Автор: Денис Аветисян
Новый подход позволяет алгоритмам обучения с подкреплением учитывать различные уровни риска при принятии решений, повышая их надежность и эффективность.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал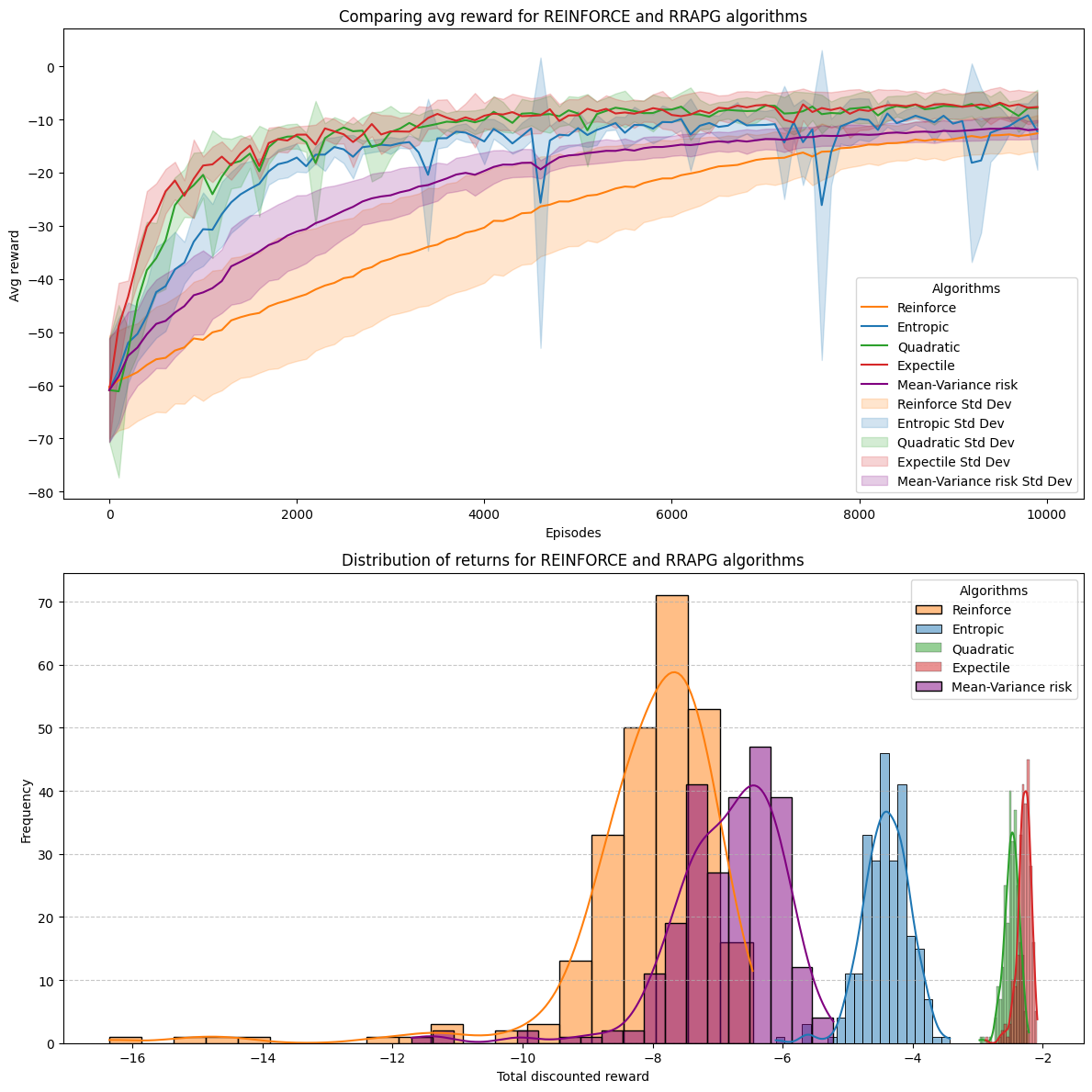
В статье представлен метод оптимизации политики, использующий меры риска, такие как ожидаемые значения и shortfall risk, для обучения агентов, чувствительных к риску.
Традиционные алгоритмы обучения с подкреплением часто не учитывают неприятие риска, что ограничивает их применение в критически важных приложениях. В данной работе, посвященной ‘Risk-sensitive reinforcement learning using expectiles, shortfall risk and optimized certainty equivalent risk’, предложены алгоритмы обучения с подкреплением, учитывающие риск, и использующие различные меры риска, включая ожидаемые значения, убытки и оптимизированный эквивалент определенности. Разработаны теоремы градиента политики для каждой меры риска и получены оценки скорости сходимости предложенных алгоритмов. Позволят ли эти разработки создать более надежные и эффективные системы принятия решений в условиях неопределенности и потенциальных убытков?
Риски в Обучении с Подкреплением: Когда Среднее Значение Обманывает
Традиционные алгоритмы обучения с подкреплением зачастую сосредоточены исключительно на максимизации ожидаемой награды, игнорируя при этом потенциальные риски и негативные последствия. Такой подход, ориентированный на среднее значение, может привести к формированию нестабильных стратегий, особенно в сложных и непредсказуемых средах. Вместо учета всего спектра возможных исходов, включая наихудшие сценарии, система может принимать решения, которые кажутся оптимальными в краткосрочной перспективе, но оказываются катастрофическими в долгосрочной. Это особенно критично в областях, где цена ошибки высока, таких как финансы, робототехника или здравоохранение, где необходимо учитывать не только потенциальную прибыль, но и вероятность убытков или нанесения вреда.
Традиционные алгоритмы обучения с подкреплением, сосредотачиваясь исключительно на максимизации ожидаемой награды, зачастую игнорируют потенциальные риски и непредсказуемость реальных ситуаций. Такой близорукий подход может привести к формированию нестабильных стратегий поведения, особенно в сложных, динамичных средах. Например, агент, обученный исключительно на средних показателях, может демонстрировать высокую производительность в лабораторных условиях, но потерпеть неудачу при столкновении с неожиданными событиями или экстремальными значениями. В результате, стратегии, кажущиеся оптимальными на основе усредненных данных, могут оказаться неэффективными или даже опасными в практическом применении, что подчеркивает необходимость учета всего спектра возможных исходов при принятии решений.
Эффективное принятие решений требует учета всего спектра возможных исходов, а не только среднего значения. В реальности, оценка лишь ожидаемой награды может привести к принятию рискованных стратегий, игнорирующих вероятность неблагоприятных событий. Исследования показывают, что системы, способные анализировать как положительные, так и отрицательные сценарии, демонстрируют повышенную устойчивость и надежность в сложных условиях. Такой подход позволяет формировать более консервативные, но в то же время эффективные политики, избегая катастрофических ошибок и обеспечивая стабильную работу даже при высокой неопределенности. Вместо оптимизации среднего выигрыша, акцент смещается на минимизацию потенциальных потерь и обеспечение приемлемого уровня риска, что критически важно для применений в областях, где цена ошибки высока.
Обучение с Учетом Риска: Новый Взгляд на Градиентные Методы
Предлагаемый метод обучения с подкреплением, основанный на градиентах политики с учетом риска, является расширением стандартных алгоритмов обучения с подкреплением. В отличие от традиционных методов, максимизирующих только ожидаемую награду, данный подход включает в себя оптимизацию с учетом мер риска. Это достигается путем модификации функции потерь, добавляя компоненты, отражающие нежелательные отклонения от ожидаемого значения. В частности, мы используем CVaR (Conditional Value-at-Risk) и σ (стандартное отклонение) в качестве мер риска, которые напрямую влияют на процесс обновления политики, что позволяет агенту не только максимизировать награду, но и минимизировать потенциальные потери.
Предлагаемый метод позволяет агентам обучаться стратегиям, которые не только максимизируют ожидаемую награду, но и минимизируют потенциальные потери. Это достигается путем включения в функцию потерь компонента, оценивающего риск, что позволяет агенту учитывать не только среднее значение получаемой награды, но и ее дисперсию или другие показатели риска. Таким образом, агент стремится к более стабильной и надежной стратегии, избегая действий, которые могут привести к значительным убыткам, даже если они имеют высокую ожидаемую награду. Обучение происходит посредством градиентного спуска, модифицированного для учета компоненты риска, что обеспечивает оптимизацию как ожидаемой награды, так и минимизацию потенциальных потерь.
Оптимизация с учетом риска направлена на повышение устойчивости и надежности агентов обучения с подкреплением за счет прямого включения показателей риска в функцию потерь. Вместо максимизации только ожидаемой награды, алгоритм стремится к балансу между получением высоких вознаграждений и минимизацией потенциальных убытков. Это достигается путем модификации стандартных методов градиентного спуска для учета не только среднего значения вознаграждения, но и его дисперсии или других метрик риска, таких как CVaR (Conditional Value-at-Risk). В результате, агенты, обученные таким образом, демонстрируют повышенную способность к функционированию в условиях неопределенности и снижают вероятность катастрофических ошибок, что критически важно для применения в реальных системах, например, в финансах или автономном управлении.
Количественная Оценка Риска: Инструменты и Метрики
В рамках разработанной системы оценки рисков используются различные метрики для количественной оценки потенциальных негативных последствий действий агента. К таким метрикам относятся, в частности, Value at Risk (VaR), Conditional Value at Risk (CVaR) и стандартное отклонение ожидаемой награды. CVaR, также известная как Expected Shortfall, рассчитывает средний убыток, превышающий VaR, обеспечивая более полное представление о риске в «хвосте» распределения наград. Использование нескольких метрик позволяет учесть различные аспекты риска, такие как вероятность неблагоприятного исхода и величина потенциальных потерь, предоставляя более детализированную оценку, чем использование одной единственной метрики.
Использование различных метрик риска позволяет получить более детальное представление о соотношении между потенциальной прибылью и возможными потерями, что критически важно для принятия обоснованных решений в обучении с подкреплением. Вместо упрощенного анализа ожидаемой выгоды, агент учитывает не только среднее значение вознаграждения, но и его дисперсию, а также другие показатели, характеризующие вероятность неблагоприятных исходов. Это позволяет агенту оценивать риски, связанные с каждым действием, и выбирать стратегии, оптимизированные не только по ожидаемому вознаграждению, но и по уровню риска, что особенно важно в задачах, где недопустимы значительные потери или катастрофические сценарии. Например, можно использовать CVaR (Conditional Value-at-Risk) или другие меры, чувствительные к «хвостам» распределения вознаграждений, чтобы минимизировать вероятность крупных убытков.
В рамках предложенного подхода, метрики риска интегрируются непосредственно в процесс обновления градиента политики. Это достигается путем модификации функции потерь, добавляя штраф за действия, приводящие к высоким значениям выбранных метрик риска. В результате, при обучении с подкреплением, агент не только максимизирует ожидаемую награду, но и минимизирует потенциальные негативные последствия, что приводит к формированию политики, характеризующейся более благоприятным профилем риска. Математически, это выражается модификацией градиента политики с учетом производной от функции риска по отношению к параметрам политики, что обеспечивает направленное изменение параметров в сторону снижения риска при сохранении или улучшении ожидаемой награды. \nabla_{\theta} J(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta}} [ \nabla_{\theta} \log \pi_{\theta}(\tau) Q(\tau) - \lambda \nabla_{\theta} R(\tau) ] , где λ — коэффициент, определяющий степень учета риска.
Взгляд в Будущее: Устойчивый Искусственный Интеллект и Расширение Области Применения
Предложенный метод обучения с подкреплением, основанный на градиентах политики с учетом риска, развивает уже существующие подходы к обучению с подкреплением. В отличие от стандартных методов, которые могут быть уязвимы в условиях неопределенности, данное решение позволяет агентам учитывать потенциальные риски при принятии решений. Это достигается путем модификации функции потерь, что способствует более стабильному и надежному обучению. Практическая эффективность метода подтверждается его способностью быстро сходиться к оптимальной политике даже в сложных и зашумленных средах, делая его привлекательным для широкого спектра задач, требующих принятия решений в условиях неопределенности.
Традиционные методы обучения с подкреплением зачастую демонстрируют уязвимость в условиях неопределенности, где случайные факторы и неполная информация могут существенно снизить эффективность и надежность агентов. Предлагаемый подход, направленный на преодоление этих ограничений, создает основу для разработки более устойчивых и адаптивных систем искусственного интеллекта. Вместо того чтобы стремиться к оптимальному решению в идеальных условиях, данная методология позволяет агентам осознанно оценивать риски и принимать взвешенные решения даже в сложных и непредсказуемых средах. Это открывает возможности для применения в широком спектре задач, где надежность и способность к адаптации являются критически важными, обеспечивая более предсказуемое и эффективное поведение в реальных условиях.
Дальнейшие исследования направлены на применение разработанного метода к более сложным задачам, возникающим в реальном мире. Особое внимание уделяется областям робототехники и финансовой торговли, где принятие решений в условиях неопределенности является критически важным. В робототехнике, алгоритм позволит создавать более надежных роботов, способных адаптироваться к изменяющейся обстановке и избегать рискованных ситуаций. В сфере финансов, метод может быть использован для разработки торговых стратегий, которые минимизируют потери и максимизируют прибыль, учитывая волатильность рынков и потенциальные риски. Планируется оценить эффективность алгоритма в симуляционных средах, а затем провести тестирование на реальных данных, чтобы подтвердить его практическую применимость и продемонстрировать преимущества по сравнению с существующими подходами.
Статья описывает попытку приручить непредсказуемость обучения с подкреплением, встроив в процесс оптимизации политик меры риска. Занятная затея, учитывая, что каждая «революционная» модель рано или поздно столкнется с реальностью, где данные шумные, а среда — враждебная. Впрочем, стремление к контролю над риском — это вечный танец. Как заметил Блез Паскаль: «Все великие дела требуют времени». В контексте обучения с подкреплением это особенно актуально: найти политику, которая не просто максимизирует награду, но и учитывает потенциальные потери, — задача, требующая терпения и, разумеется, множества сгоревших кластеров.
Что дальше?
Предложенный подход к обучению с подкреплением, учитывающий риски, несомненно, добавит ещё один уровень сложности в и без того перегруженную инструментальную среду. Заманчиво, конечно, говорить о «разумном» принятии решений, но всегда стоит помнить, что любые метрики риска — это лишь попытка формализовать неизбежную неопределённость. В конечном счёте, производственный процесс найдёт способ обойти даже самую элегантную математику, если это поможет быстрее «запустить и посмотреть, что получится».
Вполне вероятно, что основная проблема не в самих мерах риска, а в их интеграции с существующими алгоритмами оптимизации политики. Попытки «улучшить» градиентные методы — занятие, которое, как показывает история, обычно заканчивается появлением ещё большего количества гиперпараметров и, как следствие, новых способов сломать систему. Не исключено, что настоящая ценность подобных исследований заключается не в создании идеального алгоритма, а в более глубоком понимании того, какие риски действительно важны.
Всё новое — это просто старое с худшей документацией. Вполне вероятно, что через несколько лет, когда эта библиотека станет частью стандартного набора инструментов, кто-нибудь скажет: «Всё работало, пока не добавили чувствительность к риску». И это будет правдой. Впрочем, это неизбежно.
Оригинал статьи: https://arxiv.org/pdf/2602.09300.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Прогноз нефти
- Сегежа акции прогноз. Цена SGZH
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- МФК Займер акции прогноз. Цена ZAYM
- 🤯 Как ход Визы со стейблкоинами заставляет Уолл-стрит нервничать: BitPay раскрывает всё! 🤯
- Стоит ли покупать доллары за гонконгские доллары сейчас или подождать?
- Мосбиржа акции прогноз. Цена MOEX
2026-02-11 17:17