Автор: Денис Аветисян
Исследование предлагает инновационный метод учета не только величины риска, но и времени получения вознаграждения в задачах обучения с подкреплением, что позволяет создавать более эффективные стратегии для финансовых приложений.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
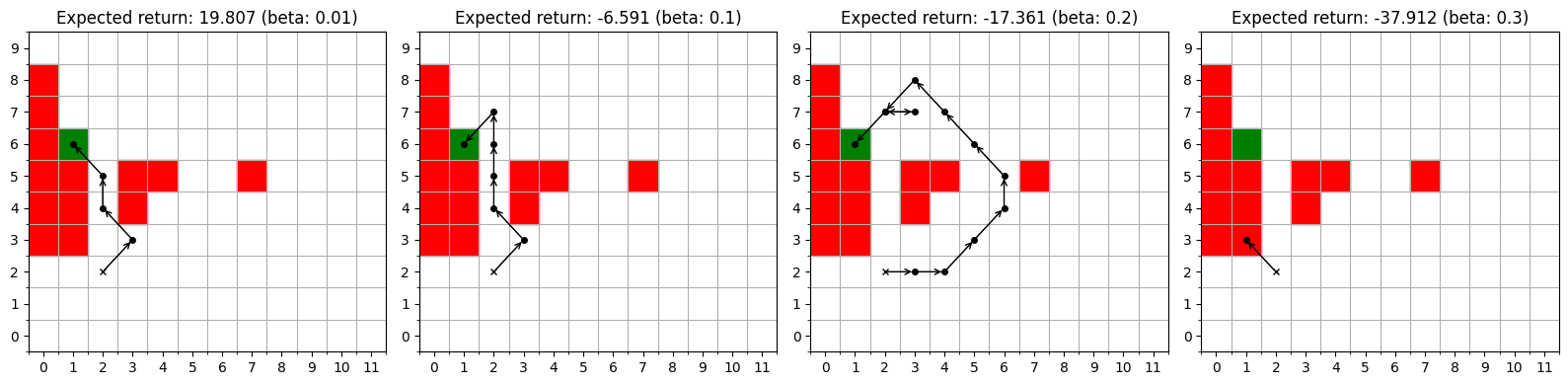
Бесплатный Телеграм канал![Оптимальные стратегии управления, протестированные в среде без шумов при неоднородной волатильности [latex]2.3[/latex], демонстрируют, что величина неприятия риска β напрямую влияет на траекторию движения, определяя баланс между скоростью и стабильностью.](https://arxiv.org/html/2602.12030v1/meanvar.png)
Предложена функция нелинейной неприятия риска, учитывающая временную неоднородность волатильности и применимая к задачам оптимального исполнения и последовательному принятию решений.
В задачах последовательного принятия решений в финансах, несмотря на перспективность обучения с подкреплением, стандартные подходы оптимизируют лишь ожидаемую кумулятивную награду, игнорируя важный компромисс между доходностью и риском. В данной работе, посвященной проблеме ‘Time-Inhomogeneous Volatility Aversion for Financial Applications of Reinforcement Learning’, предложен новый риск-чувствительный критерий — неоднородная неприятие волатильности, учитывающий не только неопределенность отдельных наград, но и временное распределение общей доходности. Этот подход позволяет более гибко настраивать целевые уровни доходности и оптимизировать стратегии, что демонстрируется на примерах оптимального исполнения ордеров и задач на сетке. Способствует ли предложенный подход созданию более робастных и эффективных алгоритмов управления финансами в условиях меняющейся рыночной конъюнктуры?
Последовательное принятие решений и ограничения традиционных подходов
Многие задачи, с которыми сталкиваются современные системы искусственного интеллекта, требуют принятия последовательных решений в условиях неопределенности. От управления робототехникой и автономным транспортом до финансовых стратегий и персонализированной медицины, эти проблемы характеризуются необходимостью выбора действий, последствия которых не всегда предсказуемы и проявляются лишь со временем. Именно в таких сценариях обучение с подкреплением RL демонстрирует свою эффективность, поскольку позволяет агенту обучаться оптимальной стратегии поведения путем взаимодействия с окружающей средой и получения обратной связи в виде вознаграждения или штрафа. В отличие от традиционных методов, RL не требует явного программирования правил принятия решений, а позволяет агенту самостоятельно выявлять оптимальные стратегии на основе опыта, что делает его особенно привлекательным для решения сложных и динамичных задач.
Традиционные методы обучения с подкреплением часто основываются на предположении о стационарности окружающей среды и неизменности предпочтений агента в отношении риска. Однако, в реальных задачах, условия постоянно меняются, а отношение к риску может варьироваться со временем. Например, в финансовой торговле волатильность рынка и терпимость к убыткам инвестора подвержены колебаниям. Аналогично, в робототехнике, износ оборудования или изменение условий окружающей среды могут существенно повлиять на оптимальную стратегию. Эти ограничения делают стандартные алгоритмы неэффективными в динамичных сценариях, подчеркивая необходимость разработки более адаптивных подходов, способных учитывать эволюцию условий и предпочтений агента для достижения оптимальных результатов.
Ограничения традиционных методов обучения с подкреплением стимулируют разработку более сложных подходов, способных учитывать изменчивость окружающей среды и динамику предпочтений агента. В реальных задачах условия постоянно меняются, а отношение к риску может эволюционировать со временем — стандартные алгоритмы, предполагающие стационарность, оказываются неэффективными в таких сценариях. Поэтому все больше внимания уделяется разработке систем, способных адаптироваться к новым обстоятельствам, переоценивать важность различных исходов и корректировать стратегию действий в соответствии с меняющимися приоритетами. Это требует внедрения механизмов, позволяющих учитывать историю взаимодействий, прогнозировать будущие изменения и формировать гибкую политику, обеспечивающую оптимальное поведение агента в условиях неопределенности и изменчивости.
Для эффективного решения сложных задач последовательного принятия решений требуется разработка алгоритмов, способных адаптироваться к изменяющемуся уровню риска. Традиционные методы обучения с подкреплением часто предполагают стационарность среды и постоянство предпочтений агента, что является существенным ограничением в динамичных сценариях. Неспособность учитывать временные изменения в отношении к риску приводит к неоптимальным решениям и снижает эффективность алгоритмов в реальных условиях. Поэтому, алгоритмы, динамически корректирующие свою стратегию в зависимости от текущего уровня риска и вероятности неблагоприятных исходов, представляют собой важный шаг вперёд в развитии обучения с подкреплением и открывают новые возможности для решения сложных задач в различных областях, от финансов до робототехники.
Расширение оптимизации «Средняя доходность — Волатильность» для динамичных сред
Оптимизация «Средняя доходность — Волатильность» представляет собой методологию принятия решений в условиях неопределенности, ориентированную на снижение риска. В её основе лежит баланс между ожидаемой доходностью (E[R]) и дисперсией (волатильностью) доходности (\sigma^2). Данный подход позволяет инвесторам или агентам формировать портфели или стратегии, максимизирующие доходность при заданном уровне риска, или минимизирующие риск при заданном уровне доходности. Ключевым элементом является учет отклонения фактической доходности от ожидаемой, при этом волатильность выступает в качестве меры этого отклонения и, следовательно, индикатора риска. В рамках этой методологии, риск не рассматривается как абсолютная величина, а как функция от дисперсии, позволяющая количественно оценить и управлять им в процессе принятия решений.
Неоднородная оптимизация среднего и волатильности (Mean-Volatility) расширяет стандартный подход, учитывая изменения в предпочтениях к риску и распределении вознаграждений во времени. В отличие от методов, предполагающих равномерное распределение вознаграждений, данный подход позволяет моделировать ситуации, когда ценность вознаграждения меняется в зависимости от времени его получения. Это достигается за счет учета индивидуального коэффициента дисконтирования γ, который определяет, насколько сильно будущие вознаграждения обесцениваются по сравнению с текущими. Таким образом, неоднородная оптимизация среднего и волатильности обеспечивает более гибкий и реалистичный инструмент для принятия решений в динамически меняющихся условиях, особенно в сценариях с неравномерным распределением вознаграждений во времени.
Расширение оптимизации «среднее-волатильность» для динамических сред использует понятия коэффициента дисконтирования и ожидаемой доходности для точной оценки будущих вознаграждений в условиях неопределенности. Коэффициент дисконтирования δ отражает степень предпочтения немедленного вознаграждения перед будущим, уменьшая ценность будущих вознаграждений в зависимости от временного горизонта. Ожидаемая доходность E[R] представляет собой среднее значение будущих вознаграждений, взвешенное по вероятностям их получения. Комбинирование этих концепций позволяет агентам учитывать как величину, так и время получения вознаграждений, что особенно важно в средах с меняющимися условиями и риском. Моделирование неопределенности посредством вероятностных распределений и учет временной стоимости вознаграждений повышают точность оценки и способствуют принятию оптимальных решений.
Моделирование изменяющегося во времени риска позволяет агентам адаптировать свое поведение к меняющимся условиям, представляя собой альтернативу существующим финансовым моделям. Традиционные подходы часто предполагают постоянный уровень риска или используют усредненные значения, что не учитывает динамику рынков и индивидуальные предпочтения. Данный подход, напротив, позволяет явно учитывать изменения в волатильности и ожидаемой доходности, что дает возможность агентам корректировать свои стратегии в реальном времени. Это особенно важно в условиях нестабильности, когда оценка риска и доходности требует учета текущей ситуации и прогнозов на будущее. Адаптация поведения включает в себя изменение состава портфеля, корректировку размеров позиций и выбор альтернативных инвестиционных стратегий, направленных на оптимизацию соотношения риска и доходности в изменяющейся среде.
[/latex], формируют траектории, зависящие от значения параметра β.](https://arxiv.org/html/2602.12030v1/exponential.png)
Применение в оптимальном исполнении и за его пределами
Оптимальное исполнение ордеров направлено на минимизацию влияния торговых операций на цену актива, что требует детального анализа рыночной динамики. В процессе исполнения крупных ордеров, особенно на неликвидных рынках, непосредственное воздействие на цену может привести к неблагоприятным последствиям для трейдера. Поэтому, стратегии оптимального исполнения учитывают такие факторы, как объем торгов, волатильность, глубина рынка и поведение других участников, стремясь разделить крупный ордер на более мелкие части и исполнить их в оптимальные моменты времени, чтобы снизить влияние на цену и обеспечить наилучшее возможное исполнение. Эффективное управление этими факторами критически важно для достижения целей по минимизации транзакционных издержек и максимизации прибыли.
Подход неоднородной средней волатильности (Inhomogeneous Mean-Volatility) позволяет напрямую моделировать оптимальное исполнение сделок, учитывая динамично меняющиеся рыночные условия и предпочтения инвестора в отношении риска. В рамках данной модели, волатильность и среднее значение цены не рассматриваются как постоянные величины, а изменяются во времени, отражая текущую ситуацию на рынке. Это позволяет учитывать влияние крупных ордеров на цену актива и оптимизировать стратегию исполнения для минимизации проскальзывания и снижения транзакционных издержек. Применение данного подхода требует оценки текущей и прогнозируемой волатильности, а также учета индивидуальных параметров риска инвестора, таких как неприятие риска и горизонт инвестирования.
В рамках подхода, учитывающего неоднородное среднее и волатильность, оценка затрат на торговлю требует учета таких факторов, как денежный поток (Cash Flow) и постоянное влияние (Permanent Impact). Денежный поток отражает скорость исполнения ордера и связанные с этим издержки, включая комиссионные и спред. Постоянное влияние, в свою очередь, представляет собой необратимое изменение цены актива, вызванное самим ордером. Игнорирование этих факторов приводит к неточной оценке фактических затрат, поскольку стандартные модели часто предполагают мгновенное исполнение и отсутствие влияния на цену. Учет Cash Flow и Permanent Impact позволяет более реалистично моделировать затраты на торговлю и оптимизировать стратегии исполнения ордеров.
Предлагаемая методология демонстрирует значительные улучшения по сравнению со статическими подходами в области оптимального исполнения сделок. В отличие от традиционных моделей, предполагающих постоянные параметры рынка, данный подход позволяет учитывать динамически меняющиеся условия и предпочтения к риску, что приводит к повышению эффективности торговых стратегий. Результаты моделирования показывают снижение транзакционных издержек и улучшение показателей исполнения по сравнению с традиционными алгоритмами. Это подтверждает ее жизнеспособность как альтернативы существующим финансовым моделям и открывает возможности для разработки более устойчивых и адаптивных стратегий торговли на финансовых рынках.
Моделирование экологической стохастичности и адаптивности агента
Во многих реальных условиях функционирования агентов, таких как робототехника или экономическое моделирование, длительность эпизода или задачи не является фиксированной и предопределённой. Напротив, горизонт принятия решений носит стохастический характер, то есть определяется случайным образом. Это означает, что агент не может заранее знать, когда задача будет завершена, что требует разработки стратегий, способных адаптироваться к неопределённости во времени. Такая непредсказуемость может быть вызвана различными факторами, например, внешними событиями, изменениями в окружающей среде или даже внутренними ограничениями системы. Исследование стохастических горизонтов позволяет глубже понять, как агенты могут эффективно действовать в динамичных и непредсказуемых условиях, и разрабатывать более устойчивые и гибкие алгоритмы принятия решений.
Сочетание модели негомогенной средней волатильности с игровыми средами, такими как Grid Worlds, предоставляет уникальную возможность для тестирования и валидации устойчивых стратегий принятия решений. В традиционных моделях часто предполагается постоянная неопределенность, однако, в реальности, вариативность вознаграждений может меняться со временем. Используя Grid Worlds как контролируемую среду, исследователи могут детально изучать, как агенты адаптируются к изменяющейся волатильности и разрабатывают стратегии, максимизирующие долгосрочное вознаграждение в условиях непредсказуемости. Такой подход позволяет выявлять оптимальные алгоритмы, способные эффективно функционировать даже в сложных и динамичных условиях, представляющих интерес для различных областей, от робототехники до финансовых рынков.
Учет изменчивости вознаграждения и ее неоднородных вариаций позволяет агентам значительно улучшить способность предвидеть и реагировать на неопределенность окружающей среды. Исследования показывают, что стабильное вознаграждение не всегда является оптимальным решением, особенно в динамичных условиях. Неоднородность вознаграждения, когда его колебания меняются во времени, требует от агентов более сложной стратегии обучения, позволяющей адаптироваться к изменяющимся обстоятельствам. Способность прогнозировать не только среднее значение вознаграждения, но и его дисперсию, позволяет агентам принимать более взвешенные решения, избегая рискованных ситуаций в периоды высокой изменчивости и, напротив, используя возможности в периоды стабильности. Такой подход, имитирующий реальные условия, где предсказуемость ограничена, открывает новые перспективы в разработке интеллектуальных систем, способных эффективно функционировать в условиях неопределенности.
Разработанная платформа представляет собой мощный инструмент для изучения и оптимизации последовательного принятия решений в сложных и динамичных средах. Исследования, проведенные с ее использованием, выявили неожиданные стратегии поведения агентов, которые противоречат интуитивным ожиданиям. Например, в некоторых сценариях агенты демонстрируют склонность к отсрочке вознаграждения даже при высокой степени неопределенности, или же предпочитают более рискованные, но потенциально более прибыльные действия в ситуациях, когда традиционные алгоритмы выбора были бы более консервативными. Эти контринтуитивные политики требуют дальнейшего анализа и углубленного изучения, поскольку могут указывать на принципиально новые подходы к решению задач в условиях изменяющейся среды и неполной информации. Предлагаемый подход открывает перспективы для создания более адаптивных и эффективных систем искусственного интеллекта, способных успешно функционировать в реальном мире.
Представленное исследование демонстрирует, что при моделировании финансовых процессов, особенно в контексте обучения с подкреплением, учет временной неоднородности волатильности является критически важным. Авторы предлагают новый подход к оценке рисков, позволяющий более точно отражать динамику рынка и оптимизировать стратегии исполнения ордеров. Как заметил Томас Гоббс, “Основа всех желаний — надежда, но надежда — это лишь начало”. В данном случае, надежда на оптимальное исполнение ордеров должна подкрепляться строгим математическим аппаратом и учетом временных факторов, что и реализовано в предложенной функции потерь. Игнорирование этих аспектов, как показывает исследование, может привести к существенным отклонениям от оптимальных результатов, превращая даже самую перспективную стратегию в иллюзию.
Куда же дальше?
Предложенный подход к учету нежелания риска, связанного с моментом получения вознаграждения, безусловно, добавляет еще один слой сложности в и без того непростые алгоритмы обучения с подкреплением. Однако, стоит признать, что эта сложность не всегда оправдана. Зачастую, она лишь маскирует недостаток данных, позволяя создавать иллюзию понимания процессов, когда на самом деле наблюдается лишь подгонка под шум. Попытки обобщить предложенную функцию для более широкого круга задач, вероятно, столкнутся с необходимостью точного определения временного горизонта, что само по себе является искусственной конструкцией.
Наиболее интересным направлением представляется не столько усложнение модели, сколько разработка методов, позволяющих оценивать адекватность самой постановки задачи. Возможно ли вообще построить модель, учитывающую все нюансы человеческого неприятия риска? Или же мы просто ищем математическое подтверждение собственным предубеждениям? Следует помнить, что оптимизация — это не поиск истины, а лишь нахождение наилучшего компромисса между желаемым и достижимым, учитывая ограниченность ресурсов и точность измерительных инструментов.
Вероятно, будущее за гибридными подходами, сочетающими преимущества параметрических моделей с возможностями обучения без учителя. Поиск закономерностей в данных, не навязывая им заранее заданную структуру, может оказаться более продуктивным, чем бесконечная гонка за более точными, но все равно упрощенными моделями. И, конечно, не стоит забывать о необходимости тщательной верификации результатов на реальных данных, прежде чем делать какие-либо окончательные выводы.
Оригинал статьи: https://arxiv.org/pdf/2602.12030.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Сегежа акции прогноз. Цена SGZH
- Bitcoin под давлением: RAIN взлетает на фоне геополитической неопределенности (27.05.2026 12:15)
- Опасный онлайн: Как нейросети распознают травлю в испаноязычном интернете
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Ростелеком акции прогноз. Цена RTKM
- Является ли депег sUSD концом для алгоритмических стейблкоинов? Получите полный обзор!
- МФК Займер акции прогноз. Цена ZAYM
- Прогноз нефти
2026-02-13 09:38