Автор: Денис Аветисян
Исследователи предлагают метод повышения вариативности ответов больших языковых моделей без ущерба для их качества и соответствия требованиям.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Различные стратегии демонстрируют взаимосвязь между качеством и разнообразием генерируемых результатов: стратегии, производящие широкий спектр ответов [latex] (y^{+}_{1}, \cdot s, y^{+}_{n}) [/latex] и [latex] (y^{-}_{1}, \cdot s, y^{-}_{m}) [/latex], могут обладать как высоким качеством и точностью, так и высокой степенью разнообразия при более низком качестве, в то время как стратегии с ограниченным разнообразием склонны демонстрировать повышенное качество результатов.](https://arxiv.org/html/2602.15894v1/image.png)
В статье представлен алгоритм Quality-constrained Entropy Maximization Policy Optimization (QEMPO) для оптимизации разнообразия при обучении языковых моделей с подкреплением.
Современные методы выравнивания больших языковых моделей (LLM) зачастую приводят к снижению разнообразия генерируемого ими текста. В работе, озаглавленной ‘Quality-constrained Entropy Maximization Policy Optimization for LLM Diversity’, предложен новый подход, Quality-constrained Entropy Maximization Policy Optimization (QEMPO), направленный на повышение разнообразия выходных данных LLM при сохранении их качества. QEMPO позволяет оптимизировать политику генерации текста, максимизируя энтропию выходных данных при заданных ограничениях по качеству, что демонстрирует сопоставимые или даже лучшие результаты по сравнению с RLHF, но с повышенным разнообразием. Возможно ли дальнейшее совершенствование методов управления балансом между качеством и разнообразием в LLM, и какие новые горизонты это откроет для генеративных моделей?
Выравнивание больших языковых моделей: сложная задача
Несмотря на впечатляющие возможности современных больших языковых моделей, их согласование с намерениями человека остается серьезной проблемой. Эти модели, обученные на огромных объемах текстовых данных, способны генерировать связные и грамматически правильные тексты, однако не всегда понимают контекст и цели, которые преследует человек. Это несоответствие может приводить к генерации нерелевантных, вводящих в заблуждение или даже опасных ответов, несмотря на кажущуюся правдоподобность. Следовательно, задача выравнивания — обеспечение того, чтобы модель не просто генерировала текст, а делала это в соответствии с человеческими ценностями и ожиданиями — становится ключевой для безопасного и эффективного использования этих мощных инструментов.
Традиционные методы обучения с учителем, несмотря на свою эффективность в решении многих задач, оказываются недостаточно чувствительными к тонкостям человеческих предпочтений. Это приводит к тому, что модели, обученные таким образом, могут выдавать результаты, формально правильные, но не соответствующие ожиданиям или даже потенциально опасные. Проблема заключается в сложности кодирования субъективных критериев, таких как креативность, этичность или просто здравый смысл, в числовые метрики, понятные алгоритму. В результате, модель может оптимизировать лишь узкий аспект задачи, игнорируя более широкие последствия или контекст, что проявляется в непредсказуемом поведении и необходимости постоянного контроля со стороны человека. Неспособность адекватно учесть нюансы человеческих ценностей является серьезным препятствием на пути к созданию действительно полезных и безопасных систем искусственного интеллекта.
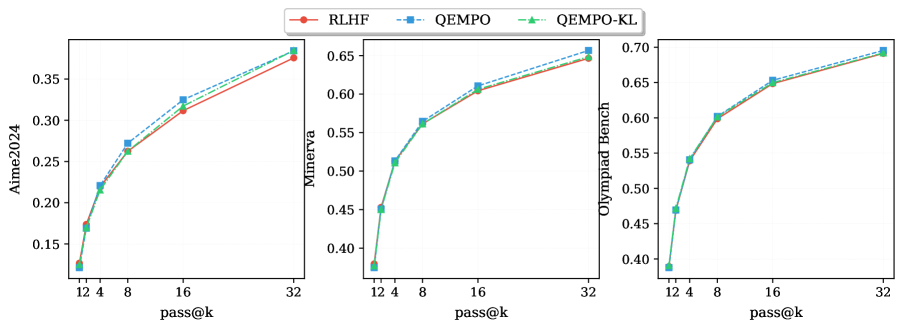
Оценка соответствия больших языковых моделей человеческим намерениям является критически важной задачей, и для этого используются такие метрики, как Pass@k. Анализ результатов на сложных наборах данных, таких как GSM8K и MATH500, последовательно выявляет недостатки в решении задач, требующих глубокого логического мышления. Недавние исследования показали, что, несмотря на широкое распространение обучения с подкреплением на основе обратной связи от человека (RLHF), этот подход всё ещё далёк от идеала в достижении надёжной и точной работы в сложных областях. Это подчеркивает настоятельную необходимость разработки и внедрения новых стратегий выравнивания, способных преодолеть существующие ограничения и обеспечить более надёжные и безопасные языковые модели.
Обучение с подкреплением и выравнивание на основе предпочтений
Обучение с подкреплением на основе обратной связи от человека (RLHF) представляет собой перспективный подход к согласованию больших языковых моделей (LLM) с намерениями пользователей. В основе RLHF лежит обучение модели вознаграждения (Reward Model) на данных, отражающих предпочтения человека относительно различных ответов модели. Модель вознаграждения прогнозирует, насколько хорошо конкретный ответ соответствует человеческим предпочтениям, что позволяет использовать ее в качестве функции вознаграждения в алгоритме обучения с подкреплением. В процессе обучения, LLM настраивается для максимизации предсказанного вознаграждения, что, в идеале, приводит к генерации ответов, более соответствующих ожиданиям человека и демонстрирующих желаемое поведение. Эффективность RLHF обусловлена возможностью использования субъективных оценок человека для формирования функции вознаграждения, что позволяет решать задачи, для которых сложно определить четкие и объективные критерии оценки.
Прямая оптимизация предпочтений (Direct Preference Optimization, DPO) представляет собой метод обучения больших языковых моделей (LLM), который напрямую оптимизирует политику модели на основе данных о предпочтениях, избегая необходимости в явной функции вознаграждения. Вместо обучения модели для предсказания вознаграждения за определенный вывод, DPO использует данные, в которых указано, какой из двух вариантов ответа предпочтительнее для человека. Оптимизация происходит путем максимизации вероятности выбора предпочтительного ответа, что позволяет модели напрямую учиться на человеческих суждениях и повышать качество генерируемого текста без промежуточного этапа обучения модели вознаграждения. Этот подход упрощает процесс обучения и потенциально обеспечивает более точное соответствие модели предпочтениям пользователей.
Методы обучения с подкреплением на основе обратной связи от человека (RLHF), несмотря на свою эффективность, часто сталкиваются с проблемами разнообразия генерируемых ответов и риском “взлома” системы вознаграждений. Это проявляется в том, что модель оптимизируется для максимизации сигнала вознаграждения, а не для достижения истинной полезности или соответствия намерениям пользователя. В результате, модель может выдавать предсказуемые, но не всегда оптимальные или творческие ответы, фокусируясь на формальных аспектах, которые легко оценить, а не на содержательной помощи. Данная проблема ограничивает возможности RLHF в генерации разнообразных и полезных результатов, что и является областью, над которой направлены методы, представленные в данной работе.
Максимизация энтропии для надёжного и разнообразного выравнивания
Оптимизация политики с максимизацией энтропии при ограничении качества предполагает увеличение энтропии выходных данных модели, одновременно поддерживая заданный уровень качества. Это достигается путем поощрения исследования различных вариантов ответов, а не концентрации на единственном, наиболее вероятном. H(p) = - \sum_{i} p(i) \log p(i) — формула расчета энтропии, где p(i) — вероятность i-го исхода. Данный подход направлен на снижение зависимости от единого «лучшего» ответа, повышая устойчивость и разнообразие генерируемых данных, что особенно важно в задачах, требующих креативности или адаптации к меняющимся условиям.
Методы QEMPO и QEMPO-KL используют энтропию и расхождение Кульбака-Лейблера (KL-дивергенцию) для достижения баланса между исследованием пространства решений и поддержанием заданного уровня качества генерируемого контента. Энтропия, в данном контексте, измеряет случайность или разнообразие выходных данных модели, стимулируя генерацию нескольких возможных ответов вместо концентрации на единственном, наиболее вероятном. KL-дивергенция, D_{KL}(P||Q), используется для ограничения отклонения от исходного распределения, обеспечивая, чтобы исследуемые варианты не уходили слишком далеко от желаемого уровня качества и оставались релевантными. Комбинирование этих двух концепций позволяет алгоритмам эффективно исследовать пространство решений, избегая при этом генерации некачественных или нерелевантных ответов.
В отличие от традиционных методов обучения с подкреплением на основе градиента политики, которые зачастую склонны к эксплуатации наиболее вероятных действий в ущерб исследованию альтернатив, предложенный подход нацелен на максимизацию энтропии выходных данных. Это позволяет генерировать более разнообразные и устойчивые результаты, избегая застревания в локальных оптимумах и предсказуемых ответах. Экспериментальные данные демонстрируют, что алгоритмы QEMPO и QEMPO-KL обеспечивают повышенное разнообразие генерируемого контента по сравнению с RLHF (Reinforcement Learning from Human Feedback), при этом сохраняя сопоставимый уровень качества.
К более надёжным и надёжным LLM
Набор данных UltraFeedback представляет собой ценный инструмент для обучения и оценки методов выравнивания больших языковых моделей. Он предоставляет исследователям возможность систематически измерять прогресс в создании моделей, которые лучше соответствуют человеческим предпочтениям и намерениям. Благодаря структурированным данным обратной связи, полученным от людей, UltraFeedback позволяет оценивать различные подходы к обучению с подкреплением и другим методам выравнивания, выявляя сильные и слабые стороны каждого из них. Это, в свою очередь, способствует разработке более надежных и полезных языковых моделей, способных генерировать текст, который не только грамматически правилен, но и соответствует ожиданиям пользователей, а также способствует дальнейшему развитию области искусственного интеллекта.
Метод обучения с мягкими предпочтениями значительно расширяет возможности языковых моделей в плане разнообразия генерируемых текстов. Традиционные подходы, основанные на минимизации перекрёстной энтропии, зачастую приводят к предсказуемым и однообразным ответам. В отличие от них, мягкое обучение предпочтений разделяет понятия энтропии и перекрёстной энтропии, позволяя модели исследовать более широкий спектр возможных ответов. Это разделение стимулирует генерацию не только точных, но и более нюансированных, креативных и неожиданных текстов, что особенно важно для задач, требующих творческого подхода или адаптации к различным стилям. По сути, модель получает возможность балансировать между следованием заданным предпочтениям и исследованием новых, потенциально более интересных решений, что приводит к более богатому и полезному результату.
Современные большие языковые модели (LLM) стремятся не только к точности ответов, но и к разнообразию генерируемого текста, что является ключевым фактором для повышения их надёжности и полезности. Разработанные методы, такие как QEMPO и QEMPO-KL, демонстрируют значительное улучшение метрики Pass@k — вероятности того, что среди нескольких сгенерированных вариантов ответа найдется правильный — особенно при увеличении числа предлагаемых вариантов (k). При этом, качество ответов, полученных с использованием этих подходов, сопоставимо с результатами, достигаемыми с помощью обучения с подкреплением на основе обратной связи от человека (RLHF). Это свидетельствует о важном шаге в создании LLM, способных предоставлять не только точные, но и разнообразные, а следовательно, более надёжные и полезные ответы для пользователей.
Исследование демонстрирует, что стремление к разнообразию в ответах больших языковых моделей не должно идти в ущерб их качеству. Предложенные методы QEMPO и QEMPO-KL направлены на оптимизацию баланса между этими двумя критически важными аспектами. Как заметил Джон Маккарти: «Простота — это конечное совершенство». Эта фраза находит глубокий отклик в контексте данной работы, поскольку сложные алгоритмы, направленные на достижение максимального разнообразия, часто приводят к снижению общей производительности модели. Авторы подчеркивают важность разработки систем, в которых простота и элегантность структуры обеспечивают масштабируемость и устойчивость, а не переусложненные решения, которые могут привести к неожиданным проблемам в будущем. Оптимизация, основанная на четких принципах, позволяет добиться лучших результатов, чем бесконечная гонка за сложностью.
Куда Далее?
Предложенный подход, оптимизирующий энтропию при ограничениях качества, демонстрирует, что разнообразие в генеративных моделях — не просто побочный эффект, а параметр, поддающийся целенаправленной настройке. Однако, эвристика “качество как ограничение” не лишена изящной иронии: сама концепция “качества” остается предметом дебатов, а ее измерение — искусством выбора того, чем пожертвовать ради досягаемого результата. Если система кажется сложной, она, вероятно, хрупка, и предложенный метод, как и любой другой, нуждается в дальнейшей проверке на устойчивость к различным типам входных данных и задачам.
Будущие исследования могли бы сосредоточиться на более тонких метриках качества, учитывающих не только поверхностную грамматическую корректность, но и глубинную семантическую согласованность и оригинальность. Интересным направлением представляется исследование взаимосвязи между энтропией, качеством и предсказуемостью: возможно, оптимальный баланс между этими параметрами различен для разных типов задач и целевых аудиторий.
В конечном счете, задача состоит не в том, чтобы создать модель, генерирующую максимально разнообразные тексты, а в том, чтобы создать систему, способную генерировать тексты, которые одновременно полезны, интересны и, что самое главное, соответствуют намерениям пользователя. Простота и ясность — вот критерии, определяющие жизнеспособность любой системы, и в этой области еще предстоит проделать большую работу.
Оригинал статьи: https://arxiv.org/pdf/2602.15894.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Прогноз нефти
- Институционалы правят бал: Grayscale, Coinbase и Raoul Pal формируют новую реальность крипторынка
- Российский рынок акций: Ожидание мира и дивидендные перспективы (25.05.2026 17:32)
- МФК Займер акции прогноз. Цена ZAYM
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Сегежа акции прогноз. Цена SGZH
- Стоит ли покупать доллары за гонконгские доллары сейчас или подождать?
2026-02-20 04:53