Автор: Денис Аветисян
В статье представлена модель MTFM, разработанная для повышения эффективности и гибкости рекомендательных систем в условиях растущих объемов данных и разнообразия сценариев.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал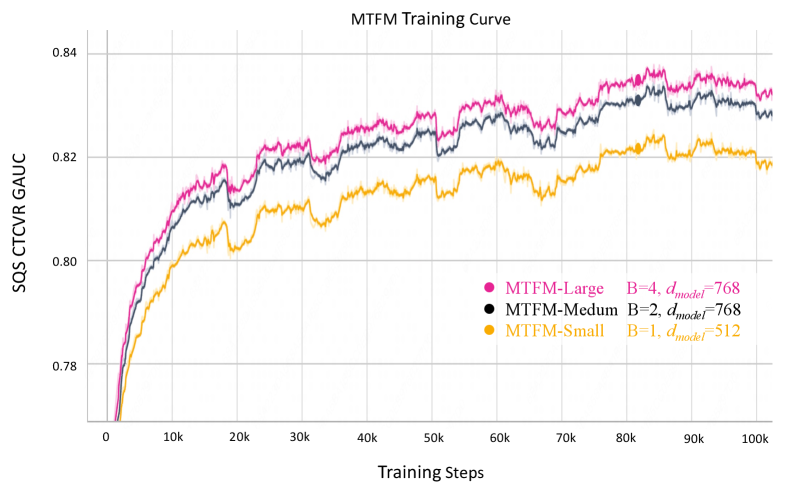
Предлагается масштабируемая и не требующая выравнивания базовая модель для рекомендаций, использующая гетерогенную токенизацию и гибридный механизм внимания.
Существующие кросс-доменные и многосценарные системы рекомендаций зачастую требуют значительных ресурсов и строгой предварительной синхронизации данных, ограничивая их масштабируемость. В данной работе представлена модель ‘MTFM: A Scalable and Alignment-free Foundation Model for Industrial Recommendation in Meituan’, предлагающая новый подход к решению этой проблемы. MTFM преобразует разнородные данные в гетерогенные токены, позволяя эффективно объединять знания из различных сценариев без предварительной синхронизации, и использует гибридный механизм внимания для повышения эффективности. Сможет ли данная архитектура стать основой для создания универсальных и масштабируемых систем рекомендаций в условиях растущей сложности и разнообразия данных?
Фундаментальные Модели: Новая Эра Рекомендаций
Традиционные системы рекомендаций часто сталкиваются с проблемами масштабируемости и обобщения при переходе к новым областям применения. В частности, каждая новая платформа или тип контента требует существенной переработки и переобучения модели, что связано со значительными затратами ресурсов и времени. Это обусловлено тем, что большинство таких систем разрабатываются с учетом специфических характеристик конкретной задачи, что делает их неспособными эффективно адаптироваться к новым данным или сценариям. В результате, для каждой новой платформы или типа контента необходимо создавать и поддерживать отдельные системы, что приводит к дублированию усилий и снижению общей эффективности. Подобные ограничения препятствуют созданию универсальных и масштабируемых решений, способных охватить широкий спектр рекомендательных задач.
В настоящее время наблюдается переход к единой архитектуре, подобной фундаментальным моделям, как способ повышения эффективности и масштабируемости систем рекомендаций. Этот подход вдохновлен успехами, достигнутыми в области обработки естественного языка, где предварительно обученные модели демонстрируют способность адаптироваться к различным задачам с минимальной дообучаемостью. Вместо создания отдельных моделей для каждого типа данных или сценария, единая архитектура позволяет использовать общий набор параметров, обученных на большом объеме разнообразных данных. Это не только снижает вычислительные затраты и упрощает процесс разработки, но и открывает возможности для переноса знаний между различными доменами, что особенно ценно в условиях постоянно меняющихся потребностей пользователей и расширения ассортимента предлагаемых товаров или услуг.
Основная сложность при внедрении архитектур фундаментальных моделей в системы рекомендаций заключается в адаптации к специфике данных и задач, характерных для этой области. В отличие от обработки естественного языка, где последовательности слов обладают внутренней структурой, данные рекомендаций часто представлены в виде разреженных взаимодействий пользователей и элементов, что требует новых подходов к кодированию и обучению. Необходимо учитывать неявный характер обратной связи — пользователи чаще выражают предпочтения через действия, а не прямые оценки — и разрабатывать методы, способные эффективно извлекать полезную информацию из этих неполных данных. Кроме того, задача рекомендации предполагает прогнозирование будущих предпочтений, что требует от модели способности к обобщению и адаптации к динамично меняющимся интересам пользователей, что значительно усложняет процесс обучения и требует инновационных архитектурных решений.
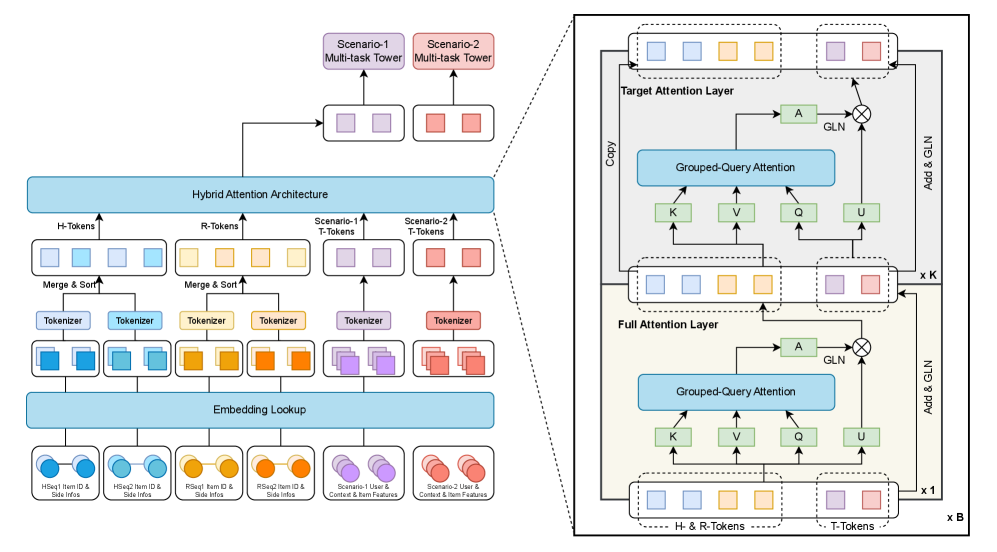
MTFM: Унифицированная Архитектура Рекомендаций
Архитектура MTFM преодолевает ограничения существующих рекомендательных систем за счет применения парадигмы Foundation Model. Традиционные подходы часто требуют обучения отдельных моделей для каждого типа данных или задачи, что приводит к фрагментации знаний и снижению обобщающей способности. В отличие от них, MTFM использует предварительно обученную модель, способную адаптироваться к различным источникам данных и типам взаимодействий, обеспечивая единое представление пользователей и объектов. Это позволяет модели эффективно переносить знания между различными задачами и доменами, улучшая точность и эффективность рекомендаций, особенно в условиях ограниченного количества данных или холодных стартов.
Ключевой особенностью архитектуры MTFM является использование гетерогенной токенизации, позволяющей обрабатывать и унифицировать данные из различных источников и предметных областей. В отличие от традиционных подходов, требующих предварительной обработки и приведения данных к единому формату, гетерогенная токенизация позволяет модели напрямую работать с разнородными входными данными, такими как идентификаторы пользователей, товаров, атрибуты, текстовые описания и история взаимодействий. Каждый тип данных токенизируется специфичным образом, сохраняя при этом возможность представления их в едином векторном пространстве. Это достигается путем использования отдельных словарей токенов для каждого типа данных и последующего объединения этих представлений в контексте Transformer-архитектуры, что позволяет модели улавливать сложные взаимосвязи между различными типами информации и повышать точность рекомендаций.
В основе архитектуры MTFM лежит трансформерная модель, адаптированная для задач рекомендаций. В отличие от стандартных реализаций, модель использует механизм внимания (attention) для выявления сложных зависимостей между пользователями и элементами, а также для учета последовательности действий пользователей. Адаптация включает в себя модификацию слоев самовнимания и feed-forward сетей с целью более эффективного захвата поведенческих закономерностей, таких как частота взаимодействия, длительность сессий и разнообразие просматриваемого контента. Для повышения точности рекомендаций используются специализированные функции потерь, оптимизированные для учета неявной обратной связи и холодных стартов, что позволяет модели адаптироваться к новым пользователям и элементам с минимальным количеством данных.
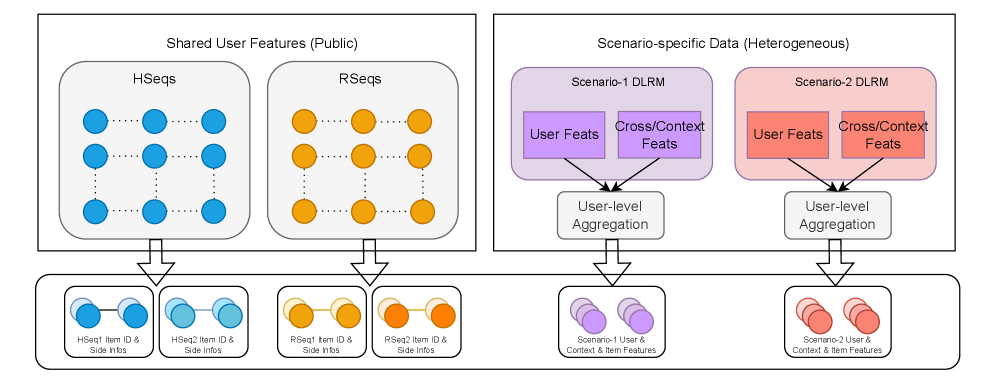
Оптимизация для Масштаба и Эффективности
Метод MTFM использует агрегацию на уровне пользователей для преобразования фрагментированных данных о взаимодействии пользователей в плотные последовательности, пригодные для обучения. Вместо обработки отдельных событий, MTFM объединяет все взаимодействия конкретного пользователя в единую последовательность, что позволяет модели улавливать более сложные паттерны поведения. Такой подход эффективно решает проблему разреженности данных, возникающую при работе с большими объемами пользовательских взаимодействий, и значительно повышает эффективность обучения моделей, особенно в задачах рекомендаций и прогнозирования.
Оптимизация конвейера CPU-GPU, в сочетании с использованием FlashAttention-2, позволила устранить узкие места, связанные с синхронизацией данных между центральным и графическим процессорами. FlashAttention-2 снижает потребность в обмене данными между памятью GPU и DRAM, что существенно уменьшает задержки. В результате данной оптимизации зафиксировано двукратное увеличение пропускной способности обучения (training throughput) по сравнению с предыдущими реализациями. Это достигается за счет параллельной обработки данных и минимизации времени ожидания, что особенно важно при работе с большими объемами данных и сложными моделями.
Методы структурированной разреженности (structured sparsity) позволяют существенно уменьшить размер модели машинного обучения за счет удаления избыточных параметров, при этом сохраняя или даже улучшая точность. Это достигается путем систематического удаления целых групп весов или нейронов, что упрощает вычисления и снижает потребность в памяти. Уменьшение размера модели напрямую влияет на скорость инференса, поскольку требуется меньше операций для получения прогнозов. Такой подход критически важен для эффективного развертывания моделей в масштабе, особенно в условиях ограниченных ресурсов или при высоких требованиях к задержке обработки запросов.

Превосходная Производительность и Широкая Применимость
Модель MTFM демонстрирует стабильное превосходство над существующими решениями в задачах рекомендаций. В ходе всесторонних экспериментов, MTFM последовательно обходит такие передовые модели, как DCNv2, MMoE, RankMixer, OneTrans, MTGR, STAR и PEPNet. Данное превосходство проявляется в различных сценариях и на разнообразных наборах данных, что подтверждает эффективность предложенного подхода к моделированию пользовательских предпочтений и построению более точных рекомендаций. Результаты показывают, что MTFM не только улучшает показатели точности, но и способствует повышению конверсии и общей эффективности системы рекомендаций.
Оценка модели MTFM с использованием ключевых метрик, таких как AUC, CTR, GAUC и CTCVR, демонстрирует её превосходство в прогнозировании предпочтений пользователей и повышении конверсии. В ходе экспериментов зафиксировано значительное улучшение показателей: средний прирост GAUC составил 0.36 процентных пункта для CTR и 0.29 процентных пункта для GAUC. Эти результаты подтверждают, что MTFM обладает повышенной точностью в определении релевантных предложений для каждого пользователя, что, в свою очередь, приводит к более эффективному взаимодействию и увеличению числа целевых действий.
Результаты онлайн A/B тестирования демонстрируют значительное повышение эффективности модели MTFM в реальных условиях. В ходе экспериментов было зафиксировано увеличение количества оформленных заказов на платформе SQS на 2.98%, что свидетельствует о более высокой конверсии пользователей, взаимодействующих с рекомендациями, генерируемыми моделью. Аналогичный положительный эффект наблюдался и на платформе PHF, где количество заказов увеличилось на 1.45%. Эти данные подтверждают практическую ценность MTFM и её способность приносить ощутимые результаты для бизнеса, улучшая ключевые показатели эффективности и стимулируя рост продаж.
Модель MTFM демонстрирует высокую обобщающую способность и адаптивность к новым областям благодаря использованию принципов масштабирования и унифицированной архитектуры. В основе подхода лежит идея, что путем увеличения объема данных и сложности модели можно добиться улучшения производительности в различных сценариях. Унифицированная архитектура позволяет MTFM эффективно переносить знания, полученные в одной области, в другую, минимизируя необходимость в переобучении или существенной модификации модели. Это обеспечивает стабильно высокие результаты в различных рекомендательных задачах и позволяет легко адаптировать MTFM к новым данным и требованиям, что особенно важно в динамично меняющихся онлайн-средах.
Изучение представленной модели MTFM неизбежно наводит на мысль о хрупкости любого «революционного» подхода. Авторы стремятся к масштабируемости и эффективности, используя гетерогенную токенизацию и гибридный механизм внимания. Но, как показывает опыт, даже самая элегантная архитектура рано или поздно столкнется с суровой реальностью продакшена. Впрочем, это не умаляет ценности исследования — лишь напоминает о цикличности технологического прогресса. Как точно подметил Блез Паскаль: «Все великие дела требуют времени». И неважно, речь о создании фундаментальной модели или о простой отладке бага — рано или поздно все сводится к терпению и постоянному труду над ошибками. А система, как известно, всегда жива, пока есть баги.
Что дальше?
Представленная работа, безусловно, добавляет ещё один кирпичик в здание «фундаментальных моделей для рекомендаций». Однако, за красивыми графиками масштабирования неизбежно скрываются вопросы, которые останутся актуальными ещё долго. Гетерогенная токенизация и гибридное внимание — это, конечно, интересно, но всегда найдётся новый тип данных, который потребует переосмысления всей архитектуры. Или новый способ обхода ограничений, которые казались непреодолимыми.
Обещания «бесконечной масштабируемости» уже звучали не раз. Вспомните 2012-й — тогда тоже говорили о прорывных решениях, которые вот-вот изменят мир. Пока же, реальность такова, что каждый новый уровень масштаба требует всё более сложных и дорогих решений по оптимизации. И, если тесты показывают зелёный свет, это, скорее всего, означает, что они попросту ничего не проверяют.
Вероятно, следующим этапом станет поиск способов интеграции этих моделей с реальными бизнес-требованиями, а не просто демонстрация их возможностей на синтетических данных. И, конечно, неизбежно возникнет необходимость в объяснении того, почему модель приняла то или иное решение. Ведь даже самая эффективная система бесполезна, если никто не понимает, как она работает. Каждая «революция» в итоге становится лишь техдолгом.
Оригинал статьи: https://arxiv.org/pdf/2602.11235.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Крипто-волатильность: BlackRock продает, BitMine может войти в индекс Russell 1000, геополитика давит (25.05.2026 15:15)
- ДВМП акции прогноз. Цена FESH
- Сегежа акции прогноз. Цена SGZH
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Опасный онлайн: Как нейросети распознают травлю в испаноязычном интернете
- ServiceNow: Искуственный ажиотаж или реальная возможность?
- Крипто встряска: наконец-то пришел альтсезон? Приготовьтесь к хаосу!
- Тесла: Лабиринт Ожиданий
2026-02-16 03:25