Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий значительно сократить время и ресурсы, необходимые для обучения роботов выполнению деликатных манипуляций в реальном мире.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Политика управления, первоначально обученная в масштабной симуляции и затем доработанная в реальном времени посредством SOFT-FLOW - с накоплением приблизительно 15 минут данных за каждые 1000 шагов градиентного спуска, после 3000 шагов разминки критика - демонстрирует временное снижение производительности на начальном этапе доработки актора, вызванное увеличением исследования, за которым следует значительное улучшение скорости вращения ([latex]RPM[/latex]) и кумулятивного вращения по траектории, что подтверждает эффективность онлайн-обучения с переносом знаний.](https://arxiv.org/html/2602.09580v1/images/cube_plot.png)
В статье представлен SOFT-FLOW — алгоритм, сочетающий в себе политики, основанные на нормализующих потоках, и критиков с разделением действий, для повышения эффективности обучения с небольшим количеством данных.
Несмотря на успехи в обучении с подкреплением, адаптация политик ловкого манипулирования в реальном мире остается сложной задачей из-за ограниченного бюджета взаимодействия и мультимодальных распределений действий. В работе ‘Sample-Efficient Real-World Dexterous Policy Fine-Tuning via Action-Chunked Critics and Normalizing Flows’ предложен фреймворк SOFT-FLOW, сочетающий политики на основе нормализующих потоков и критики, оценивающей последовательности действий, для повышения эффективности обучения. Этот подход позволяет выполнять консервативные обновления политики на основе точных оценок правдоподобия мультимодальных действий, улучшая долгосрочное назначение вознаграждений. Способен ли SOFT-FLOW открыть новые горизонты для создания надежных и эффективных систем ловкого манипулирования в реальных условиях?
Разрушая Реальность: Вызовы Обучения Роботов
Традиционные системы управления роботами часто основываются на жестко запрограммированных алгоритмах, что существенно ограничивает их способность адаптироваться к изменяющимся условиям окружающей среды. Такой подход, хотя и эффективен в предсказуемых сценариях, оказывается неэффективным в динамичных и непредсказуемых ситуациях, где требуется мгновенная реакция и гибкость. Роботы, действующие по заранее заданным инструкциям, испытывают трудности при столкновении с неожиданными препятствиями, изменением освещения или другими факторами, которые отличаются от условий, в которых была разработана программа. В результате, их производительность резко снижается, а в некоторых случаях требуется вмешательство человека для исправления ситуации. Это подчеркивает необходимость разработки более адаптивных систем управления, способных к самостоятельному обучению и принятию решений в реальном времени.
Освоение сложных манипулятивных навыков, таких как задача извлечения ножниц или вращение кубика в руке, требует от роботов не просто выполнения заученных действий, а активного изучения и адаптации. Эффективное исследование пространства возможных действий — ключевой фактор, позволяющий роботу быстро находить оптимальные решения. Однако, даже при наличии алгоритмов исследования, необходима надежная оптимизация политики — процесса выбора действий на основе полученного опыта. Алгоритмы оптимизации должны быть устойчивы к шумам и неточностям, неизбежно возникающим в реальном мире, чтобы робот мог стабильно выполнять поставленные задачи даже в меняющихся условиях. Успех в освоении подобных навыков напрямую зависит от сочетания эффективного исследования и надежной оптимизации, позволяющих роботу не только учиться, но и адаптироваться к сложным и непредсказуемым ситуациям.
Перенос обученных в симуляции политик управления роботами в реальный мир представляет собой серьезную проблему, обусловленную несоответствиями между виртуальной и физической средами. Эти расхождения охватывают различные аспекты, включая неточности в моделях физики, непредсказуемые шумы сенсоров и различия в динамике объектов. Даже небольшие отклонения могут привести к значительному ухудшению производительности робота в реальном мире, делая невозможным выполнение задач, успешно освоенных в симуляции. Разработка методов, позволяющих преодолеть этот “разрыв реальности”, требует создания более реалистичных симуляций, использования техник адаптации политик и применения робастных алгоритмов обучения, способных компенсировать неточности и неопределенности, характерные для реальных условий эксплуатации роботов.
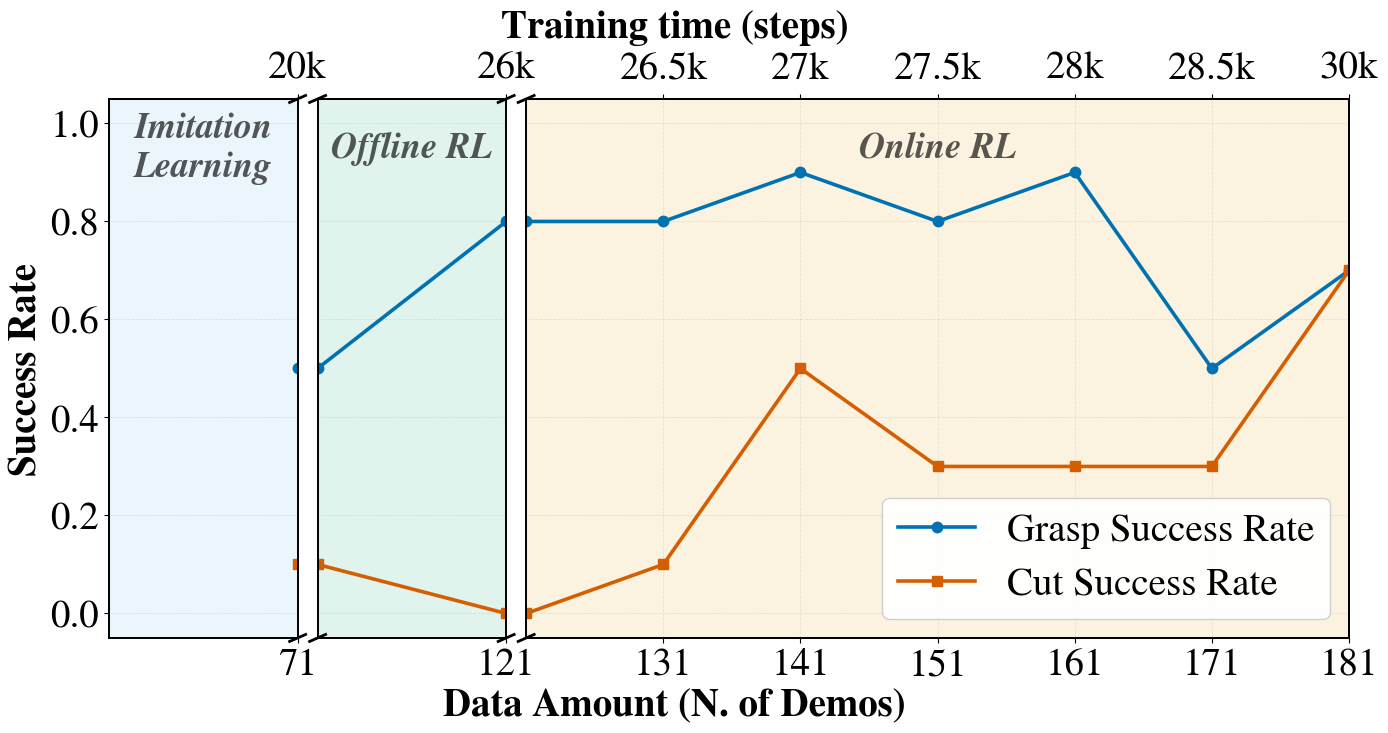
Управляя Хаосом: Обучение с Данными и Взаимодействием
Как обучение с подкреплением в автономном, так и интерактивном режимах представляют собой перспективные подходы к автоматизированному освоению навыков. Обучение с подкреплением в автономном режиме (Offline RL) позволяет использовать существующие наборы данных для обучения политик без необходимости дорогостоящего и потенциально опасного взаимодействия со средой. В свою очередь, интерактивное обучение с подкреплением (Online RL) предполагает непрерывное улучшение политик посредством взаимодействия со средой, требуя баланса между исследованием новых стратегий и использованием уже известных. Оба подхода направлены на создание агентов, способных самостоятельно обучаться и выполнять сложные задачи, однако используют различные стратегии сбора данных и оптимизации политик.
Обучение с подкреплением в автономном режиме (Offline Reinforcement Learning) использует существующие наборы данных, собранные ранее, для обучения политик без необходимости взаимодействия с реальной средой. Это позволяет избежать дорогостоящих и потенциально опасных этапов исследования (exploration), которые характерны для онлайн-обучения. Вместо этого, алгоритмы Offline RL анализируют статические данные, такие как логи действий, собранные человеком или другим агентом, и строят модель, позволяющую предсказывать оптимальные действия на основе этих данных. Такой подход особенно ценен в приложениях, где взаимодействие со средой ограничено или связано с высокими рисками, например, в робототехнике, здравоохранении или финансах.
Онлайн обучение с подкреплением (Online RL) предполагает непрерывное улучшение политики агента посредством взаимодействия с окружающей средой. Ключевым аспектом является баланс между исследованием (exploration) — поиском новых действий и состояний для расширения знаний агента — и эксплуатацией (exploitation) — использованием текущих знаний для максимизации немедленной награды. Недостаточный уровень исследования может привести к застреванию в локальных оптимумах, в то время как чрезмерное исследование снижает эффективность и замедляет процесс обучения. Различные алгоритмы, такие как \epsilon \$-greedy и алгоритмы на основе верхних доверительных границ (Upper Confidence Bound — UCB), используются для управления этим компромиссом и обеспечения оптимального баланса между сбором информации и максимизацией награды.
Обучение с подражанием (Imitation Learning) является расширением парадигм обучения с подкреплением, заключающимся в непосредственном обучении стратегии на основе демонстраций эксперта. В отличие от традиционного обучения с подкреплением, требующего процесса проб и ошибок для определения оптимальной политики, обучение с подражанием использует готовый набор данных, содержащий действия эксперта в различных состояниях. Это позволяет значительно ускорить начальную фазу обучения, поскольку агент сразу же получает информацию о желаемом поведении. Использование демонстраций эксперта особенно эффективно в сложных задачах, где случайный поиск оптимальной стратегии может быть непрактичным или опасным. Вместо максимизации вознаграждения, агент стремится воспроизвести действия, продемонстрированные экспертом, минимизируя расхождение между своим поведением и поведением эксперта.

Разгадывая Сложность: Выразительные Политики и Действия
Политика, основанная на нормализующих потоках (Normalizing Flow Policy), представляет собой мощный подход к представлению политик в обучении с подкреплением. В отличие от параметризации, ограничивающейся стандартными распределениями, нормализующие потоки позволяют моделировать произвольные распределения вероятностей над пространством действий. Это достигается посредством применения последовательности обратимых преобразований к простому базовому распределению, что обеспечивает гибкость в моделировании сложных зависимостей между состояниями и действиями. Такой подход позволяет выражать более сложные политики, чем традиционные методы, и обеспечивает теоретически обоснованную основу для представления неограниченных распределений действий, что особенно полезно в задачах с высокой размерностью пространства действий.
Представление политики, реализованное с использованием архитектуры Transformer, обеспечивает как выразительность, так и возможность отслеживания вероятностей действий. Transformer позволяет моделировать сложные зависимости между состояниями и действиями, что приводит к более точным вероятностным распределениям над действиями. Благодаря механизмам внимания, модель способна учитывать релевантные части входных данных, формируя более обоснованные прогнозы. Это особенно важно в задачах с непрерывными пространствами действий, где необходимо эффективно оценивать плотность вероятности для каждого возможного действия, что и достигается благодаря гибкости и выразительности Transformer.
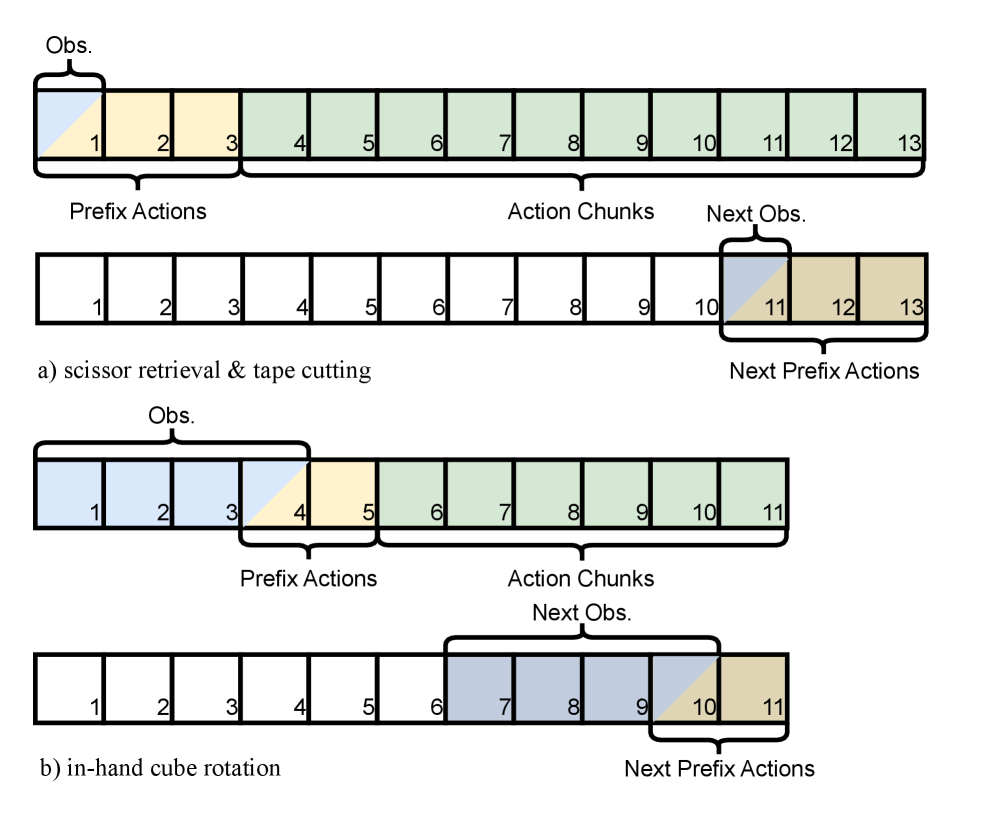
Для повышения эффективности обучения с подкреплением и улучшения отслеживания вклада отдельных действий, применяется метод «Action Chunking» (группировка действий). Суть метода заключается в объединении последовательных действий в единые блоки, что снижает частоту обновления политики. Вместо обновления политики после каждого отдельного действия, обновление производится после выполнения каждого блока действий. Это позволяет уменьшить дисперсию градиентов и более эффективно использовать имеющиеся данные, поскольку каждое обновление политики основывается на более длительной последовательности взаимодействий со средой. Данный подход особенно полезен в средах с разреженными наградами или при решении задач, требующих долгосрочного планирования.
Критик с группировкой действий (Action-Chunked Critic) оценивает не отдельные действия, а последовательности действий, объединенные во временные фрагменты (chunks). Это позволяет уменьшить дисперсию оценок, что приводит к более стабильному обучению агента. Оценка последовательностей действий, а не отдельных шагов, улучшает кредитное присвоение (credit assignment), поскольку позволяет критику учитывать долгосрочные последствия действий и более точно оценивать их вклад в общую награду. Такой подход особенно полезен в задачах, где награда отсрочена или разрежена, поскольку он облегчает распространение сигнала награды на более ранние действия в последовательности.

Отшлифовывая Интеллект: Дистилляция Знаний и Реальное Развертывание
В условиях выполнения сложных задач, характеризующихся редким вознаграждением, стандартные алгоритмы обучения часто сталкиваются с трудностями в оптимизации стратегии поведения. Отсутствие частых сигналов подкрепления затрудняет процесс определения эффективных действий, особенно в задачах, требующих последовательности действий для достижения цели. В таких сценариях, для успешного обучения необходимо применение надежных алгоритмов, способных эффективно исследовать пространство действий и извлекать полезную информацию из редких сигналов вознаграждения. Эти алгоритмы должны обладать способностью к обобщению и устойчивостью к шумам, чтобы эффективно направлять процесс оптимизации стратегии и обеспечивать стабильное обучение даже в условиях ограниченной обратной связи.
В условиях решения сложных задач, где вознаграждение за действия оказывается редким, применение метода дистилляции политики позволяет эффективно передавать знания от сложной, но высокопроизводительной политики к более простой и экономичной. Этот процесс предполагает, что сложная политика выступает в роли «учителя», а упрощенная — «ученика». Ученик обучается, имитируя поведение учителя, но при этом его архитектура оптимизирована для снижения вычислительных затрат и повышения скорости работы. В результате, дистилляция политики не только способствует улучшению обобщающей способности робота, но и открывает возможности для его развертывания на платформах с ограниченными ресурсами, обеспечивая эффективное решение задач в реальных условиях.
Перенос знаний от сложной, высокопроизводительной политики к более простой, эффективной, так называемая «дистилляция политики», не только повышает обобщающую способность робота, но и значительно упрощает его развертывание на платформах с ограниченными вычислительными ресурсами. Это особенно важно для робототехники, где часто требуется функционирование на бортовых компьютерах с ограниченной памятью и энергопотреблением. Уменьшение сложности модели позволяет снизить требования к аппаратному обеспечению, что делает возможным применение передовых алгоритмов управления роботами в более широком спектре реальных условий и задач, включая работу в условиях ограниченного доступа к электроэнергии или в компактных мобильных системах.
В результате представленных усовершенствований, роботы демонстрируют впечатляющую эффективность при решении сложных задач манипулирования. В частности, достигнута скорость вращения кубика в руке в 6.25 оборотов в минуту, что свидетельствует о точности и быстроте выполнения операции. Кроме того, зафиксирован 70-процентный показатель успешного выполнения задачи разрезания ножницами, подтверждающий надежность и устойчивость работы алгоритмов в реальных условиях. Данные результаты демонстрируют значительный прогресс в области робототехники и открывают новые возможности для применения роботов в различных сферах, требующих высокой степени ловкости и координации.
Исследование демонстрирует, что SOFT-FLOW, используя нормализующие потоки и дробление действий, стремится к повышению эффективности обучения с подкреплением в реальном мире. Это заставляет задуматься о природе ошибок и закономерностей. Как будто система не просто учится выполнять задачу, а пытается понять её внутреннюю структуру. В связи с этим вспоминается высказывание Дональда Кнута: «Оптимизм — это вера в то, что все будет хорошо; пессимизм — уверенность в том, что оптимисты ошибаются». Ведь оптимизация политики — это поиск баланса между верой в успех и осознанием возможных ошибок, а SOFT-FLOW как раз и предлагает способ более эффективно использовать данные и избегать преждевременных выводов, тем самым, приближаясь к оптимальному решению в сложных задачах манипулирования.
Куда Дальше?
Представленная работа, безусловно, продвигает границы эффективного обучения в реальном мире, но истинный взлом системы требует более глубокого понимания самой её архитектуры. Использование нормализующих потоков и “разбиения” действий — это лишь инструменты, позволяющие обойти некоторые ограничения текущих алгоритмов. Однако, фундаментальная проблема — это необходимость огромного количества данных для обучения, особенно в сложных задачах манипулирования. Следующим шагом представляется не просто увеличение эффективности сбора данных, а создание моделей, способных к истинному обобщению — к построению внутренней репрезентации мира, позволяющей предсказывать последствия действий, не требуя постоянной эмпирической проверки.
Очевидно, что текущий подход, основанный на “обучении на примерах”, рано или поздно столкнется с пределами. Настоящий прогресс, вероятно, потребует интеграции с моделями, способными к абстрактному мышлению и планированию, возможно, с использованием принципов, заимствованных из когнитивной науки или даже нейробиологии. Или, быть может, необходимо признать, что сама постановка задачи — “обучение робота” — является упрощением, и истинный интеллект требует совершенно иного подхода к взаимодействию с миром.
В конечном счете, SOFT-FLOW — это еще один шаг на пути к созданию искусственного интеллекта, способного к сложным манипуляциям. Но взлом реальности требует не только технических усовершенствований, но и философского переосмысления самой концепции “интеллекта” и его места в мире. И пока мы не поймем, как работает система изнутри, мы будем вынуждены довольствоваться лишь её поверхностными манипуляциями.
Оригинал статьи: https://arxiv.org/pdf/2602.09580.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Сегежа акции прогноз. Цена SGZH
- Bitcoin под давлением: RAIN взлетает на фоне геополитической неопределенности (27.05.2026 12:15)
- Опасный онлайн: Как нейросети распознают травлю в испаноязычном интернете
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Ростелеком акции прогноз. Цена RTKM
- Является ли депег sUSD концом для алгоритмических стейблкоинов? Получите полный обзор!
- МФК Займер акции прогноз. Цена ZAYM
- Прогноз нефти
2026-02-11 18:58