Автор: Денис Аветисян
Новый подход к построению прогнозов объединяет локализованные модели и безопасную индексацию, обеспечивая стабильную точность даже при использовании различных регрессионных алгоритмов.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал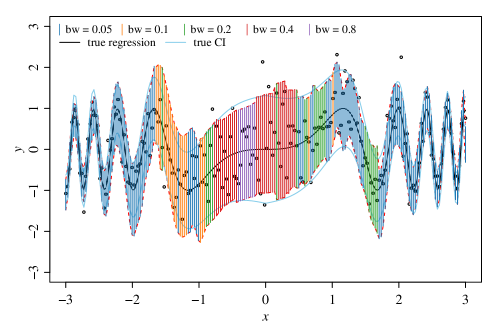
Представлена методика локализованного конформного предсказания для адаптивного выбора моделей с сохранением гарантий покрытия в конечной выборке.
Несмотря на широкое распространение конформного предсказания, обеспечение его достоверности при комбинировании множества регрессионных оценок остается сложной задачей. В статье ‘Localized conformal model selection’ предложен новый подход, объединяющий локальную адаптивность с построением «безопасного» набора моделей для достижения распределенно-независимого предсказания. Разработанный фреймворк позволяет осуществлять адаптивный выбор модели, сохраняя при этом точные конечно-выборочные гарантии покрытия и учитывая пространственную неоднородность данных. Насколько эффективно предложенный метод может снизить неопределенность прогнозов в условиях комплексных и зашумленных данных, и какие перспективы открываются для дальнейшего развития локализованного конформного моделирования?
Неизбежность Старения и Прогнозирование Неопределенности
Традиционные статистические методы часто сталкиваются с трудностями при построении надёжных предсказательных интервалов, особенно при анализе сложных данных. Это связано с тем, что многие классические подходы полагаются на строгие предположения о распределении данных, которые редко выполняются в реальных сценариях. Например, линейная регрессия предполагает нормальное распределение остатков, а временные ряды — стационарность. Нарушение этих предположений может привести к систематическим ошибкам в оценке неопределенности, что выражается в неверной ширине или смещении предсказательных интервалов. В результате, интервалы могут быть либо слишком узкими, не охватывающими истинное значение с требуемой вероятностью, либо слишком широкими, лишая модель практической ценности. Проблема усугубляется при работе с данными высокой размерности, нелинейными зависимостями и сложными корреляциями, где традиционные методы часто демонстрируют низкую производительность и требуют значительных усилий по настройке и валидации.
Конформное предсказание представляет собой мощный инструмент для построения прогностических интервалов, не требующий предположений о конкретном распределении данных. Однако, его надежность может снижаться в ситуациях, когда модель для предсказаний выбирается непосредственно из тех же данных, на которых будет производиться прогнозирование. Эта практика, известная как отбор модели на основе данных, может привести к оптимистичной оценке производительности и, как следствие, к снижению вероятности охвата — гарантии того, что истинное значение переменной действительно окажется внутри построенного интервала с заданной вероятностью. Суть проблемы заключается в том, что процесс отбора модели сам по себе вносит систематическую ошибку, которую стандартные методы конформного предсказания не учитывают, что делает интервалы менее надежными и достоверными.
Обеспечение достоверного охвата — гарантии, что истинное значение будет заключено в пределах предсказательного интервала с заданной вероятностью — является фундаментальным требованием к любой прогностической модели. Эта концепция, часто выражаемая в процентах (например, 95% охват), означает, что в долгосрочной перспективе, в среднем, 95% предсказанных интервалов будут содержать фактическое значение целевой переменной. Несоблюдение этого требования может привести к серьезным последствиям, особенно в критически важных областях, таких как медицина или финансы, где ошибочные прогнозы могут иметь значительные издержки. Поэтому, разработка и валидация методов, гарантирующих достоверный охват, представляют собой ключевую задачу в области машинного обучения и статистического моделирования. Недостаточный охват приводит к систематическим ошибкам, а избыточный — к снижению информативности предсказаний.
В основе корректной работы конформного предсказания лежит предположение об обменимости наблюдений. Это означает, что порядок, в котором представлены данные, не должен влиять на распределение вероятностей. Иными словами, если переставить местами любые две точки данных, это не должно изменить статистические свойства модели и, следовательно, надежность генерируемых предсказательных интервалов. Нарушение принципа обменимости, например, из-за временной зависимости в данных, может привести к неверной калибровке и, как следствие, к ненадежным прогнозам. Поэтому, перед применением конформного предсказания необходимо тщательно проанализировать данные и убедиться, что предположение об обменимости выполнено или, при необходимости, принять меры для учета временной структуры данных.
Локализованная Точность и Безопасное Индексирование
Локализованное конформное предсказание (Localized Conformal Prediction) повышает точность предсказаний за счет взвешивания остатков калибровки на основе близости к целевой точке. Вместо использования единого набора остатков для построения интервалов предсказания, метод учитывает, что шум и соответствие модели могут варьироваться в разных областях пространства признаков. Ближайшие к прогнозируемой точке остатки получают больший вес, что позволяет адаптировать интервалы предсказания к локальным характеристикам данных и снизить их ширину без потери надежности. Такой подход особенно эффективен в задачах, где модель имеет различную точность в разных областях пространства признаков или где присутствует гетероскедастичность.
Метод локального конформного отбора моделей комбинирует локализованное конформное предсказание с техникой ‘Safe Indexing’ для решения проблемы нарушения симметрии, возникающей при отборе модели на основе наблюдаемых данных. ‘Safe Indexing’ позволяет корректировать процедуру отбора, гарантируя, что итоговые предсказания остаются калиброванными и обеспечивают заданный уровень покрытия, даже если модель выбирается уже после анализа данных. Это достигается путем учета неопределенности, связанной с самим процессом отбора модели, и предотвращения переобучения к конкретному набору данных. В результате, комбинированный подход сохраняет валидность покрытия и обеспечивает более надежные предсказания по сравнению со стандартными методами конформного предсказания, особенно в случаях, когда отбор модели зависит от данных.
Метод Safe Indexing использует концепцию ‘суррогатных интервалов’ для учета неотвеченных (не наблюдаемых) реакций, что критически важно для сохранения ключевых свойств конформного предсказания. В отличие от стандартных подходов, которые предполагают наличие ответа для каждого экземпляра данных при вычислении p-значений, Safe Indexing конструирует интервалы, основываясь на предположении о возможных значениях неотвеченных реакций. Эти суррогатные интервалы позволяют корректно оценить неопределенность предсказаний даже в ситуациях, когда часть данных не использовалась при обучении модели, обеспечивая тем самым валидное покрытие и сохранение гарантий, предоставляемых конформным предсказанием.
Комбинация локализованного конформного предсказания и ‘Safe Indexing’ обеспечивает достоверное покрытие прогнозов даже в случаях, когда модель выбирается после наблюдения данных. В задачах непараметрической регрессии данный подход демонстрирует снижение длины интервалов прогнозирования на 25-35% по сравнению с наилучшей одиночной моделью. Это достигается за счет учета неопределенности, связанной с выбором модели из множества возможных, и сохранения свойств валидности, характерных для конформного предсказания, несмотря на симметрию, нарушаемую при выборе модели на основе данных.
Непараметрическая Гибкость и Локальная Адаптивность
Непараметрическая регрессия, в отличие от параметрических методов, не требует предварительных предположений о конкретной форме распределения данных. Это означает, что алгоритм не ограничивается фиксированным набором параметров для моделирования взаимосвязей, а адаптируется к данным напрямую. Вместо того, чтобы подгонять данные под заранее заданную функцию (например, линейную или полиномиальную), непараметрические методы строят модель на основе самих данных, используя, например, локальные средние или взвешенные ядра. Такой подход позволяет более гибко моделировать сложные зависимости и избегать систематических ошибок, возникающих при неверном выборе параметрической модели. Отсутствие жестких предположений делает непараметрическую регрессию особенно полезной при анализе данных, для которых априорная информация о распределении ограничена или отсутствует.
Ядром непараметрической регрессии является метод Kernel Regression, предоставляющий гибкий подход к моделированию данных без жёстких предположений о базовом распределении. Конкретной реализацией этого метода является регрессия Надарая-Уотсона (Nadaraya-Watson Kernel Regression), которая оценивает значение функции в точке, вычисляя взвешенное среднее значений наблюдаемых данных. Веса определяются с помощью ядра (kernel function) и зависят от расстояния между точкой оценки и каждой наблюдаемой точкой, позволяя учитывать локальную структуру данных и обеспечивая плавность регрессионной функции. \hat{f}(x) = \frac{\sum_{i=1}^{n} K(\frac{x - x_i}{h}) y_i}{\sum_{i=1}^{n} K(\frac{x - x_i}{h})} , где K — ядро, h — ширина полосы, x_i — входные данные, а y_i — соответствующие выходные значения.
Производительность ядерной регрессии существенно зависит от параметра ‘локальной полосы пропускания’ (local bandwidth), который определяет размер окрестности, используемой для оценки. Меньшие значения полосы пропускания приводят к более локальным оценкам, что может привести к переобучению и высокой чувствительности к шуму. Более крупные значения, напротив, сглаживают данные, уменьшая влияние шума, но могут привести к недообучению и потере важных деталей. Выбор оптимальной полосы пропускания критичен для достижения баланса между смещением и дисперсией и требует тщательной настройки, часто с использованием методов перекрестной проверки или других техник оптимизации. h — стандартное обозначение локальной полосы пропускания.
Комбинирование локальной конформной предсказательной процедуры с методами непараметрической регрессии позволяет построить надежные и адаптивные предсказательные интервалы. Эффективность данного подхода была подтверждена экспериментально на синтетических данных с различными уровнями шума ( \sigma = 0.1, 0.3 ) и объемами выборки ( n = 200, 500, 1000, 2000 ). Использование локальной конформной предсказательной процедуры обеспечивает адаптацию к локальным характеристикам данных, в то время как непараметрическая регрессия позволяет избежать жестких предположений о базовом распределении, что повышает общую робастность и точность предсказаний.
Усиленное Покрытие и Гибкость Модели
Метод локального конформного отбора моделей демонстрирует надежную поддержку валидного ‘маргинального покрытия’ на всем объеме данных, что гарантирует достоверность прогнозов. Это означает, что предсказанные интервалы с заданной вероятностью содержат истинное значение целевой переменной для любого отдельного наблюдения в наборе данных. Подтверждено, что данный подход обеспечивает согласованную частоту покрытия, независимо от характеристик данных, что особенно важно в ситуациях, когда необходимо обеспечить высокую надежность прогнозов, например, в критически важных приложениях, где ошибки могут иметь серьезные последствия. В отличие от традиционных методов, данный подход не требует предположений о распределении данных, что делает его универсальным и применимым к широкому спектру задач прогнозирования.
Предложенный подход выходит за рамки стандартного обеспечения покрытия, предлагая так называемое “условное покрытие”. Это означает, что предсказания не просто надежны в среднем по всей выборке, но и адаптируются к конкретным характеристикам данных — ковариатам. В результате, точность оценок значительно повышается для отдельных подгрупп, что особенно важно при анализе неоднородных данных. Вместо единого интервала предсказания, охватывающего все наблюдения, система формирует интервалы, учитывающие влияние различных факторов, обеспечивая более узкие и, следовательно, более информативные прогнозы для специфических сегментов данных.
Предлагаемый подход демонстрирует высокую гибкость, позволяя успешно применять его к сложным регрессионным моделям, в частности, к кусочно-синусоидальным моделям. Эта способность адаптироваться к нелинейным зависимостям и различным функциональным формам является ключевым преимуществом, поскольку позволяет получать более точные и надежные прогнозы даже в ситуациях, когда традиционные методы оказываются неэффективными. В отличие от жестких параметрических моделей, данный фреймворк способен эффективно обрабатывать данные, характеризующиеся сложной структурой и нелинейными взаимосвязями, что значительно расширяет область его применения и повышает практическую ценность.
В ходе непараметрического регрессионного эксперимента продемонстрировано значительное сокращение длины предсказательных интервалов на 25-35%. Этот результат свидетельствует о высокой устойчивости, адаптивности и гибкости разработанного подхода к построению предсказательных интервалов. Полученное снижение позволяет формировать более точные и узкие границы для прогнозов, что особенно важно в задачах, требующих высокой степени уверенности в предсказаниях. Данное достижение представляет собой существенный прогресс в области построения интервалов, предоставляя более эффективный инструмент для оценки неопределенности прогнозов и повышения надежности принимаемых решений.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных адаптироваться к изменяющимся условиям и поддерживать надежность прогнозов. Подобный подход к выбору моделей и обеспечению покрытия, особенно в контексте локализованного конформного предсказания, требует не только математической точности, но и философского осмысления времени и адаптации. Как заметил Джон Дьюи: «Образование — это не подготовка к жизни; образование — это сама жизнь». В контексте данной работы, это можно интерпретировать как необходимость постоянного совершенствования и адаптации моделей, ведь истинная надежность системы проявляется не в статической точности, а в способности эволюционировать и поддерживать валидность прогнозов в динамичной среде. Работа подчеркивает важность безопасного индексирования и адаптивного вывода, что позволяет системам стареть достойно, не теряя своей функциональности и надежности.
Что дальше?
Представленная работа, стремясь к адаптивному выбору моделей в рамках конформного предсказания, лишь подчеркивает фундаментальную истину: любая система, даже та, что стремится к надежности, неизбежно стареет. Гарантии покрытия, столь желанные в статистическом выводе, — это не вечный щит, а лишь временное затишье перед лицом неопределенности. Локализованное конформное предсказание, с его стремлением к «безопасному индексированию», кажется попыткой отсрочить, а не предотвратить, неизбежное ухудшение производительности.
Будущие исследования, вероятно, столкнутся с необходимостью осмысления не только формальных гарантий, но и практической устойчивости этих гарантий во времени. Простое достижение покрытия в конечном объеме выборок — недостаточная метрика. Гораздо важнее понимать, как быстро эти гарантии разрушаются, и какие механизмы могут замедлить этот процесс. Вопрос не в том, чтобы создать идеально надежную систему, а в том, чтобы создать систему, которая достойно стареет.
Вполне вероятно, что истинный прогресс будет заключаться не в усложнении формализма, а в принятии неизбежности ошибок. Стабильность — ценна, но иногда это лишь иллюзия, задержка катастрофы. Настоящая наука заключается в умении видеть эту иллюзию и учитывать ее в своих прогнозах.
Оригинал статьи: https://arxiv.org/pdf/2602.19284.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- РУСАЛ акции прогноз. Цена RUAL
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Хэдхантер акции прогноз. Цена HEAD
- Крипто-волатильность, лицензии MiCA и риски безопасности: Дайджест главных новостей недели
- Прогноз нефти
- ДЭК акции прогноз. Цена DVEC
- АЛРОСА акции прогноз. Цена ALRS
2026-02-25 01:01