Автор: Денис Аветисян
Новое исследование показывает, как оптимизировать затраты и производительность при решении задач классификации текста в реальных условиях.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал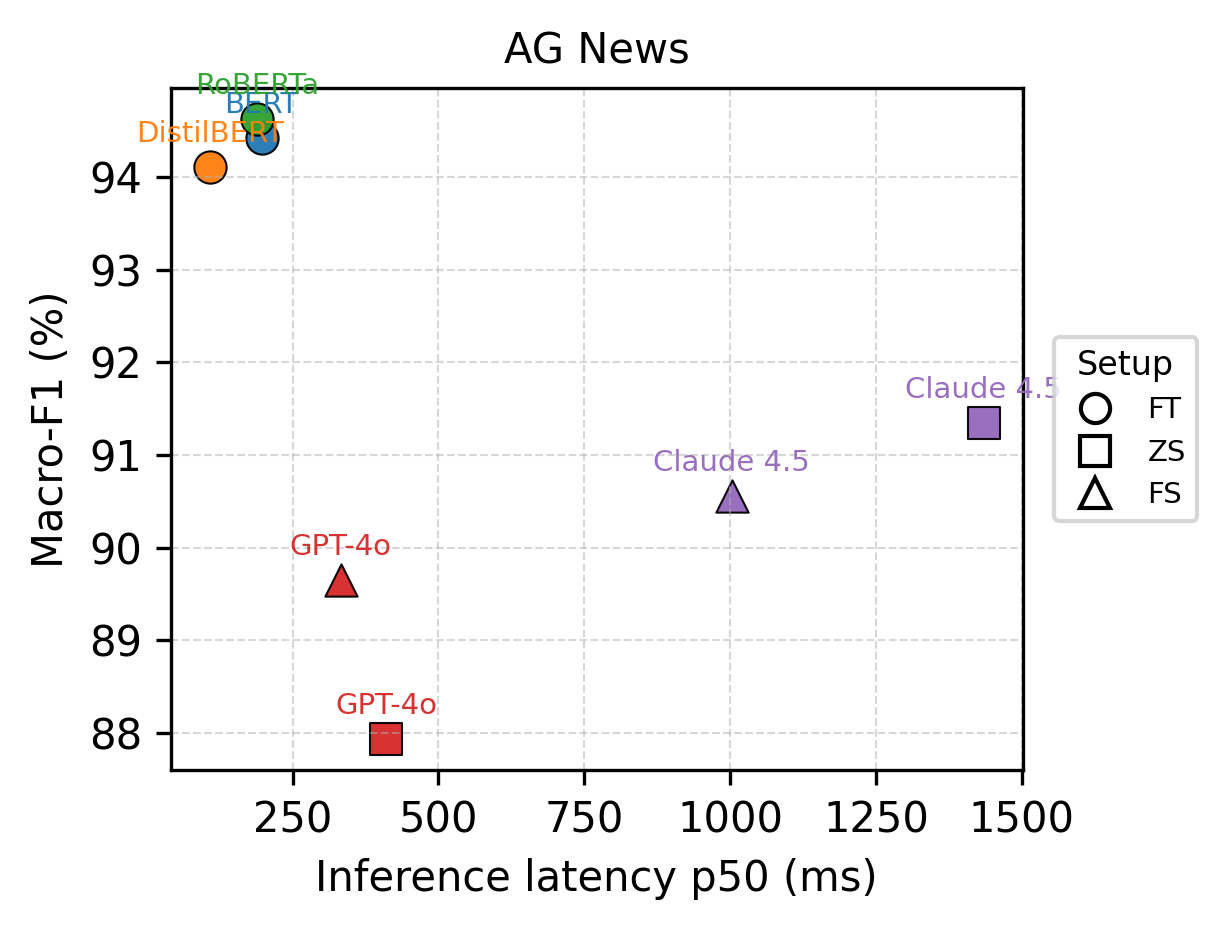
Сравнение подходов: точная настройка энкодеров против использования больших языковых моделей для задач фиксированной классификации текста.
Несмотря на впечатляющие возможности больших языковых моделей в генерации и понимании текста, выбор оптимальной модели для задач классификации с фиксированным набором меток часто ограничивается только метриками производительности. В данной работе, ‘Cost-Aware Model Selection for Text Classification: Multi-Objective Trade-offs Between Fine-Tuned Encoders and LLM Prompting in Production’, представлено систематическое сравнение подходов, основанных на LLM-промптах и тонкой настройке энкодерных архитектур. Полученные результаты демонстрируют, что модели на основе BERT обеспечивают сопоставимую, а зачастую и превосходящую, точность классификации при значительно меньших затратах и задержках по сравнению с LLM. Является ли повсеместное использование больших языковых моделей для стандартных задач классификации текстов оптимальным решением, или же тонко настроенные энкодеры представляют собой более эффективный и экономичный выбор для структурированных NLP-конвейеров?
Основы классификации текста: современный ландшафт
Классификация текста является фундаментальным элементом обработки естественного языка (NLP), обеспечивая функционирование широкого спектра приложений. От анализа тональности, определяющего эмоциональную окраску текста, до автоматической рубрикации новостных статей и определения тематической принадлежности документов — эта задача лежит в основе многих современных технологий. Способность эффективно разделять текст по категориям позволяет автоматизировать обработку больших объемов информации, извлекать ключевые сведения и предоставлять пользователям релевантный контент. Именно поэтому классификация текста представляет собой важнейший компонент в задачах, связанных с поиском информации, анализом социальных медиа и созданием интеллектуальных систем.
Для оценки эффективности и сопоставления различных моделей классификации текста используются стандартизированные наборы данных, такие как AG News, специализирующийся на новостных категориях, SST-2, предназначенный для анализа тональности, IMDB, содержащий рецензии на фильмы, и DBPedia, представляющий собой базу знаний, структурированную в виде онтологии. Эти наборы данных позволяют исследователям объективно сравнивать производительность алгоритмов, выявлять сильные и слабые стороны каждой модели и отслеживать прогресс в области обработки естественного языка. Использование этих общедоступных ресурсов обеспечивает воспроизводимость результатов и способствует развитию более эффективных и надежных систем автоматической классификации текстов, необходимых для широкого спектра практических приложений.
Традиционные методы классификации текста часто сталкиваются с компромиссом между точностью и вычислительными затратами. Достижение высокой производительности нередко требует значительных ресурсов, что делает их непригодными для задач, требующих быстрого анализа больших объемов данных. В связи с этим, активно разрабатываются новые подходы, в частности, методы, основанные на тонкой настройке энкодерных моделей. Исследования показывают, что такие модели способны демонстрировать на два порядка величины меньшие затраты на инференс по сравнению с крупными языковыми моделями, сохраняя при этом сопоставимый или даже более высокий уровень точности. Это делает их особенно привлекательными для практических приложений, где важна не только результативность, но и эффективность использования ресурсов.
Масштаб и эффективность: большие языковые модели и тонко настроенные энкодеры
Большие языковые модели (LLM) демонстрируют впечатляющие возможности в обработке и генерации текста, однако их значительный размер является причиной высокой задержки при выводе данных (inference latency) и, как следствие, высоких эксплуатационных расходов. Количество параметров в LLM часто исчисляется миллиардами, что требует значительных вычислительных ресурсов для выполнения даже простых задач. Это проявляется в увеличении времени ответа и повышении стоимости использования инфраструктуры, особенно при обработке больших объемов запросов или в режиме реального времени. Таким образом, несмотря на свои преимущества, масштаб LLM является существенным ограничением для некоторых приложений, требующих высокой производительности и экономичности.
В отличие от больших языковых моделей (LLM), требующих значительных вычислительных ресурсов, модели-энкодеры, такие как BERT и RoBERTa, обеспечивают более эффективную альтернативу. Они достигают высокой производительности, используя значительно меньшее количество параметров, что напрямую влияет на скорость обработки запросов. В то время как LLM демонстрируют задержку, превышающую 100 мс, энкодеры способны обрабатывать запросы с задержкой менее 100 мс. Это снижение задержки достигается за счет оптимизации архитектуры и уменьшения количества параметров, что позволяет снизить требования к вычислительной мощности и повысить пропускную способность системы.
Модели-энкодеры, такие как BERT и RoBERTa, демонстрируют высокую эффективность в задачах обучения с учителем, однако для достижения оптимальных результатов часто требуется значительный объем размеченных данных. Несмотря на эту потребность, использование энкодеров позволяет существенно снизить затраты на обработку запросов. В частности, при обработке миллиона запросов, стоимость может быть снижена в 100 раз по сравнению с использованием больших языковых моделей, что делает их экономически привлекательным решением для задач, где доступен достаточно большой объем размеченных данных.
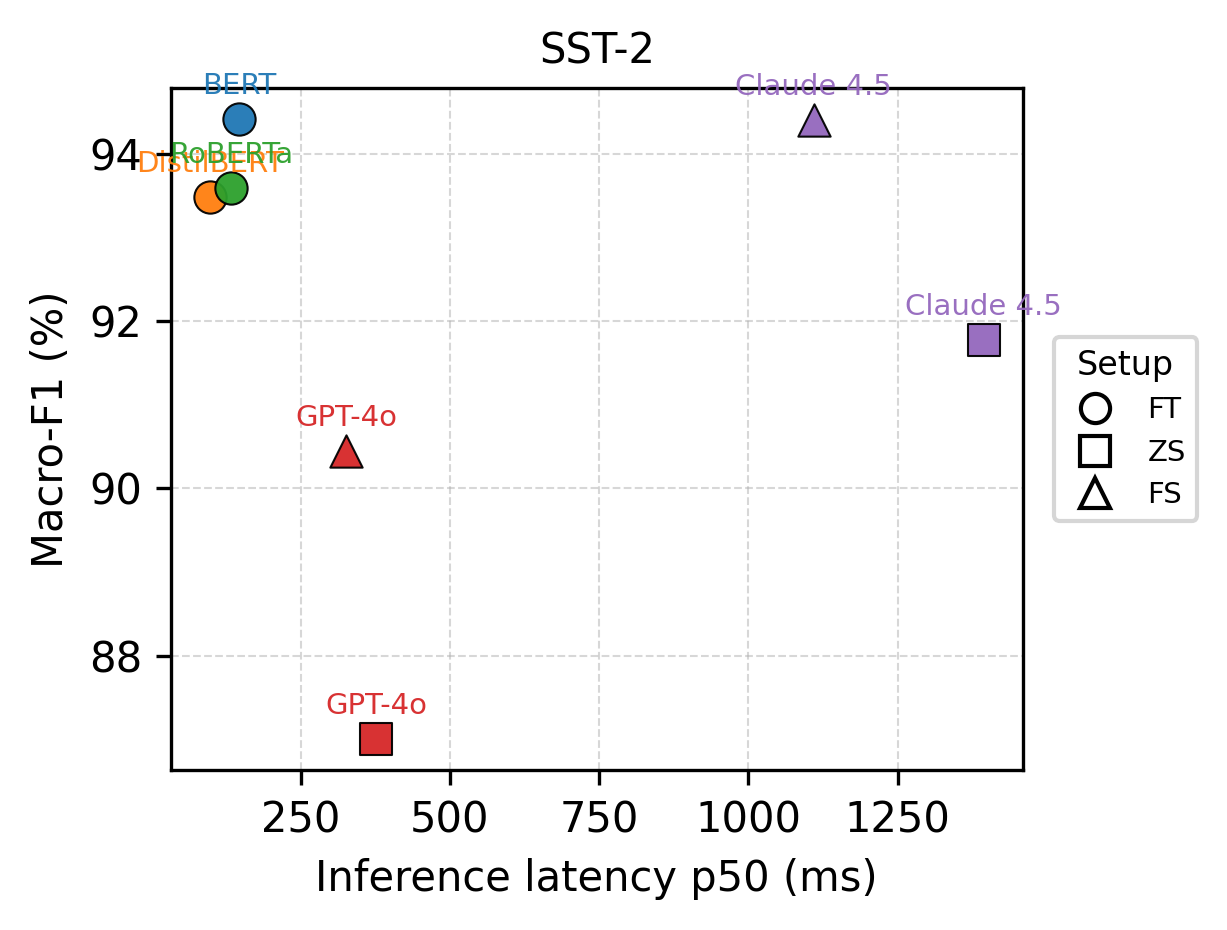
Преодолевая дефицит данных: адаптация к ограниченным ресурсам
Обучение с малым количеством примеров (Few-Shot Learning) представляет собой подход к машинному обучению, позволяющий моделям обобщать информацию и выполнять задачи, используя лишь ограниченное число обучающих данных — часто всего несколько примеров на класс или задачу. Этот метод демонстрирует высокую адаптивность, особенно в ситуациях, когда сбор больших размеченных датасетов затруднителен или невозможен. В отличие от традиционного обучения, требующего сотен или тысяч примеров, Few-Shot Learning использует предварительно обученные модели и механизмы, такие как метрическое обучение или мета-обучение, для эффективной экстраполяции знаний на новые, ранее не встречавшиеся данные. Способность к быстрому обучению на небольшом объеме данных делает этот подход перспективным для решения широкого спектра задач, включая распознавание образов, обработку естественного языка и робототехнику.
Обучение без единого примера (Zero-Shot Learning) представляет собой подход в машинном обучении, позволяющий моделям выполнять задачи, для которых не было предоставлено ни одного обучающего примера, специфичного для этой задачи. Это достигается за счет использования предварительно полученных знаний и способности к обобщению, позволяющих модели применять изученные концепции к новым, ранее не встречавшимся ситуациям. Модель опирается на понимание семантических связей и отношений между различными концепциями, а также на общую структуру данных, чтобы успешно решать задачу без прямой тренировки на ее специфических примерах. Такой подход особенно полезен в сценариях, где получение размеченных данных является затруднительным или невозможным.
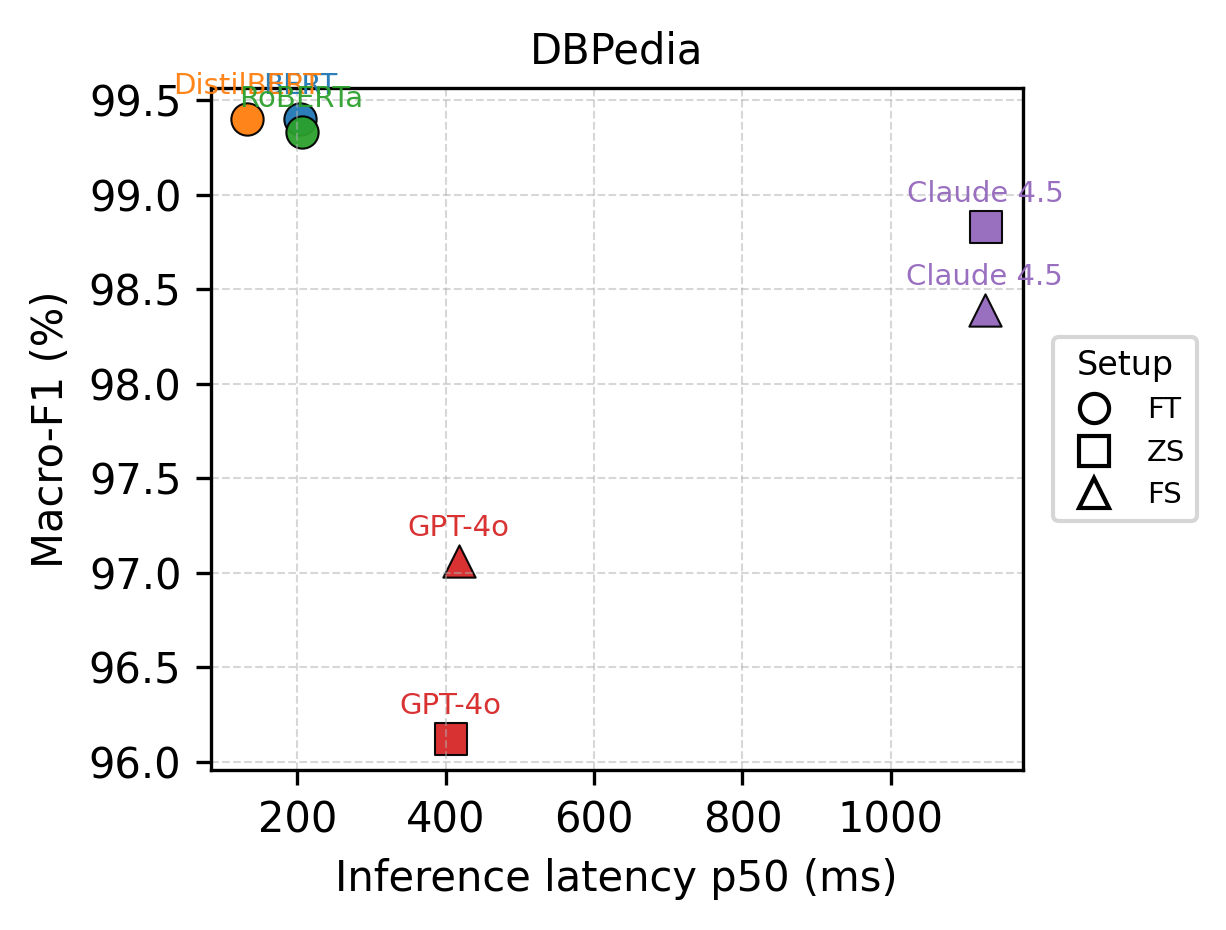
Большие языковые модели (LLM) демонстрируют высокую эффективность в задачах обучения с малым количеством данных (few-shot learning) и без данных (zero-shot learning) благодаря своему обширному объему предварительных знаний. В отличие от традиционных моделей, требующих значительных объемов размеченных данных для каждой конкретной задачи, LLM способны к быстрой адаптации к новым задачам, используя накопленные знания. Экспериментальные данные показывают, что LLM, использующие предварительно обученные энкодеры, достигают сопоставимой точности с моделями, обученными на больших наборах данных, на различных задачах классификации текста, включая IMDB (анализ тональности), SST-2 (анализ тональности), AG News (классификация новостей) и DBpedia (классификация онтологий).
Оптимизация компромисса: экономически обосноранный выбор модели
При выборе оптимальной модели машинного обучения необходимо учитывать не только её точность, но и связанные с ней затраты на вычислительные ресурсы и время отклика. Традиционно, акцент делался на достижение максимально возможной точности, однако в реальных приложениях, особенно при работе с ограниченными ресурсами или в режиме реального времени, критически важными становятся такие параметры, как задержка при выводе данных (inference latency) и общая стоимость вычислений. Выбор модели, которая обеспечивает наилучший баланс между точностью и этими факторами, позволяет существенно повысить эффективность и практическую применимость системы, открывая возможности для развертывания сложных моделей на устройствах с ограниченной мощностью или в средах, требующих высокой скорости обработки данных. Игнорирование этих аспектов может привести к созданию решений, которые, несмотря на высокую точность, оказываются неэффективными или непригодными для использования на практике.
Многоцелевая оптимизация представляет собой мощный подход к решению задач, где существуют конкурирующие цели, такие как точность и вычислительные затраты. Вместо поиска единственного оптимального решения, этот метод позволяет определить набор компромиссных вариантов, каждый из которых представляет собой наилучший баланс между различными критериями. По сути, он позволяет исследователям и разработчикам не просто максимизировать производительность, но и учитывать ограничения, связанные с ресурсами и временем. В результате получается не единая точка оптимума, а так называемая парето-оптимальная область, предоставляющая возможность выбора наиболее подходящего решения в зависимости от конкретных приоритетов и условий применения. Такой подход особенно ценен в контексте современных моделей машинного обучения, где увеличение точности часто требует значительных вычислительных ресурсов.
Парето-фронт представляет собой множество решений, где невозможно улучшить один параметр, не ухудшив другой. В контексте выбора моделей машинного обучения это означает, что нельзя одновременно повысить точность и снизить вычислительные затраты. Исследования показали, что тонко настроенные энкодеры демонстрируют более выгодное соотношение между точностью и стоимостью по сравнению с большими языковыми моделями, последовательно занимая более предпочтительные позиции на Парето-фронте. Это указывает на то, что при оптимизации моделей необходимо учитывать не только метрики производительности, но и экономическую целесообразность, а именно — баланс между требуемой точностью и доступными вычислительными ресурсами. Полученные результаты подчеркивают важность многоцелевой оптимизации при выборе наиболее эффективного решения для конкретной задачи.
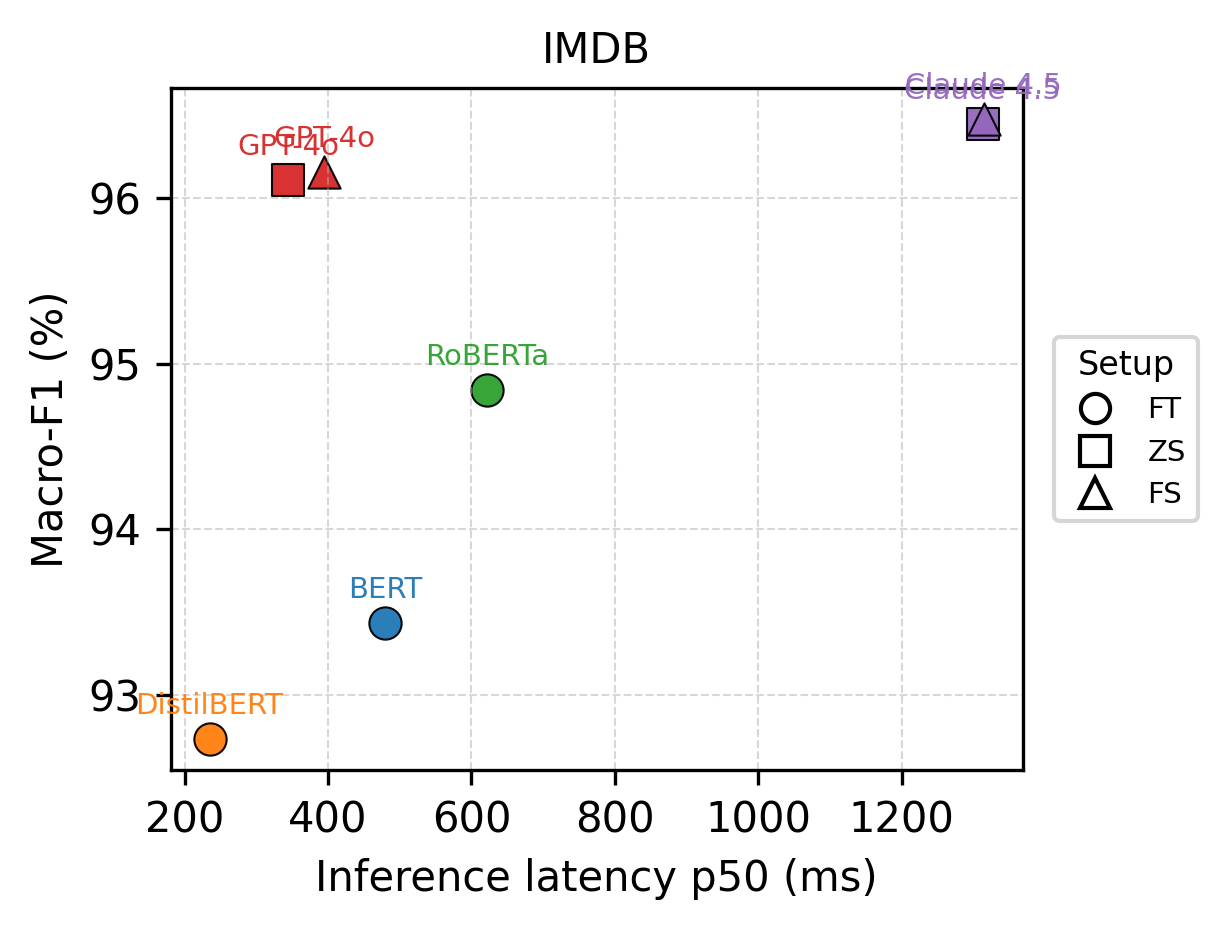
Исследование демонстрирует, что при выборе моделей для классификации текста в производственной среде, необходимо учитывать не только точность, но и стоимость и задержку. Авторы подчеркивают, что fine-tuned энкодеры зачастую превосходят большие языковые модели по этим параметрам, что особенно важно для задач с фиксированным набором меток. Как однажды заметила Барбара Лисков: «Хорошо спроектированные системы должны быть способны адаптироваться к изменениям, не теряя при этом своей сути». Это наблюдение напрямую соотносится с необходимостью создания гибких и экономически эффективных систем классификации текста, способных поддерживать высокую производительность в течение длительного времени, несмотря на изменяющиеся требования и доступные ресурсы.
Что дальше?
Представленные результаты, хотя и демонстрируют превосходство точно настроенных кодировщиков в конкретном контексте классификации текстов с фиксированными метками, лишь временно отсрочивают неизбежное. Подобно любой архитектуре, и здесь существует предел масштабируемости. Постоянное наращивание параметров, даже в точно настроенных моделях, в конечном итоге столкнётся с законом убывающей отдачи, а затем и с неминуемым увеличением затрат. Вопрос не в том, чтобы найти «лучшую» модель, а в том, как долго можно поддерживать её работоспособность в условиях меняющейся среды.
Очевидным направлением для будущих исследований представляется изучение гибридных подходов, в которых преимущества больших языковых моделей и точно настроенных кодировщиков комбинируются не на уровне архитектуры, а на уровне стратегии развертывания. Более того, необходимо учитывать не только метрики производительности и стоимости, но и устойчивость системы к концептуальному дрейфу — способности адаптироваться к изменениям в данных без существенной потери точности. Каждая абстракция несет груз прошлого, и эта инерция будет лишь усиливаться со временем.
В конечном счете, наиболее перспективным представляется отход от идеи поиска оптимальной модели в пользу разработки самоадаптирующихся систем, способных эволюционировать вместе с данными. Медленные изменения сохраняют устойчивость, и именно этот принцип должен лежать в основе будущих исследований в области обработки естественного языка. Попытки создать «вечную» модель обречены на провал; важно лишь отсрочить этот момент как можно дальше.
Оригинал статьи: https://arxiv.org/pdf/2602.06370.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Прогноз нефти
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Bitcoin: STRC vs. ETF, Шорты на Акциях и Новые Фиатные Каналы – Что Ждет Рынок? (28.05.2026 03:15)
- МФК Займер акции прогноз. Цена ZAYM
- Сегежа акции прогноз. Цена SGZH
- Самый умный криптовалютный выбор на 500 долларов (XRP)
- ETF: Двойной успех к 2026 году
2026-02-10 04:23