Автор: Денис Аветисян
В статье представлена инновационная методика, использующая возможности больших языковых моделей для адаптивного выбора функций приобретения в байесовской оптимизации.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал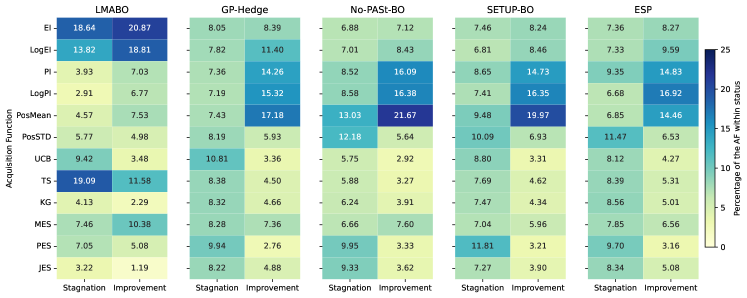
Предложенная система LMABO динамически подбирает функции приобретения, используя информацию о состоянии оптимизации, что позволяет превзойти существующие методы.
Выбор функции приобретения является критическим фактором в байесовской оптимизации, однако не существует универсальной стратегии, оптимальной для всех задач. В работе ‘Adaptive Acquisition Selection for Bayesian Optimization with Large Language Models’ предложен новый подход, использующий предварительно обученную большую языковую модель (LLM) в качестве онлайн-стратега для динамического выбора функции приобретения. Предложенная схема LMABO демонстрирует значительное улучшение производительности на 50 стандартных задачах по сравнению с существующими статическими и адаптивными методами, благодаря способности синтезировать информацию о состоянии оптимизации в эффективную политику. Способна ли эта технология открыть новые горизонты в адаптивной оптимизации и автоматизированном машинном обучении?
Вызовы дорогостоящей оптимизации: пророчество о будущих сбоях
Многие задачи в реальном мире требуют оптимизации так называемых “черных ящиков” — функций, оценка которых сопряжена со значительными затратами времени или ресурсов. Это означает, что каждое вычисление значения функции — будь то моделирование молекулярной структуры, проведение дорогостоящего эксперимента, или обучение сложной нейронной сети — требует существенных усилий. В отличие от математических функций, для которых можно аналитически вычислить производные и использовать классические методы оптимизации, “черные ящики” не предоставляют такой возможности. Поэтому поиск оптимального решения становится особенно сложной задачей, требующей разработки новых подходов, способных эффективно исследовать пространство параметров при ограниченном количестве вычислений.
Традиционные методы оптимизации часто оказываются неэффективными при работе с так называемыми “черными ящиками” — функциями, оценка которых требует значительных ресурсов или времени. Суть проблемы заключается в том, что для достижения приемлемого решения требуется огромное количество вычислений. Вместо того чтобы разумно исследовать пространство параметров, эти методы зачастую прибегают к слепому перебору, особенно в случаях, когда функция сложна и не имеет аналитического представления. Это приводит к экспоненциальному росту вычислительных затрат по мере увеличения размерности задачи, делая оптимизацию практически невозможной для многих реальных приложений, включая поиск новых материалов, разработку лекарств и настройку гиперпараметров сложных моделей машинного обучения. В результате, поиск оптимальных решений становится не только трудоемким, но и дорогостоящим, что существенно замедляет прогресс в соответствующих областях.
Неэффективность оптимизационных процессов оказывает существенное влияние на прогресс в таких областях, как материаловедение, разработка лекарственных препаратов и настройка гиперпараметров. В материаловедении, поиск новых материалов с заданными свойствами требует оценки огромного количества комбинаций, а каждая оценка может включать сложные и дорогостоящие симуляции или эксперименты. Аналогично, в фармацевтике, процесс разработки новых лекарств сталкивается с необходимостью оптимизации молекулярных структур для достижения максимальной эффективности и безопасности, что также требует значительных вычислительных ресурсов и времени. Наконец, при настройке гиперпараметров моделей машинного обучения, каждый эксперимент с различными параметрами требует обучения и оценки модели, что может быть крайне затратным, особенно для сложных моделей и больших наборов данных. Таким образом, повышение эффективности оптимизации становится ключевым фактором для ускорения научных открытий и технологического прогресса в этих и других областях.
Байесовская оптимизация: бережливый подход к поиску оптимального
Байесовская оптимизация использует вероятностную суррогатную модель, например, гауссовский процесс (GP), для аппроксимации дорогостояемой целевой функции. Гауссовский процесс определяет распределение вероятностей над возможными функциями, позволяя оценить не только значение функции в конкретной точке, но и неопределенность этой оценки. В отличие от прямого вычисления целевой функции, требующего значительных вычислительных ресурсов или времени, суррогатная модель позволяет быстро предсказывать значения целевой функции для новых точек, используя информацию о ранее оцененных точках. f(x) \sim \mathcal{GP}(\mu(x), k(x, x')), где \mu(x) — среднее значение, а k(x, x') — функция ковариации, определяющая зависимость между значениями функции в разных точках.
Использование вероятностной суррогатной модели, такой как гауссовский процесс, позволяет алгоритму байесовской оптимизации предсказывать производительность неисследованных точек в пространстве параметров. Вместо непосредственного вычисления дорогостоящей целевой функции для каждой точки, модель предоставляет оценку, основанную на предыдущих наблюдениях. Это значительно сокращает количество необходимых вычислений, особенно в задачах, где каждое вычисление требует значительных ресурсов или времени. Точность предсказания модели напрямую влияет на эффективность оптимизации, поэтому выбор подходящей суррогатной модели и её калибровка являются критически важными этапами. Чем точнее модель аппроксимирует целевую функцию, тем меньше дорогостоящих вычислений потребуется для достижения оптимального решения.
Функция приобретения (acquisition function) играет ключевую роль в оптимизации на основе Байесовского подхода, определяя следующую точку для оценки целевой функции. Она представляет собой компромисс между исследованием (exploration) — поиском областей пространства параметров с высокой неопределенностью, где потенциально могут находиться улучшения — и использованием (exploitation) — выбором точек, которые, согласно текущей модели, демонстрируют наилучшие прогнозные значения. Различные функции приобретения, такие как Probability of Improvement (PI), Expected Improvement (EI) и Upper Confidence Bound (UCB), используют разные стратегии для балансировки этих двух аспектов, учитывая как прогнозное значение \hat{y}(x) , так и неопределенность \sigma(x) модели в каждой точке x . Выбор функции приобретения влияет на скорость сходимости и эффективность алгоритма в поиске глобального оптимума.
Адаптивные функции приобретения: залог устойчивости к непредсказуемости
Различные функции приобретения (f(x), например, Expected Improvement (EI), Upper Confidence Bound (UCB) и Thompson Sampling) демонстрируют оптимальную производительность в различных сценариях оптимизации. EI эффективно находит обещающие области за счет максимизации ожидаемого улучшения по сравнению с текущим лучшим значением. UCB балансирует между исследованием (exploration) и использованием (exploitation) путем добавления компонента неопределенности к ожидаемому значению, что особенно полезно в задачах с высокой размерностью. Thompson Sampling, основанная на байесовском подходе, использует случайные выборки из апостериорного распределения, что обеспечивает эффективное исследование и адаптацию к меняющимся условиям. Выбор конкретной функции зависит от характеристик целевой функции, шума и доступных вычислительных ресурсов, при этом не существует универсально оптимального решения.
Предварительный выбор оптимальной функции приобретения (acquisition function) для байесовской оптимизации представляет значительную сложность, поскольку её эффективность сильно зависит от характеристик оптимизируемой функции и пространства поиска. Статичные стратегии, основанные на выборе единственной функции приобретения на начальном этапе, часто демонстрируют субоптимальные результаты при изменении ландшафта целевой функции или при исследовании многомерных пространств. В связи с этим, необходим динамический подход, позволяющий адаптировать выбор функции приобретения в процессе оптимизации, основываясь на текущей информации об исследованном пространстве и полученных результатах, что позволяет более эффективно балансировать между исследованием (exploration) и использованием (exploitation).
Портфельные стратегии в оптимизации байесовских методов предлагают решение проблемы выбора оптимальной функции приобретения, рассматривая её как задачу распределения ресурсов. Вместо использования одной функции, несколько функций приобретения (например, ожидаемое улучшение, верхняя доверительная граница, сэмплирование Томпсона) комбинируются, каждому из которых назначается вес, определяющий его вклад в процесс оптимизации. Веса динамически корректируются в процессе поиска, основываясь на производительности каждой функции в конкретной области пространства параметров. Однако, такой подход требует значительных вычислительных затрат, поскольку необходимо оценивать и обновлять веса для каждой функции приобретения на каждой итерации оптимизации, что может стать узким местом при работе с высокоразмерными пространствами параметров или при необходимости проведения большого числа итераций.
LMABO: разумный выбор функции приобретения с помощью больших языковых моделей
В основе подхода LMABO лежит использование большой языковой модели для анализа текущего состояния оптимизации. Эта модель рассматривает информацию о длинах масштаба гауссовских процессов GP Lengthscales и доступный бюджет, чтобы динамически выбирать наиболее перспективную функцию приобретения. Вместо жестко заданного выбора или использования фиксированных стратегий, LMABO способна оценивать контекст оптимизации и адаптироваться к нему, определяя, какая функция приобретения наиболее вероятно приведет к улучшению результата на текущем этапе. Этот процесс позволяет не только эффективно использовать доступные ресурсы, но и учитывать сложность ландшафта оптимизации, что существенно повышает эффективность поиска оптимального решения.
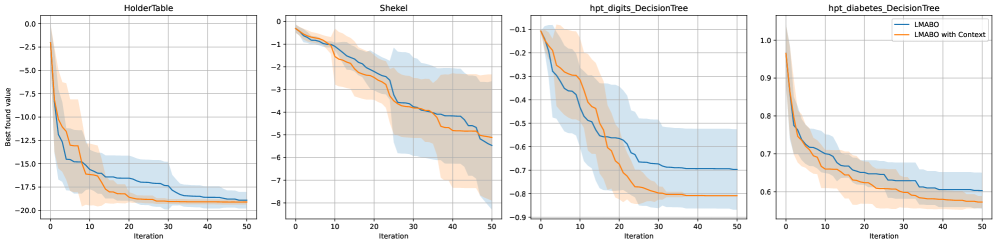
Метод LMABO демонстрирует способность к обучению без предварительной подготовки и адаптации к новым задачам оптимизации. В отличие от традиционных подходов, требующих обширных наборов данных для обучения, LMABO использует возможности больших языковых моделей для анализа текущего состояния оптимизации и динамического выбора наиболее перспективной функции приобретения. Это позволяет системе эффективно функционировать даже в тех случаях, когда отсутствует информация о специфике решаемой задачи, что значительно расширяет область ее применения и делает ее универсальным инструментом для различных областей науки и техники. Такой подход позволяет LMABO быстро адаптироваться к новым условиям и обеспечивать высокую производительность без необходимости в дополнительных настройках или переобучении.
В основе подхода LMABO лежит концепция онлайн-обучения, позволяющая системе непрерывно совершенствовать процесс выбора функции приобретения по мере поступления новых данных. В результате, LMABO демонстрирует значительное улучшение производительности — снижение общей площади под кривой ROC (AUC) на 16.6% по сравнению с лучшим адаптивным портфельным методом. Проведенные тесты на 50 различных задачах показали, что LMABO существенно превосходит как статические функции приобретения (на 9.7% ниже по AUC), так и простые мета-стратегии, а также другие подходы, основанные на больших языковых моделях (на 14.8% и 54.7% ниже по AUC соответственно). Такой подход позволяет LMABO динамически адаптироваться к особенностям каждой задачи оптимизации, обеспечивая более эффективный поиск оптимальных решений.
Представленная работа демонстрирует, что оптимизация — это не поиск идеального решения, а скорее создание условий для его эволюции. Как отмечал Клод Шеннон: «Информация — это не просто данные, а способность уменьшать неопределенность». LMABO, используя большие языковые модели для адаптивного выбора функций приобретения, не стремится к мгновенному успеху, а формирует систему, способную реагировать на изменения состояния оптимизации. Этот подход напоминает выращивание экосистемы, где каждый выбор архитектуры — это пророчество о будущем сбое, который, впрочем, лишь подталкивает систему к новым формам адаптации и устойчивости. Долгая стабильность, как известно, — признак скрытой катастрофы, а динамическая адаптация — залог выживания.
Что Дальше?
Представленная работа, несомненно, демонстрирует потенциал использования больших языковых моделей не как простых инструментов оптимизации, но как элементов развивающейся экосистемы поиска. Однако, иллюзия “интеллектуального” выбора функции приобретения лишь подчеркивает фундаментальную проблему: каждая архитектурная уловка — это пророчество о будущей точке отказа. Успех LMABO измеряется не текущей производительностью, а способностью адаптироваться к неизбежным изменениям в ландшафте оптимизации.
Следующим шагом видится не столько улучшение самой модели, сколько разработка методов осознанного мониторинга её «страхов» и предубеждений. Оптимизация — это не поиск идеального решения, а постоянное управление риском. Настоящая устойчивость начинается там, где кончается уверенность в непогрешимости алгоритма. Важно помнить, что мониторинг — это не просто сбор данных, а способ бояться осознанно.
Будущие исследования должны сосредоточиться на создании систем, способных не просто адаптироваться к изменениям, но и предвидеть их. Это потребует выхода за рамки традиционного машинного обучения и обращения к принципам самоорганизации и эволюции. Ведь системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить.
Оригинал статьи: https://arxiv.org/pdf/2602.07904.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Опасный онлайн: Как нейросети распознают травлю в испаноязычном интернете
- Институциональный интерес к блокчейну: токенизация, инфраструктура и перспективы рынка в $1 трлн (27.05.2026 19:45)
- Сегежа акции прогноз. Цена SGZH
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Ростелеком акции прогноз. Цена RTKM
- МФК Займер акции прогноз. Цена ZAYM
- Является ли депег sUSD концом для алгоритмических стейблкоинов? Получите полный обзор!
- Прогноз нефти
2026-02-10 17:40