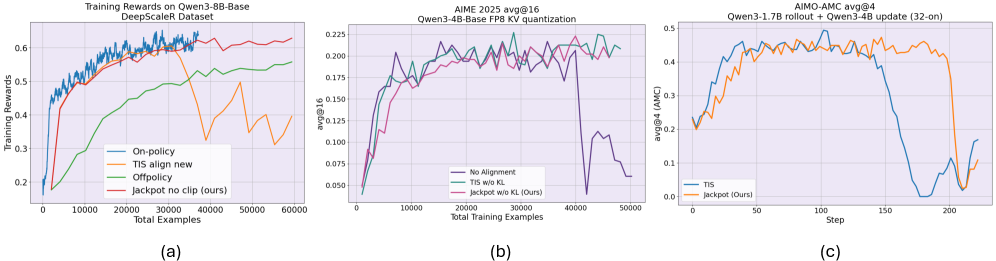
Для ускорения процесса генерации траекторий, необходимого для обучения с подкреплением (RL) с использованием больших моделей, применяются методы квантизации и оптимизации инференса. В частности, разработанный подход Jackpot позволяет аппроксимировать нормализацию с сохранением более 87% точности, используя только топ-20 наиболее вероятных токенов. При этом, вычислительные издержки, связанные с применением Jackpot, составляют менее 3%, что делает его эффективным решением для масштабирования RL-обучения на большие модели и уменьшения времени генерации траекторий.
Jackpot: Унифицированная Платформа для Обучения с Подкреплением Языковых Моделей
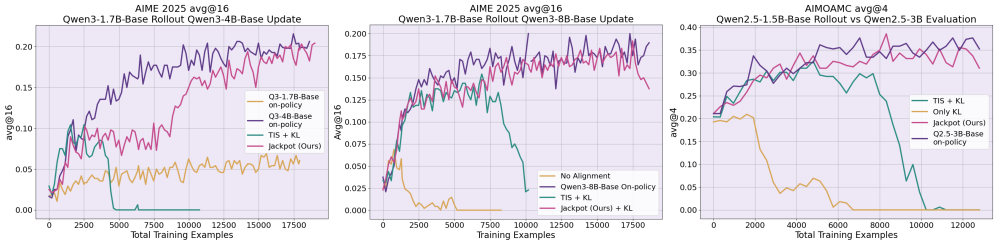
Разработанная система Jackpot объединяет в себе стратегии OBRS (Off-policy Batch Reinforcement Learning with Sample Reuse) и Top-k sampling в единую, оптимизированную структуру обучения с подкреплением, специально адаптированную для больших языковых моделей. Такой подход позволяет эффективно использовать накопленный опыт, избегая необходимости повторного обучения на одних и тех же данных, что значительно повышает эффективность процесса. В частности, Top-k sampling, ограничивая выбор наиболее вероятными вариантами, способствует стабилизации обучения и предотвращает генерацию нерелевантного или бессмысленного текста. Интеграция этих двух методов в единую структуру обучения создает мощный инструмент для точной настройки языковых моделей и достижения высоких результатов в различных задачах, требующих генерации осмысленного и релевантного контента.
В основе системы Jackpot лежит эффективное обучение с подкреплением вне политики, достигаемое благодаря использованию эталонной политики. Этот подход значительно повышает эффективность использования данных и устойчивость обучения больших языковых моделей. Эксперименты показали, что Jackpot способен поддерживать стабильное обучение на протяжении как минимум 300 шагов, что является существенным улучшением по сравнению с предыдущими методами, которые часто демонстрируют нестабильность и приводят к коллапсу процесса обучения. Использование эталонной политики позволяет модели извлекать полезную информацию из данных, собранных другими стратегиями, что существенно снижает потребность в новых, дорогостоящих данных и ускоряет процесс оптимизации.
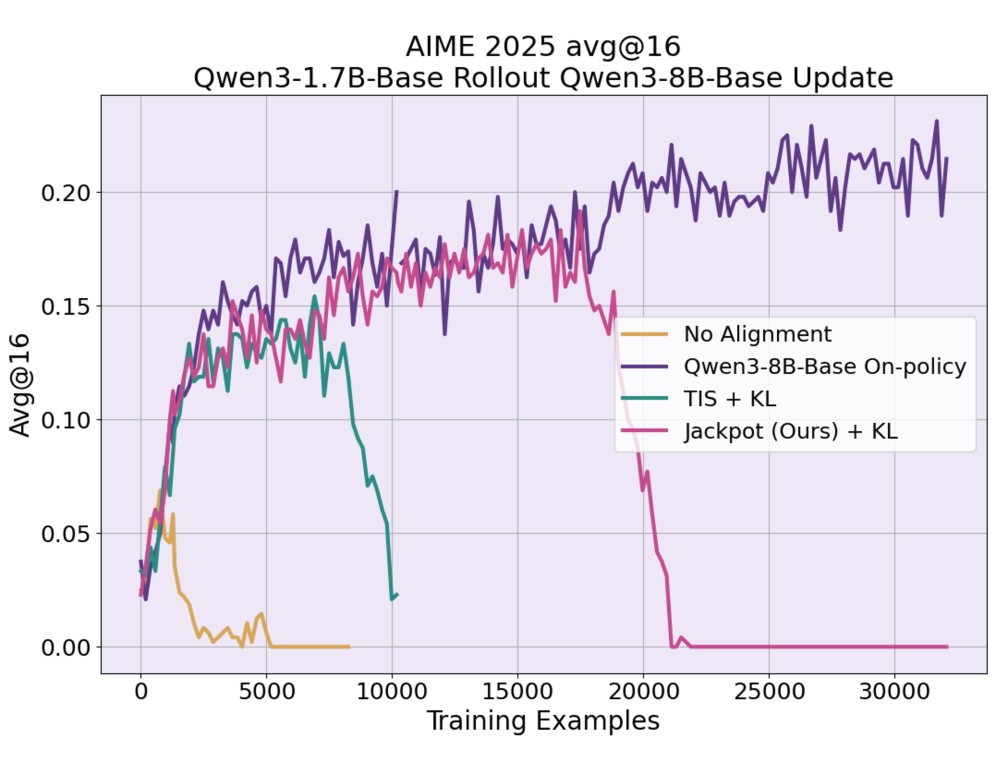
В рамках разработанной системы Jackpot, для обеспечения стабильности обучения языковых моделей, применяются методы Trust Region в алгоритме PPO. Такой подход позволяет ограничивать изменения в политике модели на каждом шаге, эффективно предотвращая резкое ухудшение производительности и обеспечивая устойчивое обучение. Результаты экспериментов демонстрируют, что Jackpot достигает сопоставимой точности с методами обучения на основе прямых взаимодействий (on-policy) в решении сложных математических задач, включая бенчмарки AMC, MATH500, AIME24 и GSM8K. Это свидетельствует о высокой эффективности предложенного подхода к обучению с подкреплением и его потенциале для применения в различных областях, требующих решения сложных логических и вычислительных задач.
К Более Адаптивным и Интеллектуальным Языковым Агентам
Эффективность алгоритма Jackpot открывает принципиально новые перспективы для непрерывного обучения и адаптации больших языковых моделей (LLM) непосредственно в реальных условиях эксплуатации. В отличие от традиционных методов, требующих огромных объемов размеченных данных и дорогостоящей переподготовки, Jackpot позволяет модели совершенствоваться в процессе взаимодействия с окружающей средой, используя лишь небольшое количество обратной связи. Это особенно важно для приложений, где данные постоянно меняются или сложно получить размеченные примеры, например, в системах диалогового искусственного интеллекта или автономных агентах. Возможность динамической адаптации позволяет LLM оставаться актуальными и эффективными, преодолевая ограничения статических моделей и приближая их к уровню человеческого интеллекта, способного к обучению на протяжении всей жизни.
Исследования, направленные на усовершенствование методов выборки и алгоритмов обучения с подкреплением вне политики, демонстрируют значительный потенциал для повышения эффективности использования данных при обучении больших языковых моделей. В частности, разработка более сложных стратегий отбора наиболее информативных примеров и алгоритмов, позволяющих использовать накопленный опыт повторно, без необходимости повторного прохождения всего процесса обучения, может существенно снизить вычислительные затраты и время, необходимые для адаптации моделей к новым задачам и средам. Перспективные направления включают в себя изучение алгоритмов, способных эффективно оценивать качество полученных выборок и динамически адаптировать стратегию отбора, а также разработку новых методов для обобщения опыта, полученного в различных ситуациях. Дальнейшее развитие этих технологий открывает возможности для создания более гибких и эффективных языковых агентов, способных к непрерывному обучению и адаптации в реальных условиях.
Надежное обучение больших языковых моделей (LLM) с использованием обучения с подкреплением (RL) представляет собой ключевой шаг на пути к созданию по-настоящему интеллектуальных агентов, способных к сложным рассуждениям и решению проблем. В отличие от традиционных методов обучения, основанных на огромных объемах размеченных данных, RL позволяет LLM учиться посредством взаимодействия со средой и получения обратной связи, что имитирует человеческий процесс обучения. Это открывает возможности для адаптации к новым задачам и ситуациям без необходимости повторного обучения на новых данных. Успешное применение RL к LLM позволит создавать агентов, способных не просто генерировать текст, но и планировать действия, принимать решения и эффективно взаимодействовать с окружающим миром, приближая искусственный интеллект к уровню человеческого интеллекта.
Работа демонстрирует неизбежную борьбу между теорией и практикой. Авторы предлагают Jackpot — элегантное решение для обучения больших языковых моделей в условиях расхождения политик, используя оптимальную выборку с отбраковкой. Однако, за каждым «революционным» подходом скрывается компромисс. Неизбежно возникнет вопрос о вычислительных затратах и необходимости тонкой настройки параметров. Как говорил Алан Тьюринг: «Мы можем только надеяться, что машины не станут слишком умными». В данном случае, «умная» система обучения потребует от инженеров ещё больше усилий для поддержания её работоспособности и предотвращения нежелательных последствий. Эта работа — ещё одно подтверждение того, что даже самые изящные алгоритмы рано или поздно столкнутся с суровой реальностью продакшена.
Куда это всё ведёт?
Предложенный подход, безусловно, позволяет отодвинуть момент неминуемого коллапса при обучении языковых моделей в рамках обучения с подкреплением. Однако, не стоит обольщаться. Проблема несоответствия между политикой развертывания и обученной политикой не исчезла, она лишь временно смягчена. Вполне вероятно, что сейчас это назовут AI и получат инвестиции, но в конечном итоге, всё упрётся в вычислительные ресурсы и необходимость в ещё более изощрённых методах отбора. Каждый «революционный» алгоритм завтра станет техдолгом, который придётся оплачивать новыми серверами.
Более того, акцент на оптимальном бюджете отбора, хоть и оправдан с точки зрения эффективности, лишь откладывает решение более фундаментальной задачи: как научить агента строить внутреннюю модель мира, а не полагаться на случайные блуждания в пространстве политик. Вспомните, как всё начиналось: с простого bash-скрипта, который решал задачу, а потом… Потом появилась сложная система, которую никто не понимает. Очевидно, что дальнейшие исследования должны быть направлены на повышение устойчивости к сдвигу распределений и разработку методов, которые позволят агенту адаптироваться к изменениям в окружающей среде без полной переподготовки.
Начинаю подозревать, что все эти сложные вычисления KL-дивергенции — лишь способ замаскировать отсутствие истинного понимания. Ведь в конечном итоге, документация снова соврет, и кто-то снова будет отлаживать код в продакшене. Технический долг — это просто эмоциональный долг с коммитами.
Оригинал статьи: https://arxiv.org/pdf/2602.06107.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Прогноз нефти
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Bitcoin: STRC vs. ETF, Шорты на Акциях и Новые Фиатные Каналы – Что Ждет Рынок? (28.05.2026 03:15)
- МФК Займер акции прогноз. Цена ZAYM
- Сегежа акции прогноз. Цена SGZH
- Самый умный криптовалютный выбор на 500 долларов (XRP)
- ETF: Двойной успех к 2026 году
2026-02-09 21:25