Автор: Денис Аветисян
Новый подход к обучению роботов навигации позволяет им эффективно ориентироваться в сложных условиях, избегая столкновений без необходимости создания точных математических моделей окружения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
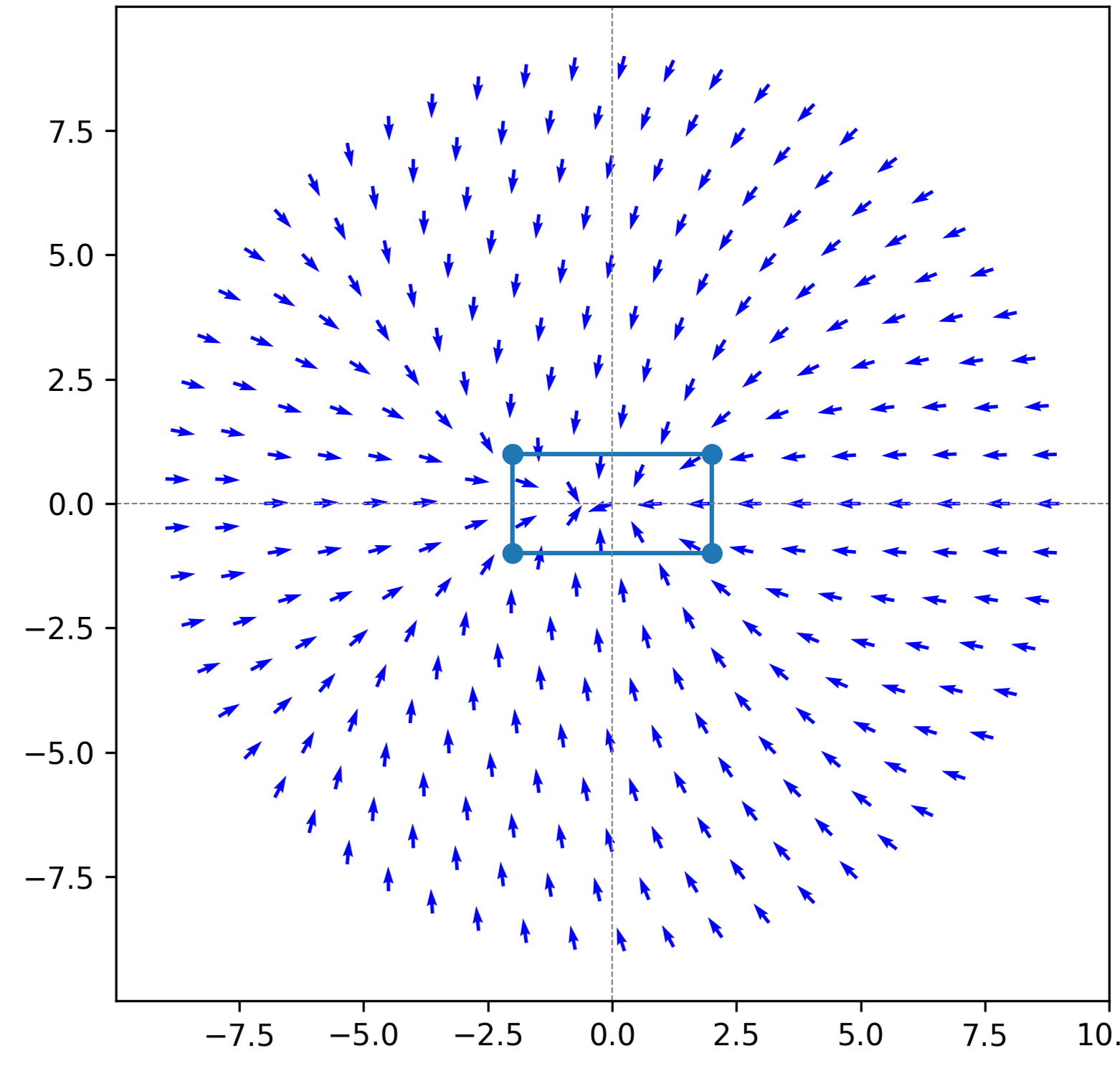
Бесплатный Телеграм канал![В типичном сценарии двумерной навигации, система определяет область допустимых состояний (отображенная пунктирной окружностью оранжевого цвета вокруг объекта, представленного синим прямоугольником), храня при этом значения [latex]\mu_{V}[/latex] и [latex]\mu_{u^{*}}[/latex] в виде синих точек в структуре [latex]X^{\sharp}[/latex], обеспечивая тем самым основу для анализа и оптимизации траектории.](https://arxiv.org/html/2602.12492v1/figs/Data_setup.png)
Предложен фреймворк обучения с подкреплением, объединяющий методы теории управления и обучение без моделей для безопасной и надежной навигации в системах с аффинным входом.
Автономная робототехника сталкивается с трудностями при навигации в сложных и динамичных реальных условиях из-за непредсказуемости окружающей среды. В данной работе, ‘Composable Model-Free RL for Navigation with Input-Affine Systems’, предлагается композируемый метод обучения с подкреплением без использования модели, который позволяет создавать отдельные модели для каждого элемента окружения и объединять их онлайн для достижения цели и избежания препятствий. Предложенный подход, основанный на решении уравнения Гамильтона-Якоби-Беллмана HJB и использовании квадратичной структуры функции преимущества, позволяет обучать стратегии управления без явного знания динамики системы. Может ли подобный композируемый подход стать эффективной альтернативой традиционным методам управления, основанным на функциях Лиапунова и барьерах, и обеспечить надежную навигацию в неизвестной среде?
Танцы на Лезвии: Вызов Безопасного и Адаптивного Управления
Традиционные методы управления зачастую оказываются неэффективными при работе со сложными, нелинейными системами и непредвиденными возмущениями. Эти системы, в отличие от линейных, характеризуются непропорциональной реакцией на входные сигналы, что делает прогнозирование и поддержание стабильности значительно более трудным. Например, в робототехнике или авиации, даже незначительные отклонения, усиленные нелинейностью системы, могут привести к потере управления. Кроме того, неожиданные внешние факторы — от порывов ветра до внезапных изменений нагрузки — представляют серьезную проблему для алгоритмов, рассчитанных на идеальные условия. В результате, системы, использующие традиционные подходы, часто требуют ручной настройки и не способны адаптироваться к меняющейся обстановке, что ограничивает их применение в реальных, динамичных средах.
Обеспечение одновременной безопасности и достижения требуемой производительности представляет собой сложную задачу, особенно в динамически меняющихся условиях. Традиционные подходы к управлению часто оказываются неэффективными при столкновении со сложными, нелинейными системами и непредвиденными возмущениями. В динамической среде, где условия постоянно меняются, поддержание стабильности и точного выполнения поставленных задач требует адаптивных алгоритмов, способных оперативно реагировать на новые обстоятельства. Разработка систем, которые могут гарантированно избегать опасных ситуаций и при этом эффективно достигать заданных целей, требует передовых методов управления и учета неопределенности, а также использования алгоритмов, способных обучаться и адаптироваться в реальном времени.
Полагаться на точные математические модели систем — распространенная, но уязвимая практика. В реальных условиях, окружающая среда постоянно меняется, а сами системы демонстрируют нелинейное поведение, что делает заранее выстроенные модели неадекватными. Даже незначительные отклонения от предполагаемых параметров могут привести к серьезным ошибкам и потере контроля. В результате, системы, основанные на строгих моделях, оказываются неспособными адаптироваться к непредвиденным обстоятельствам и эффективно функционировать в динамически изменяющемся мире. Разработка методов управления, не требующих абсолютной точности модели, становится ключевой задачей для создания надежных и гибких систем, способных противостоять неопределенности и обеспечивать безопасную работу в любых условиях.
Обучение в Темноте: Решение на Основе Обучения с Подкреплением
Обучение с подкреплением (RL) представляет собой альтернативный подход к задачам управления и принятия решений, основанный на извлечении оптимальных стратегий непосредственно из данных, полученных в процессе взаимодействия со средой. В отличие от традиционных методов, требующих явного построения модели системы, RL-агенты обучаются путем проб и ошибок, максимизируя суммарное вознаграждение. Этот процесс позволяет адаптироваться к сложным и динамичным условиям без необходимости предварительного знания структуры системы или математического описания ее поведения. Обучение происходит посредством сбора данных о состояниях, действиях, вознаграждениях и следующих состояниях, которые используются для итеративного улучшения стратегии агента.
В обучении с подкреплением (RL) понятие “политики” (policy) играет центральную роль, определяя стратегию агента в каждой конкретной ситуации. Политика представляет собой отображение состояний среды в действия, то есть, для каждого состояния, агент выбирает действие согласно заданной функции или таблице. Это позволяет агенту адаптироваться к сложной динамике среды без необходимости явного построения её математической модели. Вместо этого, агент учится оптимальной политике, взаимодействуя со средой и получая обратную связь в виде вознаграждения. Такой подход особенно полезен в задачах, где точная модель среды неизвестна или слишком сложна для построения, позволяя агенту находить эффективные решения посредством проб и ошибок.
Функция ценности (V(s)) в обучении с подкреплением является ключевым инструментом для оценки долгосрочных последствий действий, предпринятых агентом в определенном состоянии s. Она предсказывает ожидаемую суммарную награду, которую агент получит, начиная с данного состояния и следуя определенной политике. Оценка производится путем учета не только немедленной награды за действие, но и дисконтированных будущих наград, полученных в результате последовательности действий. Эта дисконтированная сумма, вычисленная рекурсивно, позволяет агенту выбирать действия, максимизирующие долгосрочную прибыль, а не только немедленное вознаграждение. Таким образом, функция ценности направляет процесс обучения, позволяя агенту эффективно исследовать пространство состояний и находить оптимальную стратегию поведения.
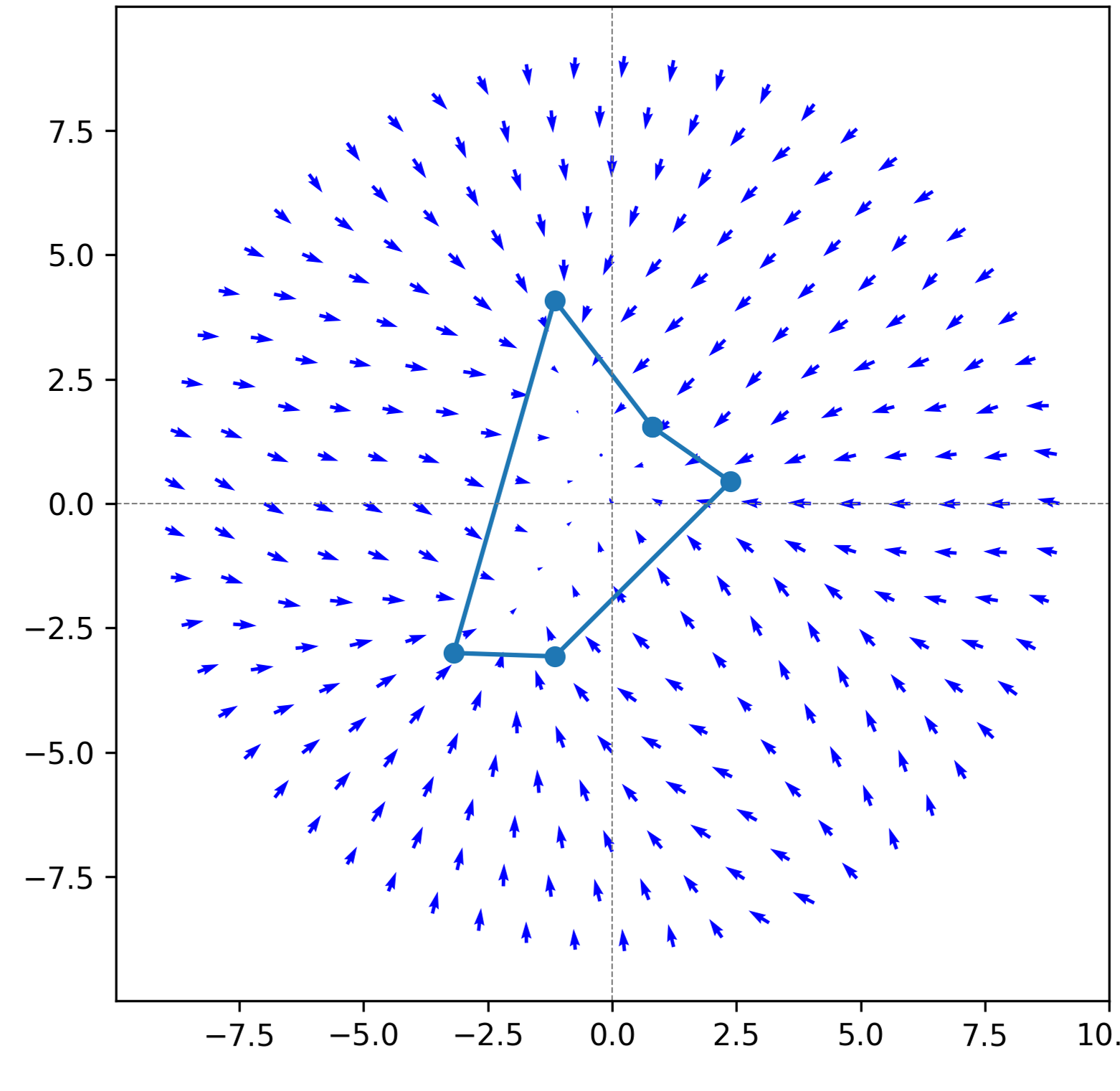
![Обучение с использованием PPO для стационарного прямоугольного элемента [latex]4 \times 24[/latex] за [latex]20000[/latex] эпох с максимальным количеством шагов [latex]100[/latex] позволило получить контуры изученной ценностной функции (a) и среднее векторное поле управления политикой (b).](https://arxiv.org/html/2602.12492v1/figs/PPO_car_0.0_0.0-Vector_Field.png)
Безопасность Прежде Всего: Соединение Обучения с Подкреплением и Контрольных Барьерных Функций
Функции барьерного управления (Control Barrier Functions, CBF) предоставляют формальный математический аппарат для обеспечения безопасности роботизированных систем, определяя допустимые области функционирования. CBF выражаются как неравенства, гарантирующие, что система остаётся в пределах безопасной области, определяемой h(x) \ge 0 , где x — состояние системы. Эти функции строятся на основе анализа динамики системы и определения критических границ, пересечение которых приведёт к небезопасному состоянию. Формализация безопасности позволяет интегрировать CBF с алгоритмами обучения с подкреплением (RL) для разработки контроллеров, которые одновременно оптимизируют целевую функцию и гарантируют соблюдение заданных ограничений безопасности.
Комбинирование Функций Барьерного Управления (Control Barrier Functions, CBF) с обучением с подкреплением (Reinforcement Learning, RL) позволяет создавать контроллеры, которые одновременно стремятся к достижению цели и обеспечивают безопасность. Методы, такие как CLF-CBF-подобное управление и QCQP-контроллеры, реализуют эту интеграцию, определяя допустимые области функционирования системы и корректируя действия агента RL для поддержания его работы в пределах этих границ. Это достигается путем добавления условий безопасности в оптимизационную задачу RL, что позволяет находить оптимальную политику, удовлетворяющую как целевым функциям, так и ограничениям безопасности. Таким образом, создаются системы управления, способные эффективно решать задачи, избегая при этом опасных или нежелательных состояний.
В контроллерах, использующих функции контрольных барьеров (CBF) и обучение с подкреплением (RL), эффективность обеспечения безопасности достигается за счет использования решателей квадратичного программирования (QP). Каждое препятствие моделируется как отдельное квадратичное ограничение, добавляемое в онлайн-QP в процессе оптимизации управления. Это позволяет масштабировать систему безопасности с увеличением числа препятствий без существенного увеличения вычислительной сложности. Решатели QP оптимизируют функцию производительности, одновременно гарантируя, что траектория системы остается в допустимой области, определяемой функциями CBF и ограничениями, связанными с препятствиями. Таким образом, сложность решения QP растет линейно с количеством препятствий, обеспечивая эффективное и масштабируемое решение для безопасного управления.
За Гранью Очевидного: Гауссовские Процессы для Адаптивного и Надежного Управления
Интеграция гауссовских процессов с методами обучения с подкреплением, такими как метод «актер-критик», открывает возможности для эффективного обучения как стратегий поведения, так и оценочных функций даже при ограниченном объеме данных. В отличие от традиционных подходов, требующих обширных наборов данных для точной оценки, гауссовские процессы предоставляют вероятностные прогнозы, позволяющие моделировать неопределенность и экстраполировать знания на новые ситуации. Это особенно ценно в задачах, где сбор данных затруднен или дорог, поскольку позволяет агенту быстро адаптироваться и принимать обоснованные решения, не полагаясь исключительно на опыт. Благодаря способности эффективно представлять сложные взаимосвязи и учитывать неопределенность, гауссовские процессы значительно повышают эффективность обучения и надежность агента в динамичных и непредсказуемых средах.
Гауссовские процессы, встраиваемые в системы управления, значительно повышают их устойчивость к внешним возмущениям и неточностям модели. В отличие от традиционных методов, которые оперируют лишь точечными предсказаниями, гауссовские процессы предоставляют не только прогноз, но и оценку его неопределенности. Эта оценка позволяет системе понимать, насколько надежны ее представления о мире, и соответственно корректировать свои действия. При наличии возмущений или отклонений от модели, система, основываясь на оценке неопределенности, способна переключиться на более консервативную стратегию, избегая рискованных действий. Такой подход позволяет поддерживать стабильную работу системы даже в условиях непредсказуемости, обеспечивая надежность и безопасность ее функционирования. \sigma^2 — дисперсия, являющаяся ключевой метрикой неопределенности, позволяет адаптировать стратегию управления в режиме реального времени.
В рамках обучения с подкреплением функция преимущества, сформированная на основе предсказаний гауссовских процессов, направляет агента к выбору оптимальных действий. Этот подход позволяет значительно ускорить процесс обучения, поскольку гауссовские процессы предоставляют информацию о неопределенности, что помогает агенту эффективно исследовать пространство действий и избегать неоптимальных стратегий. В ходе моделирования сценариев пересечения улицы, данный метод продемонстрировал производительность, сопоставимую с алгоритмом Proximal Policy Optimization (PPO), что подтверждает его эффективность и потенциал для применения в сложных задачах управления и принятия решений. A(s,a) = Q(s,a) - V(s) — именно эта функция, дополненная информацией от гауссовских процессов, позволяет агенту оценивать относительную ценность действий в текущем состоянии.
Взгляд в Будущее: За Пределами Современных Возможностей
Расширение возможностей обучения с подкреплением без модели (Model-Free RL) посредством интеграции изученных ограничений безопасности открывает принципиально новые перспективы для функционирования автономных систем в сложных и неопределенных средах. Традиционные алгоритмы RL часто сталкиваются с трудностями при работе в условиях, где не существует точной модели окружения, а соблюдение ограничений безопасности критически важно. Изучение этих ограничений непосредственно из данных, а не их предварительное задание, позволяет агенту адаптироваться к новым ситуациям и избегать опасных действий. Это особенно важно в таких областях, как робототехника, автономное вождение и управление сложными процессами, где цена ошибки может быть очень высокой. Развитие данного направления позволит создавать более надежные и безопасные системы искусственного интеллекта, способные эффективно действовать в реальном мире.
В рамках разработки систем обучения с подкреплением без учителя, использование алгоритма Proximal Policy Optimization (PPO) демонстрирует значительное повышение эффективности обучения и стабильности. PPO, в отличие от других методов, позволяет осуществлять более безопасные и постепенные обновления политики агента, избегая резких изменений, которые могут привести к дестабилизации процесса обучения. Этот подход особенно важен в сложных и неопределенных средах, где сбор данных может быть дорогостоящим или рискованным. Благодаря способности PPO эффективно использовать имеющиеся данные и адаптироваться к изменяющимся условиям, системы на его основе способны достигать высоких показателей производительности, требуя при этом значительно меньше взаимодействий со средой, чем альтернативные методы обучения с подкреплением. Таким образом, интеграция PPO в архитектуру обучения без учителя открывает перспективные возможности для создания автономных систем, способных к надежной и эффективной работе в реальных условиях.
Дальнейшие исследования, направленные на интеграцию аппроксимации функций с методами формального управления, открывают принципиально новые перспективы для развития автономных систем. Традиционные методы формального управления гарантируют безопасность и корректность работы, однако часто ограничены в применении к сложным, высокоразмерным пространствам состояний. Аппроксимация функций, напротив, позволяет эффективно работать с такими пространствами, но не предоставляет строгих гарантий безопасности. Объединение этих подходов позволит создать системы, способные надежно функционировать в сложных и непредсказуемых условиях, сочетая преимущества как гарантий безопасности, так и масштабируемости. В частности, это может привести к разработке более совершенных алгоритмов управления для робототехники, беспилотных транспортных средств и других автономных устройств, способных адаптироваться к изменяющимся обстоятельствам и принимать решения в условиях неопределенности.
Данная работа демонстрирует подход к обучению с подкреплением, который позволяет создавать сложные системы управления без необходимости явного моделирования динамики окружающей среды. Это напоминает о важности понимания фундаментальных принципов, лежащих в основе любой системы, для её эффективного управления. Как однажды заметила Ада Лавлейс: «То, что аналитическая машина может делать, определяется не только тем, что она может делать, но и тем, что мы можем заставить её делать». Именно способность к композиции, к объединению простых элементов в сложные структуры, позволяет преодолеть ограничения, накладываемые отсутствием точной модели, и достичь желаемого поведения системы, что особенно актуально в контексте непрерывного времени и задач навигации, рассматриваемых в данной статье.
Что дальше?
Представленная работа, по сути, лишь отладила небольшой фрагмент кода реальности. Подход, позволяющий обходить необходимость в явных моделях систем, — это шаг к созданию агентов, способных действовать в условиях абсолютной неопределённости. Однако, за каждым успешно пройденным этапом навигации скрывается вопрос: насколько фундаментально эта «композируемость» встроена в саму ткань управления? Решение, основанное на Reinforcement Learning, демонстрирует работоспособность, но не объясняет, почему именно такая архитектура оказалась эффективной. Поиск ответа на этот вопрос — следующий уровень взлома.
Очевидным ограничением остаётся сложность масштабирования. Гауссовские процессы, хотя и элегантны, могут оказаться непосильной ношей для систем высокой размерности. Необходимо искать альтернативные способы представления неопределенности, возможно, заимствуя идеи из теории информации или статистической физики. Более того, гарантии безопасности, обеспечиваемые Control Barrier Functions, хоть и важны, нуждаются в уточнении в условиях неидеальных сенсоров и вычислений. Реальность всегда вносит шум.
В конечном счёте, представленный подход — это приглашение к исследованию. Реальность — это открытый исходный код, который ещё предстоит прочитать. И, возможно, самый интересный вопрос заключается не в том, как заставить агента достичь цели, а в том, что произойдёт, когда он поймёт, что цели, в принципе, не существует.
Оригинал статьи: https://arxiv.org/pdf/2602.12492.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- АЛРОСА акции прогноз. Цена ALRS
- Геополитика, Швейцарский Цифровой Франк и Инсайдерская Торговля: Обзор Ключевых Событий Недели (08.04.2026 13:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- ЭсЭфАй акции прогноз. Цена SFIN
- Группа Аренадата акции прогноз. Цена DATA
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
2026-02-17 06:12