Автор: Денис Аветисян
Новый алгоритм позволяет значительно ускорить процесс адаптации мощных языковых моделей к конкретным задачам, не теряя в качестве.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал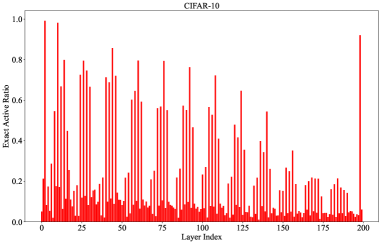
Предложенный метод SL-SAM динамически выбирает слои для вычисления градиентов, оптимизируя использование памяти и времени.
Несмотря на эффективность методов оптимизации, таких как Sharpness-aware minimization (SAM), их высокая вычислительная сложность ограничивает практическое применение, особенно при тонкой настройке больших моделей. В данной работе, посвященной ‘Sparse Layer Sharpness-Aware Minimization for Efficient Fine-Tuning’, предложен алгоритм SL-SAM, использующий разреженный выбор слоев для снижения вычислительных затрат без потери обобщающей способности. Ключевой инновацией является представление выбора слоев для градиентного подъема и спуска как задачи о многоруком бандите, что позволяет адаптивно выбирать наиболее важные слои для обновления параметров. Сможет ли SL-SAM стать эффективным инструментом для масштабирования методов оптимизации на еще более крупные модели и задачи машинного обучения?
Проблема Обобщения: Предвидение Неизбежных Сбоев
Одной из центральных проблем машинного обучения является способность модели успешно работать с данными, которые она не видела в процессе обучения — это и есть истинная обобщающая способность. Высокая производительность на обучающем наборе данных не гарантирует успешной работы в реальных условиях, где входные данные могут значительно отличаться от тех, на которых модель была обучена. Эта проблема возникает из-за того, что модели часто «запоминают» обучающие данные, а не извлекают из них общие закономерности, что приводит к переобучению и низкой производительности на новых, ранее не встречавшихся примерах. Поэтому, ключевой задачей исследователей является разработка методов, позволяющих моделям не просто хорошо работать на известных данных, а и успешно адаптироваться к новым, неизвестным ситуациям, демонстрируя подлинную обобщающую способность и устойчивость к изменениям во входных данных.
Традиционные методы оптимизации, применяемые при обучении глубоких нейронных сетей, зачастую приводят к нахождению острых минимумов в пространстве потерь. Это означает, что модель достигает хороших результатов на тренировочных данных, но её производительность резко снижается при обработке примеров, не встречавшихся ранее. Острые минимумы характеризуются высокой чувствительностью к малейшим изменениям входных данных, что делает модель уязвимой к шуму и отклонениям в реальных условиях. В результате, небольшие возмущения во входных данных могут приводить к значительным ошибкам в предсказаниях, что существенно ограничивает практическое применение таких моделей. Исследования показывают, что подобные острые минимумы часто связаны с переобучением и недостаточной способностью модели к обобщению полученных знаний на новые, неизвестные данные.
Ключевым фактором, обеспечивающим устойчивую обобщающую способность глубоких нейронных сетей, является поиск так называемых «плоских минимумов» в пространстве параметров. В отличие от «острых минимумов», которые приводят к решениям, крайне чувствительным к незначительным изменениям входных данных, плоские минимумы представляют собой области, где функция потерь меняется незначительно. Это означает, что небольшие возмущения во входных данных или параметрах модели не приведут к существенному ухудшению производительности на новых, ранее не встречавшихся примерах. Исследования показывают, что модели, обученные находить такие плоские минимумы, демонстрируют значительно лучшую устойчивость к шуму и повышенную способность к обобщению, что делает их более надежными в реальных условиях эксплуатации. Поиск и стабилизация этих плоских минимумов является активной областью исследований в машинном обучении, направленной на создание более робастных и эффективных моделей.
Поиск Робастных Решений: Sharpness-Aware Minimization
Метод Sharpness-Aware Minimization (SAM) направлен на повышение обобщающей способности моделей за счет поиска плоских минимумов в пространстве потерь. В отличие от традиционных методов оптимизации, стремящихся к простому снижению потерь, SAM ищет решения, которые менее чувствительны к небольшим изменениям входных данных. Это достигается за счет явного учета «резкости» минимума — то есть, насколько быстро растет функция потерь при отклонении от этого минимума. Плоские минимумы характеризуются низкой чувствительностью и, как следствие, обеспечивают более устойчивые и надежные прогнозы на новых, ранее не встречавшихся данных. Таким образом, SAM способствует созданию моделей, менее подверженных переобучению и более эффективных в реальных условиях эксплуатации.
Метод SAM (Sharpness-Aware Minimization) использует адверсарные возмущения для максимизации функции потерь в локальной окрестности текущей точки параметров. Этот процесс заключается в добавлении небольших, намеренно сконструированных изменений к входным данным, чтобы найти направление, в котором функция потерь наиболее быстро возрастает. Идентифицируя такие регионы с высокой чувствительностью, SAM позволяет модели избегать узких, острых минимумов в пространстве параметров, которые склонны к переобучению. Фактически, максимизация потерь в локальной окрестности позволяет оценить устойчивость решения к небольшим изменениям входных данных, что способствует поиску решений с более низкой чувствительностью к вариациям и, следовательно, лучшей обобщающей способностью.
Процесс, состоящий из двух шагов — возмущения и обновления — направлен на то, чтобы модель сходилась к решениям, демонстрирующим лучшую обобщающую способность на новых данных. На этапе возмущения, к входным данным вносится небольшое, но намеренное отклонение, максимизирующее функцию потерь в локальной окрестности. После этого, выполняется обновление параметров модели, направленное на минимизацию потерь уже для возмущенных данных. Повторение этих двух шагов заставляет модель искать решения, менее чувствительные к небольшим изменениям во входных данных, что, в свою очередь, улучшает ее способность к обобщению и повышает устойчивость к шуму и вариациям в данных, не представленных в обучающей выборке.
Эффективность и Разреженность: SL-SAM
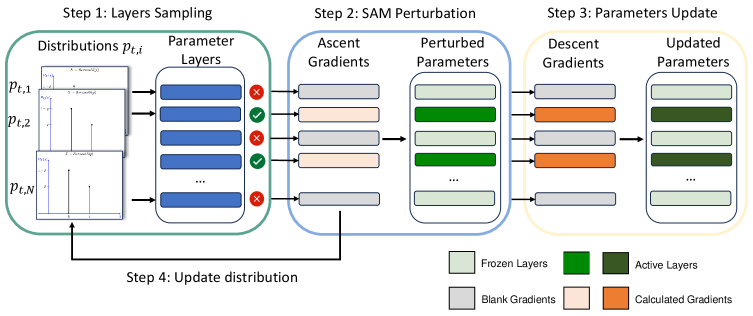
Метод Sparse Layer SAM (SL-SAM) направлен на снижение вычислительной сложности алгоритма SAM за счет внедрения адаптивной разреженности на уровне слоев при обновлении параметров. Вместо одновременного обновления всех параметров, SL-SAM выборочно активирует лишь подмножество слоев на каждой итерации, что позволяет сократить объем необходимых вычислений и снизить потребление памяти. Данный подход основан на принципе разреженности слоев, позволяющем оптимизировать процесс обучения, уделяя внимание наиболее значимым слоям и игнорируя менее важные на текущем этапе. Активация производится динамически, в зависимости от вклада каждого слоя в процесс оптимизации.
Метод SL-SAM (Sparse Layer SAM) снижает вычислительные затраты за счет выборочной активации подмножества слоев на каждой итерации обучения, используя принципы разреженности слоев. В ходе экспериментов было установлено, что SL-SAM активирует в среднем 47% параметров по сравнению с AdaSAM, что позволяет существенно сократить объем вычислений и требования к памяти. Данный подход основан на динамическом определении наиболее важных слоев для оптимизации, что позволяет избежать ненужных операций над менее значимыми параметрами и повысить эффективность обучения.
Механизм SL-SAM использует подход Multi-Armed Bandit (MAB) для динамического определения вклада каждого слоя в процесс оптимизации. Основываясь на нормах градиентов, MAB определяет, какие слои наиболее существенно влияют на снижение функции потерь и, следовательно, активирует только их на каждой итерации. В ходе экспериментов на популярном наборе данных MNLI было продемонстрировано, что данная стратегия позволяет снизить потребление памяти GPU до 19.99% и сократить время обучения до 25.75% по сравнению с традиционными методами, благодаря выборочной активации слоев и уменьшению количества вычислений.
Оптимизация SAM: Одношаговое Возмущение
Для дальнейшего снижения вычислительных затрат была разработана версия SAM, известная как S2-SAM. В отличие от классического SAM, S2-SAM использует градиенты, вычисленные на предыдущей итерации, для осуществления шага возмущения. Этот подход позволяет избежать повторного вычисления градиентов на каждом шаге, что значительно повышает эффективность алгоритма. Вместо этого, информация о градиенте, полученная ранее, используется для направления поиска оптимального решения, что особенно важно при работе с большими моделями и объемными наборами данных, где вычислительные ресурсы ограничены.
Упрощение, заключающееся в отказе от повторного вычисления градиентов на этапе возмущения, значительно повышает вычислительную эффективность алгоритма SAM. Традиционный SAM требует двойного прохода для каждого шага оптимизации: сначала вычисляются градиенты для определения направления наискорейшего спуска, а затем — повторно, для оценки чувствительности функции потерь к небольшим возмущениям параметров. В данном подходе, вместо этого, используется информация о градиентах, полученная на предыдущей итерации, что позволяет избежать дорогостоящего повторного вычисления. Такое нововведение существенно снижает вычислительную нагрузку, делая алгоритм более применимым для задач, связанных с большими моделями и объемами данных, где стоимость вычисления градиентов может стать узким местом.
Уменьшение вычислительных затрат, связанных с расчетом градиентов, является ключевым преимуществом S2-SAM, что делает его значительно более применимым для работы с масштабными моделями и обширными наборами данных. Традиционный SAM требует повторного вычисления градиентов на каждом шаге пертурбации, что создает существенную нагрузку на вычислительные ресурсы. S2-SAM, напротив, использует градиенты, полученные на предыдущей итерации, избегая необходимости в повторных расчетах. Это упрощение позволяет значительно ускорить процесс обучения, особенно при работе с задачами, требующими обработки огромных объемов информации, и открывает возможности для применения SAM в сценариях, где ранее его использование было затруднено из-за вычислительной сложности. Таким образом, S2-SAM представляет собой важный шаг на пути к повышению практичности и эффективности алгоритма SAM для задач машинного обучения в реальном мире.
Практические Последствия: Снижение Стоимости и Масштабируемость
Сочетание методов SL-SAM и S2-SAM обеспечивает значительное снижение вычислительных затрат и объема потребляемой памяти. Это позволяет обучать модели существенно большего размера, чем ранее возможно. Уменьшение времени обучения и требований к памяти открывает новые перспективы для применения SAM-оптимизации в условиях ограниченных ресурсов, например, на устройствах с низкой вычислительной мощностью или при работе с огромными наборами данных. Благодаря этим улучшениям, обучение сложных моделей становится более доступным и эффективным, расширяя возможности исследователей и разработчиков в области машинного обучения.
Повышенная эффективность, достигнутая благодаря оптимизации на основе SAM, значительно расширяет возможности её применения в условиях ограниченных ресурсов. Ранее сложные в реализации и требующие значительных вычислительных мощностей, методы, подобные SAM, становятся доступными для устройств с меньшей производительностью и ограниченным объемом памяти. Это открывает перспективы для внедрения передовых алгоритмов машинного обучения в мобильные устройства, встроенные системы и другие платформы, где вычислительные ресурсы ограничены. Таким образом, оптимизация не только улучшает производительность существующих моделей, но и способствует демократизации доступа к современным технологиям машинного обучения, позволяя использовать их в более широком спектре приложений и сценариев.
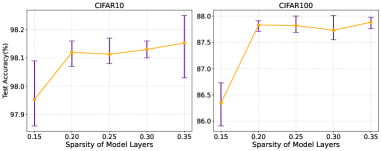
Результаты экспериментов демонстрируют высокую эффективность предложенного метода SL-SAM. На популярном наборе данных CIFAR-10, SL-SAM достигает точности в 97.93%, что сопоставимо с результатами, полученными при использовании полномасштабного алгоритма SAM. Аналогичная картина наблюдается и на более сложном наборе данных CIFAR-100, где SL-SAM показывает точность в 86.19%, не уступая по качеству классификации оригинальному SAM. Полученные данные подтверждают, что предложенная оптимизация позволяет достичь сравнимой точности при значительно меньших вычислительных затратах, открывая возможности для применения SAM-подобных методов в задачах, ранее ограниченных ресурсами.
Предложенный подход к оптимизации, SL-SAM, напоминает скорее искусство садоводства, чем точную инженерию. Авторы не стремятся построить идеальную систему, а взращивают её, адаптируя процесс обучения к особенностям каждой модели. Выбор слоев для расчета градиента, подобно выбору лучших саженцев для прививки, позволяет добиться максимальной эффективности при минимальных затратах ресурсов. Как однажды заметил Карл Фридрих Гаусс: «Математика — это наука о бесконечном, а её изучение — это путешествие без конца». Так и здесь, SL-SAM — это не статичное решение, а отправная точка для дальнейших исследований в области оптимизации больших языковых моделей, позволяющая приблизиться к более эффективному и устойчивому обучению.
Что дальше?
Предложенный подход, оптимизирующий процесс поиска минимумов с учетом «резкости» ландшафта, напоминает о вечной борьбе архитектора с энтропией. Каждое сужение области вычислений, каждое адаптивное выделение слоев — это пророчество о будущем сбое, лишь отодвигающее момент неизбежного столкновения с непредсказуемостью больших языковых моделей. Иллюзия эффективности — лишь временное облегчение, подобно молитве перед бурей.
Однако, истинный вопрос заключается не в скорости сходимости, а в самой природе оптимизации. Поиск «плоского» минимума — это лишь попытка усмирить хаос, а не понять его. Следующим шагом видится не столько совершенствование алгоритмов, сколько переосмысление самой цели — возможно, пора искать не «лучшее» решение, а наиболее устойчивое к возмущениям, подобно кораблю, строящемуся для вечной штормовой погоды.
Ограничение выборки слоев, предложенное в данной работе, открывает путь к дальнейшим исследованиям в области «разреженного» градиента. Но следует помнить: каждая оптимизация — это лишь временный компромисс. Система взрослеет, и вместе с ней растет сложность ее непредсказуемых проявлений. Истинная мудрость заключается не в управлении этой сложностью, а в ее принятии.
Оригинал статьи: https://arxiv.org/pdf/2602.09395.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Прогноз нефти
- Сегежа акции прогноз. Цена SGZH
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- МФК Займер акции прогноз. Цена ZAYM
- 🤯 Как ход Визы со стейблкоинами заставляет Уолл-стрит нервничать: BitPay раскрывает всё! 🤯
- Стоит ли покупать доллары за гонконгские доллары сейчас или подождать?
- Мосбиржа акции прогноз. Цена MOEX
2026-02-11 23:57