Автор: Денис Аветисян
Новый подход к обучению больших языковых моделей позволяет динамически балансировать между исследованием и использованием знаний, повышая их эффективность и обобщающую способность.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
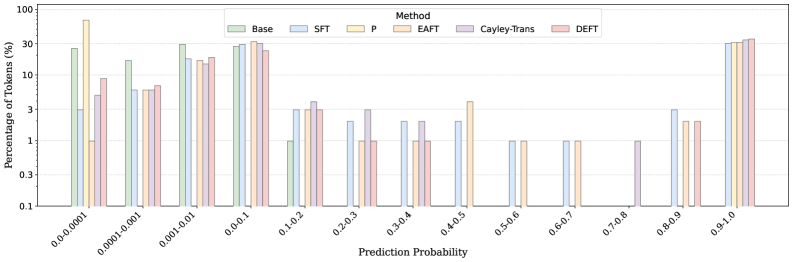
Бесплатный Телеграм канал![Распределение градиентов на уровне токенов демонстрирует, как различные функции потерь влияют на обучение, причем для моделей с высокой производительностью градиенты концентрируются в области высокой вероятности и низкой энтропии [latex] p(x), H(x) [/latex], в то время как модели с низкой производительностью демонстрируют более рассеянное распределение, указывающее на менее эффективное использование информации о потерях.](https://arxiv.org/html/2602.11424v1/x4.png)
В статье представлена методика Dynamic Entropy Fine-Tuning (DEFT), позволяющая адаптивно распределять градиенты на основе уверенности модели и энтропии, что приводит к улучшению результатов в различных задачах.
Стандартные методы контролируемой тонкой настройки больших языковых моделей (SFT) часто страдают от дисбаланса между использованием новых данных и сохранением уже приобретенных знаний. В статье ‘Gradients Must Earn Their Influence: Unifying SFT with Generalized Entropic Objectives’ предложен новый подход, основанный на обобщенных энтропийных целях, позволяющий динамически регулировать вклад градиентов в процесс обучения. Разработанный метод Dynamic Entropy Fine-Tuning (DEFT) модулирует «доверие» модели к своим предсказаниям, используя концентрацию распределения как прокси для оценки ее уверенности. Позволит ли такой подход создать более надежные и эффективные языковые модели, способные к обобщению и адаптации в различных сценариях?
Пределы Стандартной Тонкой Настройки
Обучение больших языковых моделей посредством контролируемой тонкой настройки (SFT) демонстрирует значительную эффективность, однако часто опирается на предсказание следующего токена. Этот подход, хотя и позволяет модели генерировать связный текст, не учитывает напрямую качество обучающих данных. В результате, даже при использовании обширных датасетов, модель может усваивать и воспроизводить ошибки, содержащиеся в данных, или придавать одинаковое значение как полезной, так и нерелевантной информации. Это особенно важно, поскольку стандартные методы обучения не предусматривают механизмов для оценки или фильтрации данных, что может приводить к ухудшению производительности и снижению надежности генерируемого контента. Таким образом, несмотря на свою мощь, SFT требует дополнительного внимания к качеству данных для достижения оптимальных результатов.
Стандартные целевые функции, такие как отрицательное логарифмическое правдоподобие, при обучении больших языковых моделей исходят из предположения об одинаковой важности каждого токена в обучающей выборке. Однако, это упрощение игнорирует тот факт, что некоторые токены несут в себе значительно больше информации для процесса обучения, чем другие. Например, редкие или информативные слова, а также токены, определяющие ключевые смысловые связи, оказывают большее влияние на формирование знаний модели. Рассматривая все токены как равнозначные, алгоритм обучения может упустить возможность более эффективно усвоить наиболее ценные данные, что приводит к менее оптимальной модели и снижению ее способности к обобщению.
В процессе тонкой настройки больших языковых моделей (LLM) с использованием контролируемого обучения нередко возникают так называемые «уверенные конфликты». Модель, обученная предсказывать следующий токен, может с высокой степенью уверенности генерировать неверную информацию, особенно если обучающие данные содержат ошибки или неточности. Это происходит из-за того, что стандартные методы обучения не учитывают важность отдельных токенов и могут усиливать ошибочные паттерны. Подобные ситуации могут приводить к «катастрофическому забыванию» — потере ранее приобретенных знаний в процессе обучения новым данным, что существенно снижает общую эффективность и надежность модели. Таким образом, высокая уверенность в неверных предсказаниях представляет серьезную проблему, требующую разработки более совершенных методов обучения, учитывающих качество данных и предотвращающих потерю ценной информации.
![Анализ изменений вероятности ([latex] riangle P[/latex]) и потерь ([latex] riangle L[/latex]) токенов в процессе обучения показал, что политика динамически осваивает и забывает токены, причем уверенность в забытых и усвоенных токенах существенно различается, о чем свидетельствуют пропорции токенов с высокой и низкой уверенностью.](https://arxiv.org/html/2602.11424v1/x1.png)
Оценка Значимости Токенов: Деформированные Логарифмические Целевые Функции
Семейство целевых функций SFT, основанное на деформированных логарифмах, предлагает решение проблемы неравномерного распределения обучающего сигнала. Традиционные методы обучения часто присваивают одинаковый вес всем токенам последовательности, что не учитывает их различную информативность. В отличие от этого, деформированные логарифмы позволяют явно контролировать распределение обучающего сигнала, концентрируясь на наиболее ценных токенах и снижая влияние менее значимых. Это достигается путем использования параметризованной функции, которая определяет вес каждого токена в зависимости от его вклада в целевую функцию, что позволяет более эффективно использовать доступные данные и ускорить процесс обучения. log_q(x) = \frac{log(x)}{1 + (q-1)log(x)} — базовая формула семейства, где параметр q определяет степень деформации логарифма.
Семейство целевых функций Deformed-Log использует q-логарифм Цаллиса для обеспечения гибкого контроля над процессом обучения. В отличие от равномерного взвешивания токенов, данный подход позволяет концентрироваться на наиболее ценных токенах, регулируя параметр q. При q = 1 достигается стандартный логарифм, однако отклонение от единицы позволяет изменять чувствительность функции потерь к различным токенам, усиливая вклад информативных токенов и ослабляя вклад менее значимых, что приводит к более эффективному обучению модели.
В основе подхода лежит механизм «Trust Gate», зависимый от уверенности модели. Данный механизм динамически оценивает надежность каждого входного сигнала (токена) на основе внутренней уверенности модели в его правильности. Сигналам с высокой уверенностью присваивается больший вес при обновлении параметров модели, что позволяет сосредоточиться на наиболее достоверной информации и снизить влияние зашумленных или ошибочных данных. Фактически, Trust Gate функционирует как адаптивный фильтр, позволяющий модели самостоятельно определять приоритетность обучения на основе оценки качества получаемых сигналов, что повышает эффективность и стабильность процесса обучения. Математически, это реализуется через функцию, определяющую вес сигнала в зависимости от его уверенности, и позволяет гибко управлять балансом между использованием данных и предотвращением переобучения.
![В процессе обучения Llama-3.1-8B с использованием DEFT наблюдается эволюция доверия [latex]a[/latex] и средней вероятности [latex]p[/latex], причём начальные значения [latex]a[/latex] адаптируются к уровню предварительных знаний модели (например, 0.65 для Model-Strong и 0.05 для Model-Weak), а его устойчивый рост обеспечивает плавный переход от фазы, ориентированной на покрытие, к фазе уточнения.](https://arxiv.org/html/2602.11424v1/x8.png)
Динамическая Энтропия для Адаптивного Обучения
Динамическая настройка энтропии (DEFT) представляет собой параметрически-свободный подход к обучению, использующий предсказательную энтропию и энтропию Реньи для аппроксимации механизмов условного управления потоком данных. В основе DEFT лежит вычисление энтропии предсказаний модели, которое служит индикатором неопределенности. H(x) = - \sum_{i} p(x_i) \log p(x_i) — стандартная формула для вычисления энтропии, в то время как энтропия Реньи обеспечивает обобщенную меру неопределенности, позволяя адаптировать чувствительность к различным уровням неопределенности. Используя эти показатели, DEFT динамически регулирует “доверительный шлюз” (Trust Gate) для управления потоком информации, фокусируясь на областях с наибольшей неопределенностью и, следовательно, наибольшим потенциалом для получения информации.
Механизм DEFT динамически регулирует “Trust Gate” на основе величины неопределенности прогноза, измеряемой через энтропию. Более высокая энтропия указывает на большую неопределенность в предсказании, что приводит к увеличению веса “Trust Gate” и, следовательно, к большему акценту на информацию, способную уменьшить эту неопределенность. Фактически, система отдает приоритет данным, которые максимально снижают энтропию, тем самым максимизируя информационный прирост и улучшая процесс обучения. Регулировка “Trust Gate” основана на вычислении H(p(y|x)) — энтропии условного распределения вероятности класса y при заданном входе x.
Адаптивный подход, основанный на динамической энтропии, демонстрирует улучшенную обобщающую способность в задачах кросс-доменной генерализации, особенно в условиях сильных априорных знаний модели (Model-Strong Regime). В ходе экспериментов было зафиксировано среднее увеличение производительности на 8.0% при решении смешанных доменных задач, что свидетельствует об эффективности данного метода в ситуациях, когда модель уже обладает значительным объемом предварительных знаний и способна эффективно использовать дополнительную информацию из новых доменов.
Оценка Эффективности в Различных Режимах Знаний
Оценка производительности на разнообразных наборах данных выявила адаптивность DEFT: в рамках режима “Сильные модели” (Model-Strong Regime) NuminaMath проверяет надёжность логического мышления, в то время как FigFont, используемый в режиме “Слабые модели” (Model-Weak Regime), оценивает способность к приобретению новых знаний. Этот подход позволяет установить, насколько эффективно модель справляется с задачами, требующими либо глубокого понимания и применения уже существующих знаний, либо быстрой адаптации и обучения новым концепциям. Различия в типах задач, представленных в этих наборах данных, подчеркивают универсальность DEFT и его способность эффективно функционировать в различных условиях, где уровень предварительных знаний существенно различается.
Набор данных m23K, используемый в рамках промежуточного режима тестирования, представляет собой сбалансированный инструмент оценки, позволяющий одновременно проверить как уровень знаний модели, так и её способность к логическому мышлению. В отличие от наборов данных, ориентированных исключительно на проверку либо знаний, либо рассуждений, m23K требует от модели демонстрации обеих компетенций для успешного решения задач. Это достигается за счёт тщательного отбора вопросов, требующих не просто воспроизведения заученной информации, но и её применения в новых, нестандартных ситуациях, что делает m23K ценным индикатором общей интеллектуальной зрелости языковой модели и её способности к адаптации.
Представленные сравнительные тесты демонстрируют, что DEFT не только повышает общую производительность модели, но и существенно улучшает её способность к обобщению знаний, независимо от уровня предварительной подготовки. В частности, зафиксировано увеличение точности на 3.5% при решении общих задач и на 8.0% в математических вычислениях по сравнению с базовой моделью -p-p. Использование DEFT в сочетании с Llama3.1-8B позволило добиться средней прибавки в производительности в 3.62 и 1.46 процента в режимах, требующих высокой, средней и низкой степени предварительных знаний соответственно, что подтверждает способность модели эффективно адаптироваться к различным условиям и извлекать пользу из имеющихся данных.
К Интеллектуальной Оценке Значимости Токенов
Оценка значимости каждого токена, а также связанные с этим методы, такие как фильтрация на уровне токенов и перевзвешивание потерь, представляют собой важный шаг к созданию более интеллектуальных парадигм обучения. Традиционные подходы часто рассматривают все элементы входной последовательности как равноценные, что приводит к неэффективному использованию вычислительных ресурсов и снижению качества модели. В отличие от этого, методы оценки токенов позволяют выявлять наиболее информативные и важные элементы, фокусируя процесс обучения именно на них. Это, в свою очередь, способствует повышению точности, эффективности и устойчивости больших языковых моделей, позволяя им лучше понимать и генерировать текст, а также более эффективно адаптироваться к новым данным и задачам. Такой подход открывает новые возможности для оптимизации процесса обучения и создания моделей, способных к более сложному и осмысленному взаимодействию с информацией.
Применение преобразования Кэли в процессе вывода траектории Trust Gate демонстрирует значительный потенциал использования передовых математических инструментов в области обучения с подкреплением на основе обратной связи от человека (SFT). Данное преобразование, являющееся мощным инструментом в теории групп и матриц, позволило разработать более эффективный и стабильный механизм управления процессом обучения. В частности, преобразование Кэли обеспечивает гладкий переход между различными состояниями модели, что способствует более точному и надежному формированию желаемого поведения. Успешное применение данного подхода подчеркивает важность интеграции сложных математических концепций в современные методы машинного обучения, открывая новые горизонты для создания интеллектуальных и эффективных языковых моделей. Cayley(\alpha) = (I - \alpha)(I + \alpha)^{-1}
Оценка значимости каждого токена в процессе обучения больших языковых моделей (LLM) открывает путь к значительному повышению их эффективности и устойчивости. Традиционные методы обучения часто рассматривают все токены как равноценные, игнорируя тот факт, что некоторые из них несут более важную информацию для формирования осмысленного ответа. Внедрение стратегий адаптивного обучения, основанных на явной оценке токенов, позволяет моделям сосредоточиться на наиболее релевантных элементах входных данных, что приводит к более быстрой сходимости, снижению вычислительных затрат и повышению устойчивости к шуму и нерелевантной информации. Такой подход позволяет не просто создавать мощные модели, но и оптимизировать процесс обучения, делая его более эффективным и экономичным, что особенно важно для масштабных LLM.
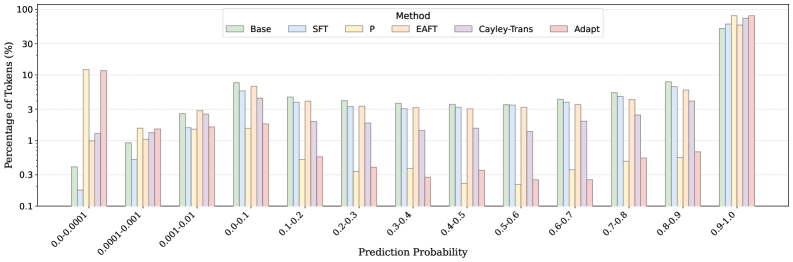
Исследование демонстрирует, что эффективная настройка больших языковых моделей требует не просто слепого следования градиентам, но и тонкого управления процессом обучения. Авторы предлагают подход Dynamic Entropy Fine-Tuning (DEFT), который динамически регулирует вклад каждого градиента, основываясь на уверенности модели и энтропии. Это напоминает высказывание Джона фон Неймана: «В науке не бывает простых ответов, только более сложные вопросы.» Как и в математике, где каждая аксиома должна быть обоснована, DEFT требует, чтобы каждый градиент «заслуживал» своего влияния на процесс обучения. Подход, основанный на энтропии, позволяет модели исследовать пространство решений, избегая преждевременной уверенности и повышая обобщающую способность, что соответствует принципу масштабируемости и асимптотической устойчивости, которым так дорожит истинная элегантность кода.
Куда же дальше?
Представленная работа, хоть и демонстрирует изящный способ управления градиентами на основе энтропии, оставляет ряд вопросов без ответа. Идея динамической регулировки «доверия» модели к своим предсказаниям — это, безусловно, шаг в правильном направлении, однако возникает закономерный вопрос: насколько универсальна эта метрика «доверия»? Необходимы более строгие математические обоснования, доказывающие её адекватность для различных типов задач и архитектур языковых моделей. Просто «работает на тестах» — недостаточное условие для признания решения элегантным.
Особое внимание следует уделить исследованию взаимосвязи между энтропией и обобщающей способностью. Не является ли снижение энтропии лишь симптомом переобучения, маскирующимся под «уверенность»? Необходимо разработать метрики, позволяющие отделить истинное улучшение обобщения от простого запоминания тренировочных данных. Следующим шагом видится формализация понятия «оптимальной энтропии» — той, что максимизирует обобщающую способность без ущерба для точности.
В конечном счёте, задача состоит не в том, чтобы «подкрутить» градиенты, а в том, чтобы понять фундаментальные принципы обучения языковых моделей. Предложенный подход, безусловно, интересен, но лишь как промежуточный шаг на пути к созданию алгоритмов, основанных на строгой математической логике, а не на эмпирических наблюдениях. Иначе мы обречены на бесконечную гонку за новыми «хитростями», не приближающими нас к истинному пониманию.
Оригинал статьи: https://arxiv.org/pdf/2602.11424.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Нефть вниз, Азия вверх: Как геополитика меняет инвестиционный ландшафт (25.05.2026 06:15)
- Опасный онлайн: Как нейросети распознают травлю в испаноязычном интернете
- ServiceNow: Искуственный ажиотаж или реальная возможность?
- ДВМП акции прогноз. Цена FESH
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Стоит ли покупать доллары за колумбийские песо сейчас или подождать?
- ADA’s Wild Ride: Buy the Dip or Cry in the Corner? 🤑💎
- Ростелеком акции прогноз. Цена RTKM
- МФК Займер акции прогноз. Цена ZAYM
2026-02-15 02:09