Автор: Денис Аветисян
Исследователи предлагают инновационный алгоритм, позволяющий агентам сохранять и использовать неоптимальные действия для более эффективной адаптации к динамично меняющимся условиям.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![В предложенной структуре S2Q каждая подсеть [latex]Q^{sub,k}[/latex] передаёт набор оптимальных действий [latex]\mathcal{A}^{k}[/latex], сформированных на основе опыта всех предыдущих подсетей, в то время как следующая подсеть [latex]Q^{sub,k+1}[/latex] обучается целевой функции [latex]Q^{\*}[/latex] с одновременным подавлением Q-значений действий, уже включенных в [latex]\mathcal{A}^{k}[/latex].](https://arxiv.org/html/2602.17062v1/x2.png)
Представлен алгоритм Successive Sub-value Q-learning (S2Q), повышающий эффективность исследования и адаптации в многоагентном обучении с централизованным обучением и децентрализованным выполнением.
В задачах кооперативного многоагентного обучения с подкреплением (MARL) достижение оптимальной политики часто затруднено из-за неспособности адаптироваться к меняющимся условиям среды. В данной работе, посвященной теме ‘Retaining Suboptimal Actions to Follow Shifting Optima in Multi-Agent Reinforcement Learning’, предлагается новый подход Successive Sub-value Q-learning (S2Q), который позволяет сохранять альтернативные, субоптимальные действия, обеспечивая более эффективное исследование пространства состояний и быструю адаптацию к динамичным средам. Использование нескольких подфункций ценности позволяет S2Q превосходить существующие MARL алгоритмы в сложных задачах, демонстрируя улучшенную производительность и адаптивность. Сможет ли предложенный подход стать основой для разработки более гибких и надежных систем MARL в реальных приложениях?
Многоагентные системы: вызов сложности и неопределенности
Многие задачи, возникающие в реальном мире — от управления транспортными потоками и роботизированными складами до координации поисково-спасательных операций и распределения ресурсов в энергетических сетях — требуют согласованных действий множества независимых агентов. Сложность заключается в том, что каждый агент обладает лишь частичной информацией об окружающей среде и действиях других участников, а их совместное поведение может приводить к неожиданным и непредсказуемым результатам. Эффективное решение таких проблем требует разработки новых подходов, учитывающих не только индивидуальные цели агентов, но и необходимость координации, коммуникации и адаптации к изменяющимся условиям, что представляет собой значительный вызов для современных систем искусственного интеллекта и теории управления.
Традиционные алгоритмы обучения с подкреплением, успешно применяемые для управления одиночным агентом, сталкиваются с существенными трудностями в децентрализованных системах. Проблема заключается в том, что каждый агент обладает лишь частичной информацией об окружающей среде и действиях других агентов. В отличие от ситуаций, где агент имеет полное представление о состоянии системы, в многоагентном окружении необходимо учитывать неопределенность, вызванную неполнотой данных. Это приводит к тому, что оптимальные стратегии, разработанные для одиночного агента, оказываются неэффективными или вовсе неприменимыми. Агенты вынуждены принимать решения, основываясь на неполной картине мира, что значительно усложняет процесс обучения и требует разработки новых подходов, учитывающих взаимодействие и неопределенность в децентрализованных системах.
Для адекватного моделирования сложных взаимодействий в многоагентных системах, где каждый агент обладает лишь частичной информацией об окружающей среде и действиях других агентов, применяются специализированные математические фреймворки, такие как Децентрализованные Частично Наблюдаемые Марковские Процессы Принятия Решений (DecPOMDP). DecPOMDP позволяют формально описать состояние системы, действия каждого агента, вероятности переходов между состояниями и получаемые награды, учитывая при этом неопределенность и децентрализованный характер информации. В отличие от классических Марковских Процессов Принятия Решений, DecPOMDP оперируют не полным состоянием системы, а распределением вероятностей по всем возможным состояниям, учитывая историю наблюдений каждого агента. Это позволяет разрабатывать алгоритмы, способные принимать оптимальные решения в условиях неполной информации и координировать действия множества агентов для достижения общей цели, несмотря на ограничения в коммуникации и восприятии.
![Эксперименты показали, что алгоритмы декомпозиции ценностей, такие как QMIX, WQMIX и S2Q (при [latex]K=2[/latex]), ограничены в способности эффективно обучаться в матричных играх, что демонстрируется на реальной матрице выигрышей.](https://arxiv.org/html/2602.17062v1/x1.png)
Централизованное обучение, децентрализованное исполнение: путь к масштабируемости
Централизованное обучение с децентрализованным выполнением (CTDE) представляет собой перспективный подход в обучении многоагентных систем. В отличие от традиционных методов, где каждый агент обучается независимо или с полным глобальным контролем, CTDE позволяет агентам обучаться, используя глобальную информацию для координации и улучшения стратегий, однако во время выполнения каждый агент действует автономно, основываясь на локальных наблюдениях. Это сочетание позволяет масштабировать обучение на более сложные задачи и повышает адаптивность системы к изменяющимся условиям, поскольку агенты не зависят от централизованного управления во время работы. CTDE особенно полезен в сценариях, где коммуникация ограничена или невозможна во время выполнения, а также для обучения в динамических средах.
Парадигма централизованного обучения и децентрализованного выполнения (CTDE) использует глобальную информацию в процессе обучения для координации действий агентов, однако позволяет каждому агенту действовать независимо во время выполнения. Это обеспечивает масштабируемость, так как агенты не нуждаются в постоянном обмене информацией во время работы, и повышает адаптивность системы к изменяющимся условиям. Использование глобального сигнала во время обучения позволяет агентам выучить более эффективные стратегии, в то время как децентрализованное выполнение снижает вычислительные затраты и задержки, возникающие при централизованном управлении.
Алгоритм QMIX является примером парадигмы централизованного обучения с децентрализованным выполнением, реализуя объединение оценок полезности (Q-values) отдельных агентов в единую функцию оценки совместных действий. Это достигается посредством использования монотонной смешивающей сети, которая комбинирует индивидуальные Q-values, гарантируя, что общая оценка не может быть меньше, чем оценка лучшего индивидуального действия. При этом, процесс принятия решений каждым агентом осуществляется независимо во время выполнения, основываясь на его собственной оценке, а глобальная оценка используется исключительно на этапе обучения для улучшения координации и общей эффективности работы всей системы. Ограничение Individual-Global-Max (IGM) гарантирует, что глобальный максимум совместной функции полезности всегда соответствует максимуму по индивидуальным действиям агентов, что способствует стабильности обучения и обеспечивает оптимальное поведение.
![Тепловая карта демонстрирует распределение совместных действий в трех сценариях: S2Q с [latex]K=2, T=1.0[/latex], S2Q с [latex]K=2, T=0.5[/latex] и ϵ-жадным подходом для каждого агента.](https://arxiv.org/html/2602.17062v1/x12.png)
Successive Sub-value Q-learning: выявление оптимальных и субоптимальных стратегий
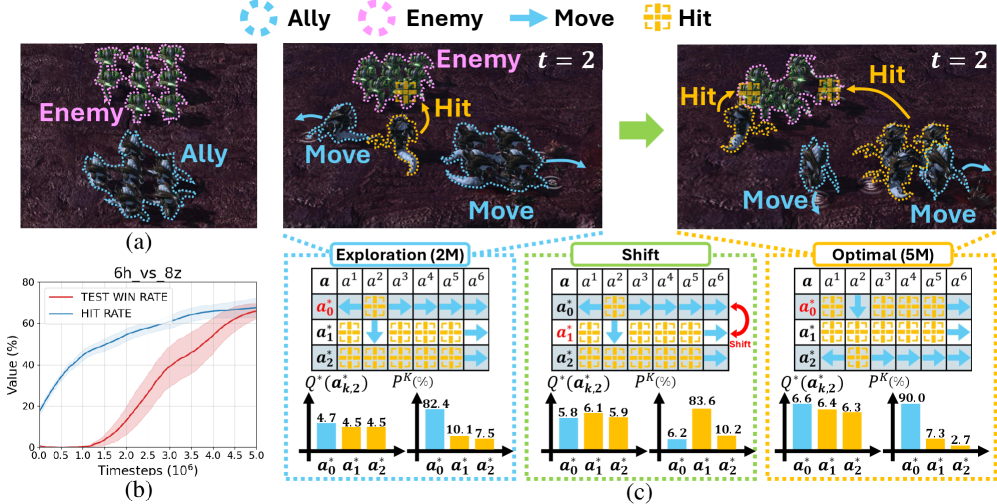
Метод Successive Sub-value Q-learning (S2Q) преодолевает ограничения существующих алгоритмов обучения с подкреплением за счет обучения множества подфункций ценности. Традиционные методы часто сталкиваются с трудностями при моделировании сложных многоагентных сред из-за неспособности эффективно учитывать взаимодействия между агентами и разнообразие возможных стратегий. S2Q решает эту проблему, используя несколько функций ценности, каждая из которых представляет отдельную стратегию или подцель. Это позволяет алгоритму более точно оценивать долгосрочные последствия действий агентов и находить оптимальные или субоптимальные решения, учитывающие сложные зависимости в среде.
Алгоритм Successive Sub-value Q-learning (S2Q) способен выявлять различные субоптимальные действия, что критически важно для улучшения координации и общей производительности в сложных многоагентных средах. В отличие от методов, рассматривающих только оптимальные стратегии, S2Q анализирует и использует альтернативные действия, позволяя агентам адаптироваться к меняющимся условиям и эффективно взаимодействовать друг с другом. Идентификация этих субоптимальных стратегий позволяет агентам избегать ситуаций, где оптимальное действие недоступно или неэффективно, и находить приемлемые решения для поддержания стабильной и успешной работы в команде. Это особенно важно в средах, где неопределенность и конкуренция являются ключевыми факторами.
В Successive Sub-value Q-learning (S2Q) используется LatentRepresentation — скрытое представление состояния среды, полученное посредством архитектуры EncoderDecoder. Encoder преобразует исходные наблюдения в компактный вектор скрытого состояния, который содержит наиболее важную информацию для принятия решений. Decoder восстанавливает исходные наблюдения из этого вектора, обеспечивая сохранение необходимой информации. Для выбора действий S2Q применяет SoftmaxPolicy, преобразующую значения Q-функции в вероятностное распределение по доступным действиям, что позволяет алгоритму исследовать различные стратегии и избегать преждевременной конвергенции к локальному оптимуму. Использование LatentRepresentation уменьшает размерность входных данных, упрощая процесс обучения и улучшая обобщающую способность, а SoftmaxPolicy обеспечивает сбалансированное исследование и использование знаний.
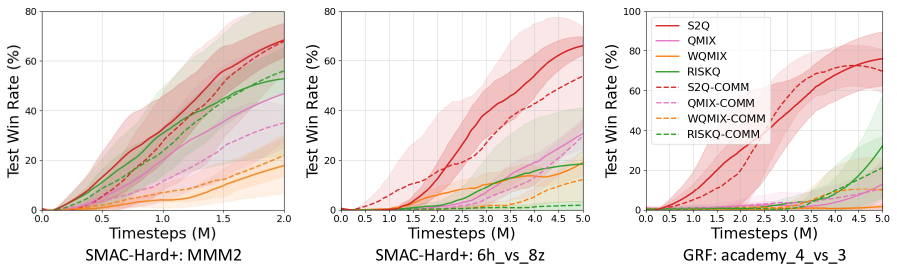
Метод Successive Sub-value Q-learning (S2Q) демонстрирует существенное превосходство над современными алгоритмами многоагентного обучения с подкреплением (MARL) на сложных тестовых средах, таких как SMAC и GRF. Ключевым отличием является способность S2Q идентифицировать и использовать неоптимальные действия, что позволяет улучшить координацию агентов и добиться более высоких показателей побед. В ходе экспериментов было зафиксировано, что S2Q стабильно превосходит базовые алгоритмы, обеспечивая значимый прирост эффективности в различных сценариях, что подтверждается более высокими винрейтами по сравнению с другими передовыми MARL-методами.
В ходе экспериментов на бенчмарке SMAC MMM2, Successive Sub-value Q-learning (S2Q) продемонстрировал сокращение времени обучения до достижения 50% показателя побед на 8.4% по сравнению с алгоритмом QMIX. При этом, использование S2Q повлекло за собой увеличение потребления памяти GPU примерно на 248 MB. Данный компромисс между скоростью обучения и потреблением ресурсов был признан целесообразным, учитывая достигнутое улучшение производительности на указанном бенчмарке.
В соревновании SMACv2 zerg_5_vs_5 алгоритм Successive Sub-value Q-learning (S2Q) продемонстрировал значительное превосходство над другими передовыми алгоритмами многоагентного обучения с подкреплением (MARL). Экспериментальные данные показывают, что S2Q превосходит существующие state-of-the-art решения по показателю win rate, обеспечивая более стабильные и эффективные результаты в сложных многоагентных сценариях, характерных для данного бенчмарка. Конкретные цифры, подтверждающие превосходство S2Q, представлены в сравнительных таблицах и графиках, демонстрирующих его способность к более эффективной координации агентов и адаптации к динамически меняющейся игровой среде.
Уточнение подхода: адаптивное обучение и повышение производительности
В системах многоагентного обучения с подкреплением (MARL) эффективная координация напрямую зависит от способности агентов обмениваться информацией. Отсутствие коммуникации приводит к субоптимальным решениям, поскольку каждый агент действует, основываясь лишь на собственном, неполном представлении об окружающей среде. Исследования показывают, что возможность обмена сообщениями, даже в простейшей форме, позволяет агентам согласовывать свои действия, избегать конфликтов и совместно достигать поставленных целей. Такой обмен данными позволяет каждому агенту учитывать намерения и действия других, формируя более полную картину ситуации и повышая общую эффективность всей системы. Эффективные протоколы коммуникации, в свою очередь, позволяют снизить неопределенность и ускорить процесс обучения, что особенно важно в сложных динамических средах.
Метод Weighted QMIX представляет собой усовершенствование алгоритма QMIX, направленное на повышение эффективности обучения в системах многоагентного обучения с подкреплением. В отличие от стандартного QMIX, который использует фиксированные веса для агрегации оценок Q-values, Weighted QMIX динамически адаптирует эти веса, основываясь на величине ошибки временных различий (TD-error). Такой подход позволяет более эффективно распространять информацию об ошибках обучения между агентами, что приводит к ускорению сходимости и повышению стабильности процесса обучения. Адаптивное взвешивание TD-error позволяет системе более точно оценивать ценность совместных действий агентов, что особенно важно в сложных средах, где взаимодействие между агентами играет ключевую роль. В результате, Weighted QMIX демонстрирует улучшенные показатели производительности и надежности в задачах, требующих скоординированного поведения множества агентов.
Достижения в области обучения с подкреплением для многоагентных систем открывают новые перспективы для решения сложных задач, возникающих в реальном мире. Способность агентов эффективно взаимодействовать и адаптироваться к изменяющимся условиям позволяет создавать системы, превосходящие традиционные подходы в таких областях, как управление транспортными потоками, координация роботизированных групп и оптимизация распределенных ресурсов. Развитие алгоритмов, обеспечивающих стабильное и быстрое обучение, критически важно для внедрения этих технологий в практические приложения, где надежность и эффективность являются первостепенными требованиями. Перспективные исследования в данной области указывают на возможность создания интеллектуальных систем, способных решать задачи, ранее считавшиеся недоступными для автоматизации.
Исследование, представленное в данной работе, стремится к повышению эффективности обучения в многоагентных системах посредством отслеживания субоптимальных действий. Этот подход, основанный на алгоритме S2Q, позволяет агентам быстрее адаптироваться к изменяющимся условиям, что особенно важно в динамичных средах. В этом контексте уместно вспомнить слова Давида Гильберта: «В математике нет спектра. Есть только математика». Подобно этому, и в алгоритмах машинного обучения, стремление к математической чистоте и доказуемости принципов, как это демонстрирует S2Q с его декомпозицией ценностей, является ключом к созданию надежных и эффективных систем, способных к адаптации и обучению.
Куда двигаться дальше?
Без чёткого определения понятия «оптимальности» в контексте динамических многоагентных систем, любое усложнение алгоритма рискует стать лишь избыточным шумом. Представленный подход, хоть и демонстрирует улучшение в отслеживании субоптимальных действий, не решает фундаментальную проблему: как гарантированно отличать действительно полезное исследование пространства состояний от случайного блуждания? Необходимо разработать метрики, позволяющие оценивать «информативность» каждого субоптимального действия, а не просто его вклад в текущую награду.
Очевидным направлением является расширение формализма декомпозиции ценности. В текущем виде он предполагает некоторую степень независимости между агентами. Однако, в реальности, агенты часто взаимодействуют сложным образом, и их ценности взаимозависимы. Следует исследовать методы, позволяющие учитывать эти взаимосвязи, возможно, используя концепции теории игр или теории графов. Иначе говоря, требуется построение более элегантной и доказуемо корректной модели взаимодействия.
Наконец, стоит признать, что Successive Q-learning, как и большинство алгоритмов обучения с подкреплением, чувствителен к гиперпараметрам. Поиск оптимальных значений этих параметров требует значительных вычислительных ресурсов. Необходимо разработать методы автоматической настройки гиперпараметров, основанные на строгих математических принципах, а не на эмпирических наблюдениях. В противном случае, даже самый изящный алгоритм останется лишь недостижимым идеалом.
Оригинал статьи: https://arxiv.org/pdf/2602.17062.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- АЛРОСА акции прогноз. Цена ALRS
- Мечел акции прогноз. Цена MTLR
- Токенизация активов выходит на новый уровень: обзор Evergon v0.23 и перспективы рынка RWA (07.04.2026 22:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
- Группа Аренадата акции прогноз. Цена DATA
- Падение C3.ai на 33%: шанс или ловушка?
2026-02-21 01:07