Автор: Денис Аветисян
Исследователи представили семейство компактных и производительных моделей Reverso, способных к точным прогнозам без предварительного обучения на конкретных данных.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал
Модели Reverso используют длинные свёртки, слои DeltaNet и стратегии расширения данных для достижения конкурентоспособной производительности в задачах прогнозирования временных рядов без дополнительной адаптации.
Несмотря на успехи в построении фундаментальных моделей для временных рядов, их масштабируемость часто приводит к избыточной сложности и высоким вычислительным затратам. В данной работе, ‘Reverso: Efficient Time Series Foundation Models for Zero-shot Forecasting’, представлен новый подход к созданию эффективных моделей, способных к прогнозированию временных рядов без предварительного обучения на целевых данных. Показано, что использование гибридных архитектур, сочетающих длинные свертки и слои DeltaNet, позволяет достичь сопоставимой производительности с более крупными моделями на основе трансформеров, при этом сокращая количество параметров более чем в сто раз. Возможно ли дальнейшее повышение эффективности и точности прогнозирования временных рядов за счет инновационных архитектур и стратегий аугментации данных?
Пределы Традиционного Прогнозирования Временных Рядов
Традиционные статистические модели, такие как Box-Jenkins, несмотря на свою историческую значимость, демонстрируют ограниченные возможности при анализе временных рядов, характеризующихся сложными и нелинейными зависимостями. Эти модели, основанные на предположении о линейности и стационарности данных, часто не способны адекватно отразить реальные процессы, где взаимосвязи между прошлыми и будущими значениями могут быть нелинейными и изменяться во времени. В ситуациях, когда временной ряд подвержен влиянию нескольких факторов, взаимодействующих нелинейным образом, или когда присутствуют резкие изменения в динамике, точность прогнозов, построенных на основе моделей Box-Jenkins, существенно снижается. Это связано с тем, что они полагаются на ограниченный набор параметров и не способны эффективно моделировать сложные паттерны, присущие современным данным, что делает их менее пригодными для задач, требующих высокой точности и адаптивности.
Несмотря на то, что рекуррентные нейронные сети (RNN) и трансформеры демонстрируют улучшения в прогнозировании временных рядов по сравнению с традиционными моделями, они часто сталкиваются с трудностями при работе с долгосрочными зависимостями в данных. Проблема заключается в том, что информация о событиях, произошедших в отдаленном прошлом, может быть потеряна или искажена по мере распространения данных через множество слоев сети. Кроме того, вычислительная сложность этих моделей возрастает экспоненциально с увеличением длины прогнозируемого горизонта, что делает их непрактичными для задач, требующих прогнозирования на длительные периоды времени. Особенно остро эта проблема проявляется при обработке больших объемов данных, когда необходимость в масштабируемых и эффективных решениях становится критически важной.
Потребность в точных и масштабируемых решениях для прогнозирования временных рядов обусловила появление фундаментальных моделей, адаптированных для этой области. Традиционные методы, несмотря на свою устоявшуюся эффективность, часто оказываются неспособными справиться с растущими объемами данных и сложностью современных временных рядов. В ответ на этот вызов, исследователи обратились к принципам, успешно применяемым в обработке естественного языка, разработав модели, способные к самообучению на огромных массивах данных и эффективной экстраполяции прогнозов на длительные периоды. Эти фундаментальные модели, предварительно обученные на разнообразных временных рядах, позволяют значительно сократить время и ресурсы, необходимые для создания точных прогнозов в различных областях, от финансов и энергетики до логистики и здравоохранения. Такой подход открывает новые возможности для автоматизации процессов принятия решений и повышения эффективности планирования, обеспечивая более надежные и точные результаты даже в условиях высокой волатильности и неопределенности.
Появление Фундаментальных Моделей для Временных Рядов
В настоящее время наблюдается адаптация предварительно обученных базовых моделей (Foundation Models), созданных на обширных массивах данных, для задач анализа временных рядов. Этот подход открывает возможности для прогнозирования с нулевым обучением (zero-shot forecasting), когда модель, обученная на других данных, способна делать прогнозы для новых временных рядов без дополнительной настройки. Кроме того, базовые модели позволяют применять трансферное обучение (transfer learning), перенося знания, полученные на больших наборах временных рядов, на задачи с ограниченным объемом данных или специфическими характеристиками, что повышает точность и снижает потребность в больших объемах размеченных данных для каждой конкретной задачи.
Модели-основы для временных рядов (TSFM) представляют собой развитие подхода, используемого в моделях-основах общего назначения, но с акцентом на специфические особенности временных данных. В отличие от моделей, обученных на разнородных данных, TSFM предварительно обучаются на обширных наборах данных временных рядов, что позволяет им учитывать автокорреляцию, сезонность и тренды, характерные для таких данных. Это позволяет TSFM лучше адаптироваться к новым временным рядам и задачам прогнозирования, требуя меньше данных для тонкой настройки и обеспечивая более высокую точность по сравнению с моделями, не специализирующимися на временных данных. Ключевым отличием является архитектура и стратегии обучения, оптимизированные для обработки последовательных данных и извлечения полезной информации из временных зависимостей.
Декодер-ориентированные модели временных рядов (TSFM) становятся доминирующим подходом в прогнозировании, используя принципы генеративного моделирования. В отличие от традиционных методов, эти модели обучаются генерировать будущие значения временного ряда, а не просто предсказывать одно конкретное значение. Архитектура, основанная на декодерах, позволяет моделировать сложные зависимости во временных данных и адаптироваться к различным горизонтам прогнозирования. Такой подход обеспечивает гибкость в отношении длины прогнозируемого периода и позволяет учитывать неопределенность в данных, что приводит к повышению точности прогнозов, особенно в долгосрочной перспективе. Ключевым преимуществом является возможность моделировать вероятностные распределения будущих значений, предоставляя не только точечные прогнозы, но и информацию о связанных рисках и неопределенностях.
Представляем Reverso: Эффективную Архитектуру TSFM
Reverso представляет собой новую архитектуру TSFM (Temporal State-Space Model), разработанную для задач долгосрочного прогнозирования временных рядов. Ключевой особенностью Reverso является достижение баланса между точностью прогнозов и вычислительной эффективностью. В отличие от традиционных TSFM, требующих значительных вычислительных ресурсов, Reverso оптимизирован для снижения количества параметров без существенной потери в качестве прогнозов, что делает его применимым для задач, где важны как высокая точность, так и скорость обработки данных. Это достигается за счет использования специализированных слоев и техник оптимизации, направленных на эффективное моделирование временных зависимостей.
Архитектура Reverso использует комбинацию длинных сверток (long convolution) и слоя DeltaNet для эффективного захвата сложных временных зависимостей в данных. Длинные свертки позволяют модели учитывать более широкий контекст временного ряда, что важно для долгосрочного прогнозирования. Слой DeltaNet, в свою очередь, предназначен для моделирования изменений во временном ряду, фокусируясь на разностях между последовательными точками данных. Такой подход позволяет снизить количество параметров модели по сравнению с традиционными рекуррентными или трансформерными архитектурами, сохраняя при этом высокую точность прогнозирования за счет более эффективного извлечения и представления временных паттернов.
Для повышения устойчивости и обобщающей способности модели Reverso используются методы аугментации данных и генерации синтетических данных. Аугментация включает в себя применение различных преобразований к существующим данным временных рядов, таких как добавление шума, сдвиг во времени или изменение масштаба, что позволяет модели обучаться на более разнообразном наборе данных. Генерация синтетических данных подразумевает создание новых данных, имитирующих характеристики реальных временных рядов, с использованием статистических моделей или генеративных сетей. Комбинация этих подходов позволяет эффективно расширить обучающую выборку, снизить риск переобучения и повысить способность модели к обобщению на новые, ранее не встречавшиеся данные.
![Архитектура Reverso обрабатывает входную последовательность [latex]t \in \mathbb{R}^L[/latex] посредством проекционного слоя и [latex]n_{layers}[/latex] блоков смешивания последовательностей и каналов, чередуя длинные свёртки и DeltaNet для обработки размерности L и MLP-слои для обработки размерности d, что позволяет получить прогнозы [latex]\hat{y} \in \mathbb{R}^p[/latex].](https://arxiv.org/html/2602.17634v1/figures/new_arch.png)
Строгая Оценка и Бенчмарк Производительности
Эффективность Reverso была тщательно оценена на наборе данных GiftEval, а также на эталонных тестах LTSF и TSLib. Результаты показали, что модель достигает показателя MASE (Mean Absolute Scaled Error) равного 0.711 на GiftEval, что свидетельствует о высокой точности прогнозирования. Данный показатель, полученный в ходе всестороннего тестирования, подтверждает способность Reverso к эффективному решению задач прогнозирования временных рядов и демонстрирует её конкурентоспособность в сравнении с другими существующими моделями.
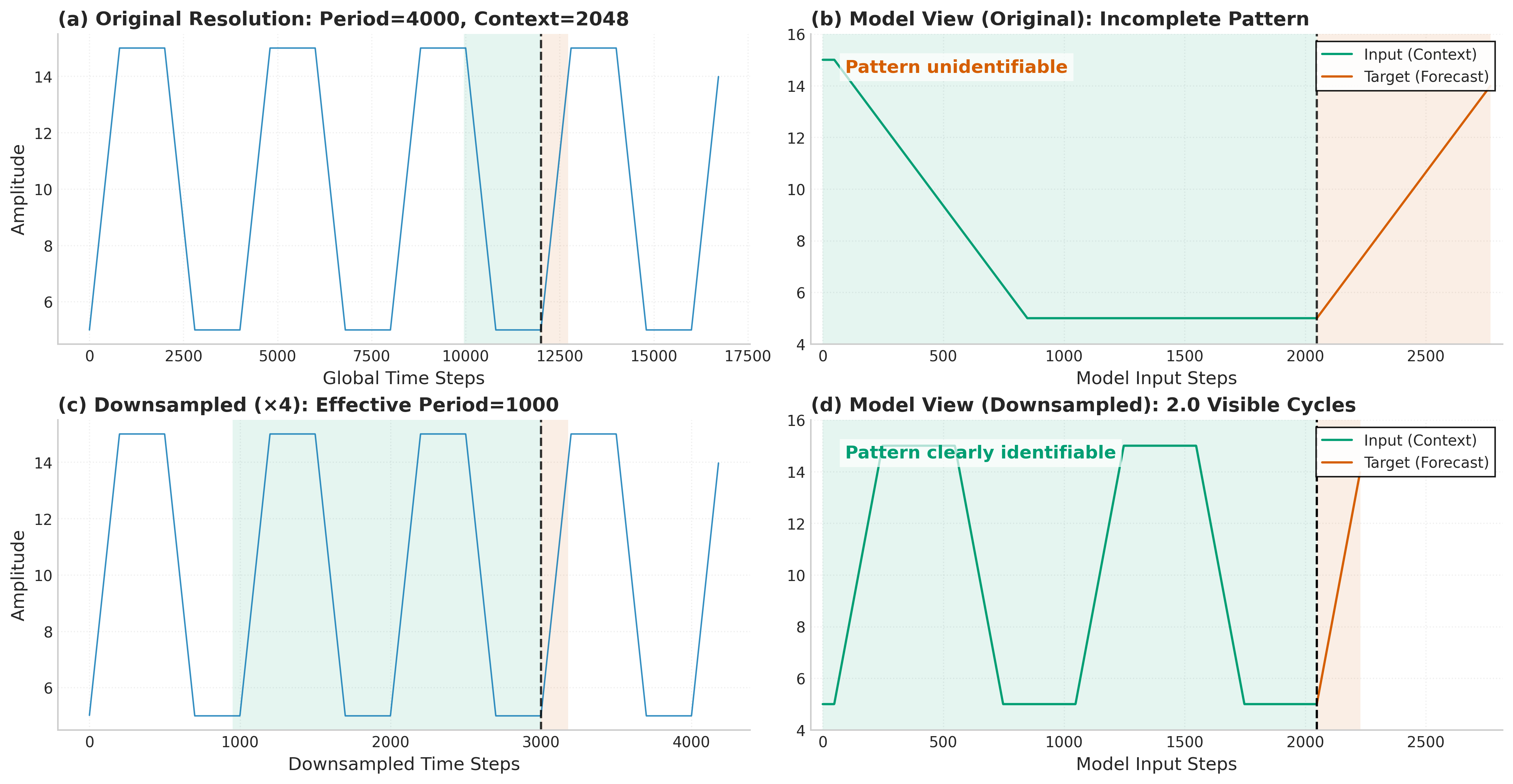
Для повышения эффективности работы модели Reverso применялись методы понижающей дискретизации (downsampling). Этот подход позволил оптимизировать вычислительные затраты без ущерба для точности прогнозирования. В ходе экспериментов было установлено, что снижение частоты дискретизации временных рядов не приводит к существенному ухудшению показателей качества, а в некоторых случаях даже способствует повышению устойчивости модели к шумам и выбросам. Использование таких техник позволяет Reverso демонстрировать конкурентоспособные результаты, требуя при этом значительно меньше вычислительных ресурсов по сравнению с другими современными моделями анализа временных рядов.
Исследование показало, что Reverso демонстрирует сопоставимую эффективность с передовыми моделями, при этом значительно уступая им в размере. Важно отметить, что модели Reverso варьируются от 0.2 миллиона до 2.6 миллиона параметров, что существенно меньше, чем у аналогичных разработок. Результаты, полученные на бенчмарке LTSF, подтверждают, что уменьшение количества параметров не приводит к снижению качества прогнозирования, а позволяет повысить вычислительную эффективность и сделать модель более доступной для использования на устройствах с ограниченными ресурсами. Это открывает перспективы для применения Reverso в различных областях, где важны как точность, так и скорость работы.
![Эксперименты показывают, что точность прогнозирования [latex]MAE[/latex] для модели LTSF улучшается с увеличением числа параметров на наборе данных, включающем ETTh1, ETTh2, ETTm1, ETTm2, данные об электроэнергии и погоде, при этом для моделей с неполными результатами использовались значения, полученные для лучших существующих моделей на соответствующих наборах данных.](https://arxiv.org/html/2602.17634v1/figures/ltsf_pareto_mae.png)
Исследование, представленное в данной работе, демонстрирует, что даже небольшие модели, такие как Reverso, способны достигать конкурентоспособных результатов в прогнозировании временных рядов, используя эффективные архитектурные решения и стратегии аугментации данных. Этот подход особенно интересен, поскольку позволяет обойтись без трудоемкой адаптации к конкретным задачам. Г.Х. Харди заметил: «Математика — это не набор готовых ответов, а способ задавать правильные вопросы». Подобно этому, Reverso не стремится предоставить универсальное решение, а предлагает гибкую основу для исследования возможностей прогнозирования, позволяя задавать новые вопросы и адаптироваться к различным временным рядам, эффективно используя существующие данные и архитектурные решения, такие как DeltaNet и длинные свертки.
Что дальше?
Представленная работа, словно отшлифованный механизм, демонстрирует эффективность малых моделей в предсказании временных рядов. Однако, каждый сбой — это сигнал времени. Неизбежно возникает вопрос: достаточно ли нам лишь точного предсказания? Или задача заключается в понимании закономерностей старения самой системы, которую мы моделируем? Успех Reverso в условиях нулевой адаптации лишь подчеркивает хрупкость понятия «универсальности». Модель, лишенная памяти о прошлом, полагается на общие принципы, игнорируя уникальность каждого временного ряда.
Очевидным направлением дальнейших исследований представляется не просто увеличение объема данных для обучения, а разработка методов «археологии» временных рядов — выявление скрытых слоев информации, отражающих историю системы. Рефакторинг — это диалог с прошлым. Необходимо искать способы встраивания контекстной информации, позволяющей модели адаптироваться к специфическим особенностям каждого ряда, не прибегая к полной переобучаемости.
В конечном счете, цель не в создании идеального предсказателя, а в формировании модели, способной достойно стареть вместе с данными, отражая их эволюцию и предвосхищая не только ближайшее будущее, но и долгосрочные тенденции. Время — не метрика, а среда, и истинная ценность модели заключается в ее способности существовать в этой среде, сохраняя свою функциональность и актуальность.
Оригинал статьи: https://arxiv.org/pdf/2602.17634.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Т-Технологии акции прогноз. Цена T
- Российский рынок: отчетность компаний, дивиденды и нефтяной фактор – что ждет инвесторов? (28.04.2026 15:32)
- Татнефть префы прогноз. Цена TATNP
- ВСМПО-АВИСМА акции прогноз. Цена VSMO
- ТГК-14 акции прогноз. Цена TGKN
- SOL/USD
- ТГК-1 акции прогноз. Цена TGKA
- Российский рынок: между геополитикой, дивидендами и кризисом отдельных компаний (14.04.2026 11:32)
- Группа ЛСР акции прогноз. Цена LSRG
2026-02-22 17:21