Автор: Денис Аветисян
Исследование демонстрирует, как современные языковые модели могут значительно упростить и ускорить процесс автоматической обработки гарантийных претензий.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал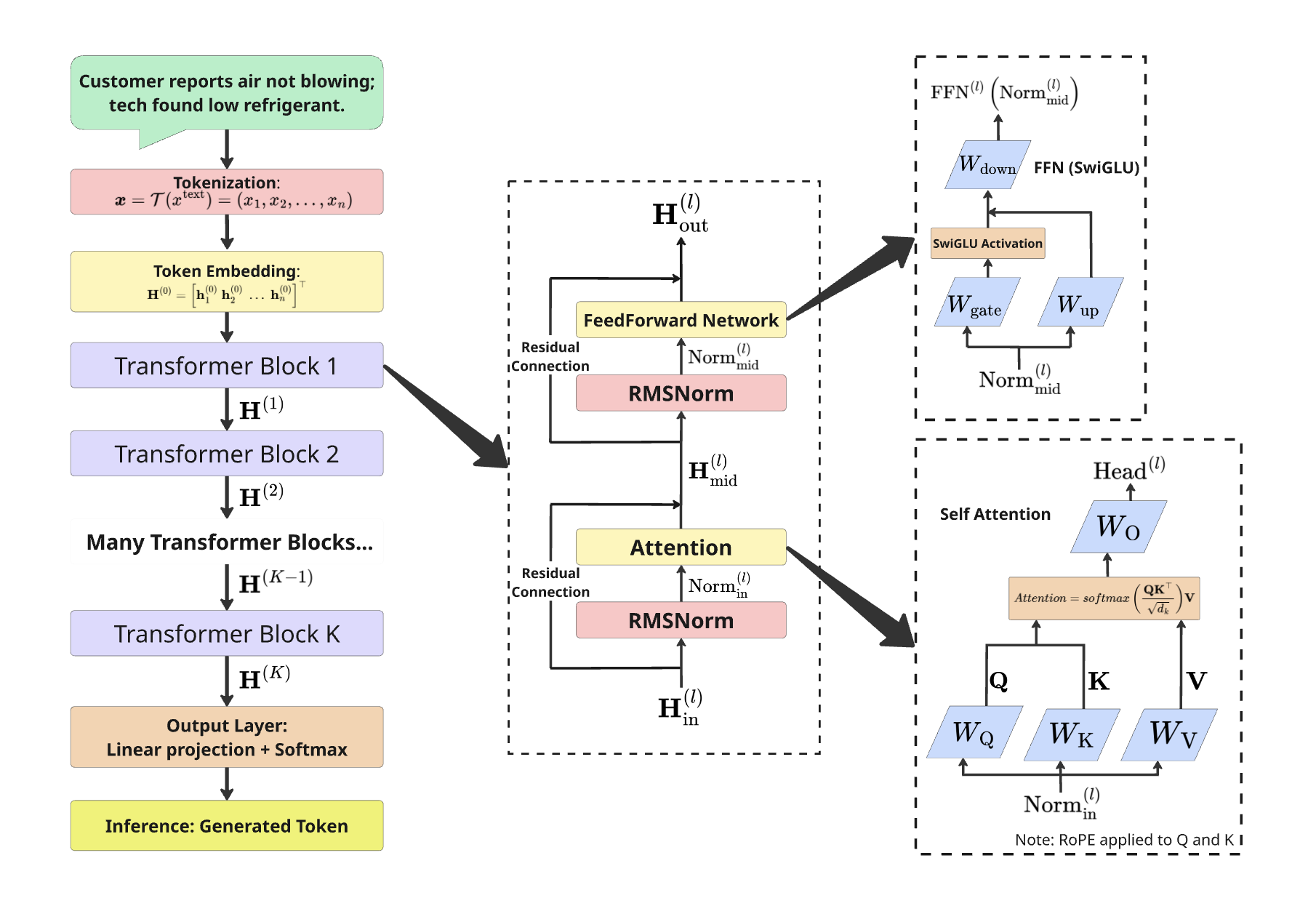
Адаптированная большая языковая модель превосходит универсальные решения в прогнозировании необходимых корректирующих действий и повышает эффективность автоматизации, решая вопросы управления моделями.
Несмотря на значительные успехи больших языковых моделей (LLM) в обработке естественного языка, их применение в регулируемых отраслях, таких как страхование, остается ограниченным. В работе ‘Claim Automation using Large Language Model’ предложен локально развернутый компонент, основанный на LLM, для автоматизации обработки страховых требований и генерации структурированных рекомендаций по устранению неполадок на основе неструктурированных текстовых описаний. Результаты демонстрируют, что специализированная донастройка LLM превосходит универсальные модели и позволяет добиться высокой точности прогнозирования корректирующих действий — до 80% совпадений с эталонными данными. Сможет ли такой подход стать надежным и управляемым строительным блоком для дальнейшей автоматизации процессов в страховой индустрии и других областях, требующих высокой степени доверия к моделям?
Разрушая границы: от признаков к повествованиям
Исторически, актуарная оценка рисков основывалась на преобразовании текстовых данных в числовые признаки, что приводило к утрате ценного семантического контекста. Этот подход, когда текстовое описание претензии по гарантии сводится к набору цифр, неизбежно обедняет информацию, игнорируя нюансы, которые могли бы указать на скрытые факторы риска. Вместо того чтобы анализировать полное описание проблемы и ее обстоятельств, традиционные модели сосредотачивались лишь на формальных параметрах, таких как стоимость ремонта или тип неисправности. В результате, важные сигналы, содержащиеся в свободной форме текста — например, описание условий эксплуатации, субъективная оценка качества товара клиентом или детали взаимодействия со службой поддержки — попросту терялись, ограничивая точность прогнозирования и эффективность обработки претензий.
Традиционный подход к анализу рисков, основанный на преобразовании текстовых данных в числовые признаки, неизбежно приводит к потере ценной семантической информации, содержащейся в описаниях гарантийных случаев. Суть проблемы заключается в том, что приведение богатого повествования к набору дискретных характеристик упрощает сложные взаимосвязи и нюансы, которые могут существенно влиять на оценку риска. Например, тон повествования, специфические детали неисправности, или даже порядок изложения фактов могут содержать критически важные сведения, которые полностью теряются при переходе к числовому представлению. В результате, модели, построенные на таких упрощенных данных, часто оказываются неспособными уловить тонкости, необходимые для точного прогнозирования и эффективной обработки претензий по гарантии, что снижает общую эффективность системы управления рисками.
Традиционные методы оценки рисков, применяемые в страховании, часто сталкиваются с трудностями при работе с неструктурированными текстовыми данными, такими как описания страховых случаев. Неспособность напрямую обрабатывать эти тексты, содержащие важные детали и нюансы, приводит к потере ценной информации, необходимой для точного прогнозирования рисков. В результате, оценка вероятности наступления страхового события может быть неполной или искаженной, что влияет на адекватность страховых тарифов и резервов. Более того, ручная обработка текстовых описаний требует значительных временных и финансовых затрат, замедляет процесс урегулирования страховых случаев и снижает общую эффективность работы страховой компании. Автоматизированный анализ текстовых данных, напротив, позволяет извлекать ключевую информацию, выявлять закономерности и предсказывать будущие события, оптимизируя процесс управления рисками и повышая качество обслуживания клиентов.
Адаптация к реальности: доменная адаптация с LLM
Адаптация больших языковых моделей, в частности, применение метода доменной адаптации, представляет собой перспективный подход к извлечению семантической информации из данных по гарантийным претензиям. Традиционные модели часто испытывают трудности при работе со специализированной терминологией и контекстом, характерным для конкретных отраслей, таких как обработка гарантийных случаев. Доменная адаптация позволяет модели эффективно обучаться на ограниченном объеме данных, специфичных для данной области, и тем самым значительно повышает точность и релевантность обработки информации, содержащейся в описаниях претензий, деталях неисправностей и истории обслуживания.
В качестве базовой модели для адаптации к задачам обработки гарантийных претензий был выбран DeepSeek-R1, большая языковая модель с 8 миллиардами параметров. Данная модель была выбрана из-за ее продемонстрированной эффективности в задачах понимания и генерации текста, а также доступности для исследований и разработок. Адаптация DeepSeek-R1 позволила использовать ее предварительно обученные знания и возможности, минимизируя необходимость обучения с нуля и значительно сокращая требуемые вычислительные ресурсы. Дальнейшая настройка модели проводилась с использованием методов, описанных в данной работе, для оптимизации ее производительности в специфической области гарантийных данных.
Для эффективной адаптации больших языковых моделей (LLM) к специализированным задачам, таким как анализ гарантийных претензий, критически важными оказались параметрически-эффективные методы, в частности, LoRA (Low-Rank Adaptation). LoRA позволяет адаптировать предварительно обученную модель, обучая лишь небольшое количество дополнительных параметров, что существенно снижает вычислительные затраты и требования к объему памяти. Вместо обновления всех параметров модели N, LoRA вводит низкоранговые матрицы \Delta W для адаптации, где ранг r \ll min(N). Это значительно уменьшает количество обучаемых параметров, сохраняя при этом возможность достижения высокой производительности при адаптации модели к новым данным и задачам, особенно в условиях ограниченных вычислительных ресурсов.
Для дальнейшей оптимизации процесса адаптации модели использовалась техника минимизации условной расходимости Кульбака-Лейблера (Conditional KL Minimization). Данный метод направлен на приведение распределения вероятностей, генерируемого моделью, в соответствие с ожидаемым распределением выходных данных. Это достигается путем добавления штрафа к функции потерь, пропорционального расходимости между выходным распределением модели и целевым распределением, заданным экспертами или статистическими данными по рассматриваемым гарантийным случаям. Применение условной KL-минимизации позволяет снизить вероятность генерации нерелевантных или неправдоподобных ответов, повышая общую точность и надежность модели при работе с узкоспециализированными данными.
Предсказывая действия: от текста к структурированному выводу
В основе нашего подхода лежит предсказание корректирующих действий (Corrective Action Prediction) — автоматическая генерация структурированных рекомендаций на основе текстовых описаний гарантийных претензий. Процесс заключается в анализе неструктурированного текста, извлечении релевантной информации и преобразовании её в стандартизированный формат, определяющий необходимые действия по устранению неисправности. Это позволяет перейти от свободного текстового описания проблемы к конкретным, машиночитаемым инструкциям, предназначенным для автоматизации процессов ремонта и обслуживания.
Процесс предсказания корректирующих действий предполагает генерацию структурированного выходного формата, что обеспечивает бесшовную интеграцию с существующими системами и автоматизированными рабочими процессами. Вместо неструктурированного текстового описания проблемы, система формирует данные в четко определенной схеме, например, в виде JSON или XML, содержащие конкретные рекомендации по устранению неисправности. Это позволяет напрямую использовать предсказанные действия в системах управления гарантийными случаями, системах планирования ремонтных работ или автоматизированных системах формирования отчетов, исключая необходимость ручной обработки и интерпретации текстовой информации. Такой подход значительно повышает эффективность и снижает вероятность ошибок, связанных с человеческим фактором.
Оценка точности предсказаний корректирующих действий проводилась с использованием как общих, так и семантических метрик. Общие метрики оценивали общее соответствие предсказаний, в то время как семантические метрики фокусировались на правильности интерпретации смысла и контекста заявки. Результаты показали, что достигнутый уровень производительности статистически не отличается от производительности, демонстрируемой экспертами-людьми при аналогичном анализе гарантийных претензий, что подтверждает применимость и надежность разработанного подхода.
Оценивая семантическую точность: за рамки простой корректности
Традиционные метрики точности, оценивающие соответствие предсказанных и эталонных действий, зачастую оказываются недостаточными для полноценной оценки качества генерируемых корректирующих мер. Несмотря на то, что модель может демонстрировать высокий процент совпадений по символам, это не гарантирует, что предложенное решение действительно эффективно и решает проблему. Важно оценивать смысловую близость, то есть понимать, насколько предложенное действие соответствует необходимому, даже если формулировки различаются. Семантическая корректность, учитывающая контекст и нюансы, позволяет выявить случаи, когда модель предлагает синонимичное, но не функционально эквивалентное решение, что критически важно для повышения надежности и безопасности систем, особенно в задачах, связанных с обслуживанием и ремонтом оборудования.
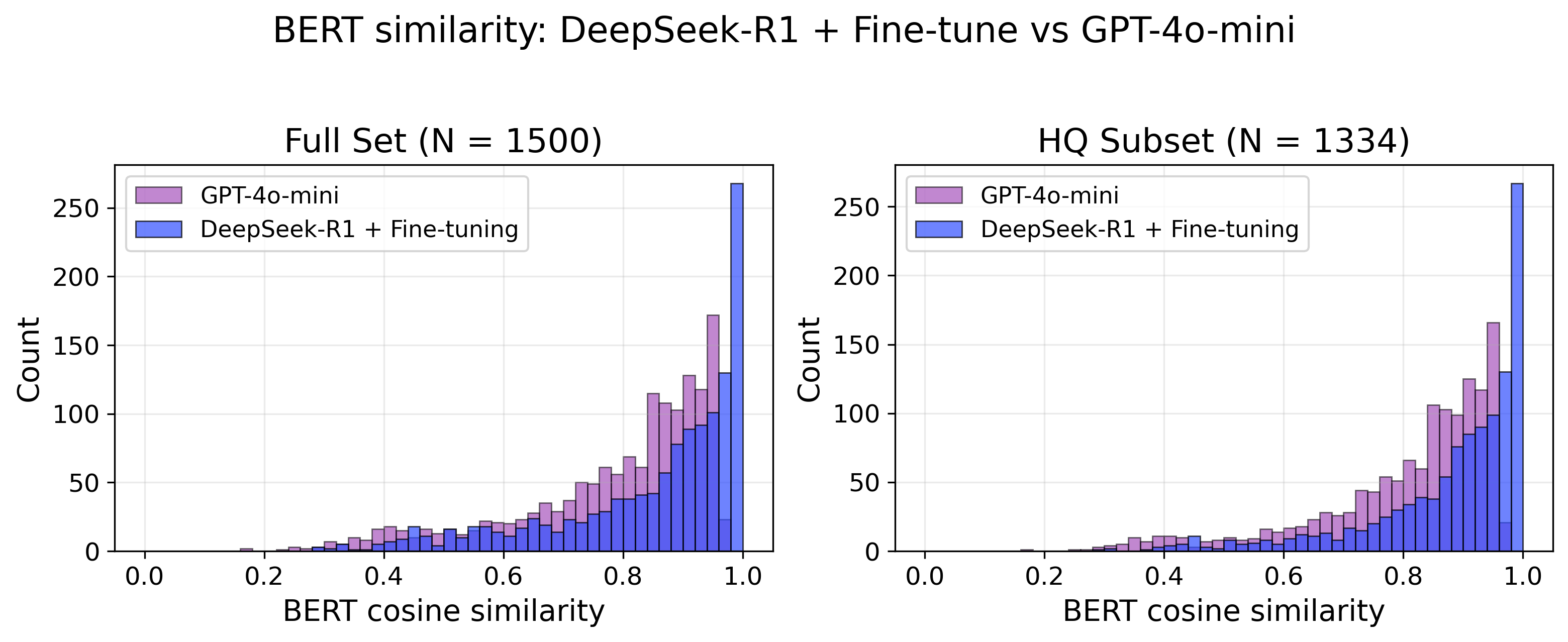
Для оценки семантической точности предложенных корректирующих действий использовалась метрика BERT Cosine Similarity, позволяющая выявлять смысловое соответствие между сгенерированным и эталонным текстом, даже если они не совпадают дословно. В отличие от традиционных метрик, фокусирующихся на точных совпадениях, данный подход учитывает контекст и нюансы языка. На высококачественном (HQ) подмножестве данных модель продемонстрировала впечатляющий результат — показатель BERT Cosine Similarity превысил 0.95, что свидетельствует о высокой степени смысловой согласованности предложенных решений и подтверждает способность модели понимать и генерировать адекватные корректировки.
Комплексная оценка, объединяющая традиционные метрики точности с семантическим анализом, открывает возможности для повышения эффективности оценки рисков и предиктивной диагностики. Разработанная модель демонстрирует производительность, статистически не отличающуюся от вероятности успешного ремонта, полученной на основе эмпирических данных (1.36 \times 10^{-3}). Это свидетельствует о потенциале системы не только в точном определении необходимых действий, но и в прогнозировании вероятности их успешного выполнения, что позволяет оптимизировать графики технического обслуживания и снижать вероятность аварийных ситуаций. Такой подход позволяет перейти от реактивного устранения неисправностей к проактивному управлению техническим состоянием оборудования.
Обучение и валидация предложенного подхода осуществлялись на основе данных по гарантийным претензиям, что позволило обеспечить его устойчивость и обобщающую способность. Анализ этих данных выявил, что в 28,4% случаев диагностировались неверные запчасти для ремонта, а в 23,4% — расхождения в описании неисправности. Полученные результаты не только демонстрируют потенциал для повышения точности диагностики и сокращения количества ошибок, но и предоставляют ценные сведения для дальнейшей оптимизации системы, позволяя сосредоточиться на наиболее проблемных областях и улучшить процесс обучения модели.
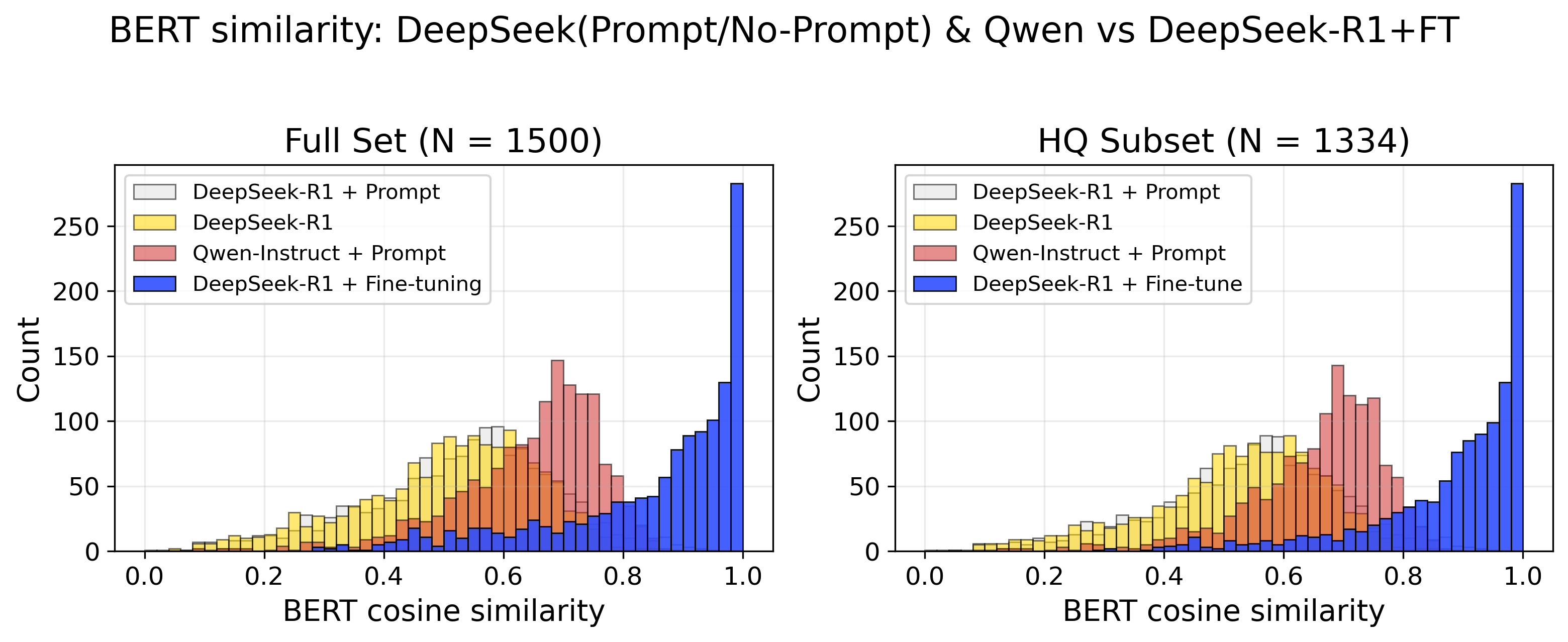
Исследование демонстрирует, что адаптация больших языковых моделей к конкретной предметной области, в данном случае — обработке гарантийных претензий, значительно превосходит использование универсальных моделей. Этот подход позволяет не только автоматизировать предсказание корректирующих действий, но и решать вопросы управления моделями, обеспечивая их надежность и предсказуемость. Как отмечал Джон Маккарти: «Искусственный интеллект — это изучение того, как сделать машины, которые будут делать вещи, которые требуют интеллекта, когда их делают люди». Подобно тому, как человек адаптируется к новым задачам, адаптированная модель демонстрирует повышенную эффективность в узкоспециализированной области, что подтверждает важность реверс-инжиниринга и глубокого понимания системы для достижения оптимальных результатов.
Что дальше?
Представленная работа, по сути, лишь прощупала поверхность. Успешное применение адаптированной большой языковой модели для прогнозирования корректирующих действий в гарантийных претензиях — это, несомненно, шаг вперед, но не стоит забывать о фундаментальной неопределенности, присущей любой системе, построенной на интерпретации естественного языка. Предсказание — это всегда упрощение, а упрощение — это всегда искажение. Вопрос не в том, насколько точно модель предсказывает, а в том, насколько хорошо она сигнализирует о своей собственной некомпетентности.
Будущие исследования должны сосредоточиться не на улучшении точности, а на разработке механизмов самодиагностики и отказоустойчивости. Модель, способная осознавать границы своей компетенции и направлять запрос к эксперту, ценнее, чем модель, выдающая уверенный, но ошибочный ответ. Следует также обратить внимание на проблему «черного ящика» — понимание причин, лежащих в основе предсказаний модели, критически важно для обеспечения доверия и принятия обоснованных решений.
В конечном счете, автоматизация — это не цель, а инструмент. Инструмент, который может освободить человека от рутинной работы, но не заменить его способность к критическому мышлению и творческому решению проблем. Задача науки — не создать идеальную автоматизированную систему, а понять, где заканчивается её применимость и начинается область человеческого разума. Иначе, рискуем создать не помощника, а изощренную систему самообмана.
Оригинал статьи: https://arxiv.org/pdf/2602.16836.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Сбербанк акции прогноз. Цена SBER
- Сегежа акции прогноз. Цена SGZH
- Bitcoin под давлением: RAIN взлетает на фоне геополитической неопределенности (27.05.2026 12:15)
- Опасный онлайн: Как нейросети распознают травлю в испаноязычном интернете
- Три акции для долгосрочного портфеля (на 20 лет вперед)
- Ростелеком акции прогноз. Цена RTKM
- Является ли депег sUSD концом для алгоритмических стейблкоинов? Получите полный обзор!
- МФК Займер акции прогноз. Цена ZAYM
- Прогноз нефти
2026-02-22 05:34