Автор: Денис Аветисян
Исследователи предлагают инновационную методику для обучения взаимодействующих агентов в непрерывном времени, гарантирующую соблюдение ограничений безопасности.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Предложенная схема обучения с подкреплением CT-MARL, основанная на эпиграфах, объединяет внешнюю оптимизацию для достижения баланса между суммарной дисконтированной стоимостью и ограничениями безопасности с внутренней оптимизацией, одновременно обучающей сети оценки возвратов [latex]V^{\text{ret}}\_{\psi}(x)[/latex] и сети оценки ограничений [latex]V^{\text{cons}}\_{\phi}(x)[/latex] в сочетании с оптимальным вспомогательным состоянием [latex]z^{\*}[/latex], что позволяет улучшать политики на основе функции преимущества.](https://arxiv.org/html/2602.17078v1/x1.png)
В статье представлена схема на основе эпиграфа для обучения с подкреплением в непрерывном времени, обеспечивающая стабильность обучения и эффективное обновление стратегий в многоагентных системах.
Несмотря на значительный прогресс в обучении с подкреплением для мультиагентных систем, большинство алгоритмов по-прежнему опираются на дискретные временные интервалы, что ограничивает их применение в сложных динамических средах. В данной работе, озаглавленной ‘Safe Continuous-time Multi-Agent Reinforcement Learning via Epigraph Form’, предложен новый подход к обучению с подкреплением в непрерывном времени, позволяющий учитывать ограничения безопасности посредством преобразования разрывных функций ценности в непрерывные с использованием эпиграфической формулировки. Предложенная методика, основанная на физически обоснованных нейронных сетях (PINN), обеспечивает стабильную оптимизацию и эффективное обновление стратегий в непрерывном времени. Сможет ли данная архитектура стать основой для создания надежных и безопасных мультиагентных систем в реальных приложениях?
Непрерывность Времени: Вызов для Многоагентных Систем
Традиционные методы обучения с подкреплением, функционирующие в дискретном времени, испытывают значительные трудности при моделировании и управлении системами с непрерывной динамикой. Это связано с тем, что реальные физические процессы зачастую развиваются плавно и непрерывно, в то время как дискретные алгоритмы аппроксимируют эти процессы, разбивая время на отдельные шаги. Такая дискретизация может приводить к потере информации и неточностям, особенно при управлении сложными системами, где даже небольшие ошибки могут накапливаться и приводить к нестабильности или неоптимальному поведению. По сути, дискретное представление непрерывного мира является упрощением, которое может ограничивать возможности алгоритма эффективно реагировать на изменения и обеспечивать надежное управление, особенно в ситуациях, требующих высокой точности и плавности действий.
Особую сложность представляют многоагентные системы, где взаимодействие агентов происходит в среде с непрерывно меняющейся динамикой. В подобных системах, агенты постоянно адаптируются к изменениям, вызванным как окружающей средой, так и действиями других агентов. Непрерывность этих изменений требует от агентов способности к оперативной реакции и прогнозированию, что существенно усложняет задачу поддержания стабильности и безопасности. Традиционные методы, рассчитанные на дискретные моменты времени, оказываются неэффективными в отслеживании и управлении сложными взаимодействиями, возникающими в такой динамичной среде, и могут приводить к непредсказуемым последствиям. Поэтому разработка алгоритмов, способных учитывать непрерывность времени и взаимодействия, является ключевой задачей для обеспечения надежного функционирования многоагентных систем.
Эффективное управление ограничениями безопасности в многоагентных системах требует методов, способных рассуждать о поведении во времени, непрерывном времени. Существующие подходы, основанные на дискретном времени, часто оказываются недостаточными для обеспечения стабильной и предсказуемой работы системы. Это связано с тем, что дискретизация непрерывных процессов вносит погрешности, которые могут накапливаться и приводить к нарушению ограничений безопасности, особенно в сложных сценариях взаимодействия агентов. Поэтому разработка алгоритмов, способных учитывать динамику систем в непрерывном времени, является ключевой задачей для обеспечения надежности и безопасности многоагентных систем, функционирующих в реальных условиях. \in t_{t_0}^{t_1} f(t) dt Такие методы позволяют более точно моделировать поведение системы и предсказывать ее реакцию на различные воздействия, что критически важно для предотвращения аварийных ситуаций.
Непрерывное Время и Эпиграфическая Переформулировка: Путь к Стабильности
Многоагентная система моделируется с использованием ContinuousTimeMarkovDecisionProcess (CTMDP), что позволяет более естественно представить её динамику. В отличие от дискретных моделей, CTMDP учитывает непрерывное течение времени, что особенно важно для систем, где решения принимаются и действия выполняются в моменты времени, отличные от фиксированных шагов. Это позволяет описывать системы, где состояние и награда могут изменяться непрерывно во времени, а также учитывать задержки и длительность действий. Использование CTMDP позволяет точнее моделировать взаимодействие агентов в сложных средах и повышает эффективность алгоритмов обучения с подкреплением, предназначенных для решения задач управления в таких системах.
Техника эпиграфической переформулировки (Epigraph Reformulation) преобразует потенциально разрывные функции ограничений в непрерывные, что позволяет добиться стабильного обучения и надежного соблюдения ограничений. В традиционных подходах к обучению с ограничениями, разрывные функции могут приводить к нестабильности алгоритмов оптимизации и непредсказуемому поведению агентов. Переформулировка заключается в построении эпиграфа функции ограничений, который представляет собой множество всех точек, лежащих ниже графика функции. Этот эпиграф является выпуклым множеством, что позволяет применять стандартные методы выпуклой оптимизации для решения задачи обучения с ограничениями. В результате, алгоритм обучения становится более устойчивым к изменениям в окружающей среде и гарантирует, что агенты будут соблюдать ограничения на протяжении всего процесса обучения.
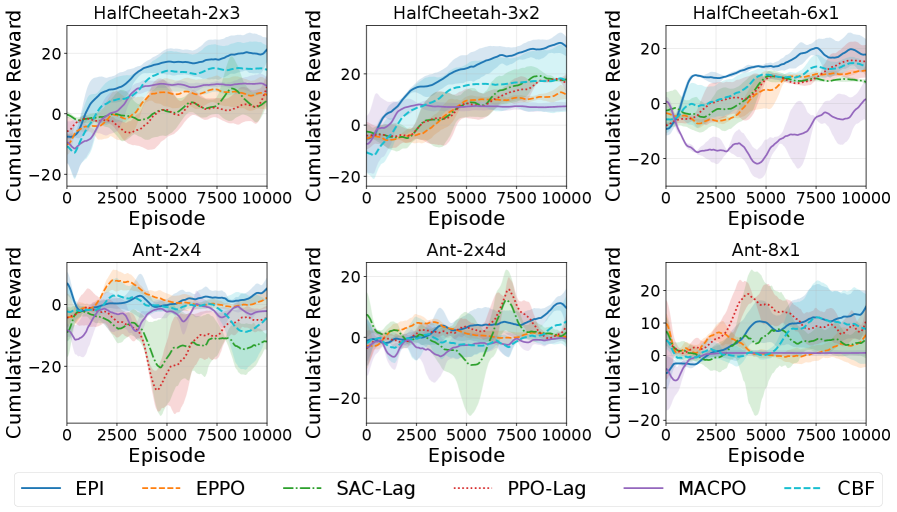
Использование преобразования эпиграфа расширяет применимость алгоритмов оптимизации к задачам управления в непрерывном времени в сложных многоагентных средах. Экспериментальные данные, полученные на платформах MPE (Multi-Agent Particle Environments) и MuJoCo, демонстрируют, что применение данной техники приводит к стабильному увеличению суммарной награды по сравнению с альтернативными подходами. Это объясняется тем, что преобразование обеспечивает непрерывность функций ценности, что облегчает процесс обучения и повышает надежность удовлетворения ограничениям, особенно в условиях высокой сложности и нелинейности динамики системы. Доказано, что данная методика позволяет эффективно решать задачи управления в сценариях, требующих координации между несколькими агентами.
Решение Уравнения Беллмана с Использованием Физически Информированных Нейронных Сетей
Уравнение Беллмана (HJB PDE) описывает оптимальную функцию ценности в задачах непрерывного времени, являясь ключевым инструментом в динамическом программировании и оптимальном управлении. Однако, аналитическое решение HJB PDE часто оказывается невозможным из-за сложности уравнений в реальных задачах, особенно при высокой размерности пространства состояний или нелинейной динамике системы. Это обусловлено тем, что уравнение представляет собой нелинейное частное дифференциальное уравнение, для которого не существует общих методов решения. В таких случаях применяются численные методы, такие как методы Монте-Карло или, в последнее время, нейронные сети, обученные с учетом физических ограничений, для аппроксимации оптимальной функции ценности и, соответственно, оптимальной стратегии управления.
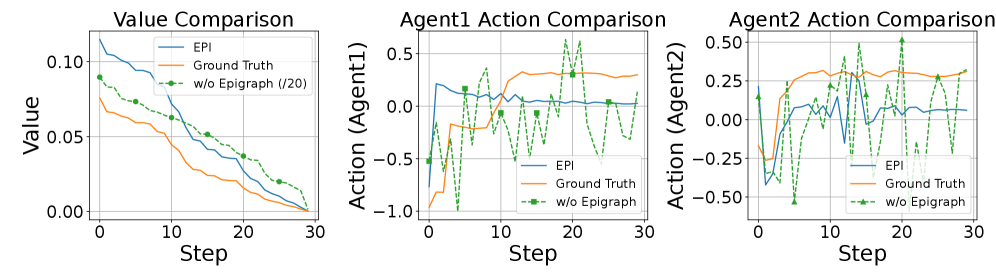
Для приближенного решения уравнения Гамильтона-Якоби-Беллмана (HJB PDE) используется метод нейронных сетей, учитывающих физические ограничения (PINN). PINN позволяет аппроксимировать решение, используя информацию о физических свойствах системы, что повышает точность и стабильность обучения. В рамках PINN, HJB PDE рассматривается как задача минимизации остатка, где нейронная сеть обучается на множестве точек, удовлетворяющих уравнению и граничным условиям. Использование физики системы в качестве регуляризатора позволяет эффективно решать задачи, для которых традиционные численные методы оказываются неэффективными или требуют чрезмерных вычислительных ресурсов. В частности, PINN позволяет обойти необходимость в построении дискретной сетки и обеспечивает дифференцируемое приближение решения V(x,t), где V — функция ценности.
В рамках подхода, использующего физически информированные нейронные сети (PINN) для решения уравнения Гамильтона-Якоби-Беллмана (HJB), применяется архитектура «Актер-Критик». Данная архитектура объединяет обучение политики (реализуемое «Актером») и аппроксимацию функции ценности (выполняемую «Критиком»). «Актер» отвечает за выбор действий, в то время как «Криктик» оценивает качество этих действий, предоставляя сигнал для улучшения политики. Интеграция обеих составляющих в единую нейронную сеть позволяет одновременно оптимизировать стратегию управления и оценить соответствующую функцию ценности, что способствует более эффективному решению задачи оптимального управления, характеризующейся уравнением HJB.
Обучение критика осуществляется посредством внутренней оптимизационной петли, использующей функции потерь, такие как ResidualLoss (остаточная ошибка), TargetLoss (ошибка по целевому значению) и VGILoss (потеря, связанная с градиентом), что позволяет минимизировать нарушения ограничений. В ходе экспериментов было показано, что предложенный подход демонстрирует более низкий уровень нарушения ограничений по сравнению с базовыми методами, такими как MACPO, MAPPO-Lag, SAC-Lag, EPPO и CBF. Использование комбинации указанных функций потерь в процессе обучения критика способствует повышению стабильности и точности оценки оптимальной функции ценности, что критически важно для решения задач управления с ограничениями.
Обеспечение Безопасности и Масштабируемости в Многоагентных Системах
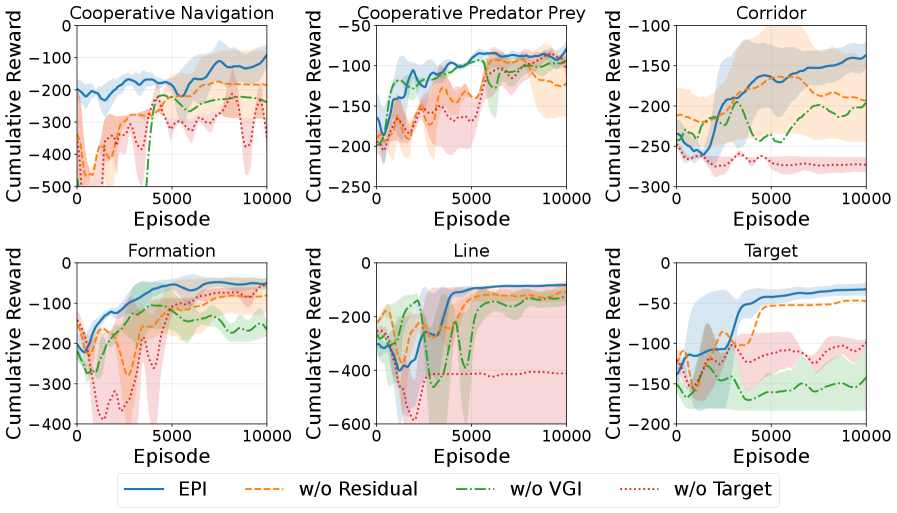
Интеграция метода EpigraphReformulation с архитектурой актор-критик, основанной на физически информированных нейронных сетях (PINN), и внешним циклом оптимизации OuterOptimizationLoop позволяет добиться безопасного и эффективного управления в многоагентных системах. Данный подход, используя преимущества каждого компонента, обеспечивает стабильность и предсказуемость поведения агентов даже в сложных динамических условиях. EpigraphReformulation позволяет переформулировать ограничения безопасности в виде дифференцируемых условий, что критически важно для обучения с подкреплением, использующего градиентные методы. Архитектура PINN, в свою очередь, позволяет учитывать физические законы, управляющие системой, что повышает надежность и обобщающую способность. Внешний цикл оптимизации обеспечивает глобальную сходимость и позволяет находить оптимальные стратегии управления для всех агентов, координируя их действия и избегая конфликтов.
Разработанный подход успешно протестирован в сложных задачах, включающих формирование строя (FormationTask), выстраивание в линию (LineTask) и достижение целевых точек (TargetTask). Результаты демонстрируют высокую устойчивость и адаптивность системы к изменяющимся условиям, а также значительное превосходство над существующими алгоритмами, оцениваемое по показателю суммарного вознаграждения. На практике это означает, что предложенная архитектура не только эффективно решает поставленные задачи, но и обеспечивает более стабильную и предсказуемую работу в различных сценариях, что критически важно для применения в реальных системах управления.
В отличие от дискретных методов, непрерывно-временной подход демонстрирует повышенную масштабируемость в многоагентных системах. Исследования показали, что разработанная система сохраняет стабильную производительность даже при значительном уровне шума (σ^2 = 1.0), что свидетельствует о её устойчивости к помехам. При этом наблюдается закономерная тенденция к снижению эффективности системы с уменьшением интервала дискретизации (Δt), что подтверждает преимущества непрерывной модели в обработке динамических процессов и позволяет эффективно управлять большим количеством агентов без существенной потери точности и скорости работы. Данный подход позволяет более реалистично моделировать реальные физические системы и повышает надёжность управления в сложных сценариях.
Представленная работа демонстрирует стремление к упрощению сложных систем, что находит отклик в философии ясности и милосердия. Авторы, подобно хирургу, иссекают разрывы в непрерывных функциях ценности, преобразуя их посредством эпиграфа, дабы обеспечить стабильность обучения критика и эффективные обновления политики. Этот подход к решению задач обучения с подкреплением в непрерывном времени, особенно в контексте безопасных многоагентных систем, подчеркивает важность устранения избыточности. Как однажды заметил Винтон Серф: «Интернет — это не просто технология, это способ мышления». Подобно этому, предложенный метод рассматривает не только техническую реализацию, но и фундаментальную ясность в определении и достижении безопасного обучения.
Что дальше?
Предложенная работа, хотя и демонстрирует элегантность преобразования разрывных функций ценности, не решает фундаментальную проблему: сложность возрастает пропорционально количеству агентов. Идея непрерывного времени, безусловно, заманчива, но её практическая ценность ограничена вычислительными затратами, особенно в сценариях с высокой степенью взаимодействия. Утверждение о безопасности, полученной за счёт сглаживания, требует дальнейшей проверки в условиях неопределенности и неполной информации.
Будущие исследования должны сосредоточиться на разработке методов масштабирования, позволяющих применять предложенный подход к системам с большим числом агентов. Интересным направлением представляется комбинация с методами декомпозиции задач, позволяющими разделить сложную проблему на более простые, решаемые независимо. Следует также учитывать, что «безопасность» — понятие относительное, и необходимо разработать более строгие метрики и гарантии.
В конечном счете, ценность данной работы заключается не столько в достигнутом результате, сколько в выявлении нерешенных вопросов. Иногда полезнее признать границы своих возможностей, чем строить иллюзии о совершенстве. Истина часто скрывается в признании собственной неполноты.
Оригинал статьи: https://arxiv.org/pdf/2602.17078.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать доллары за рубли сейчас или подождать?
- Будущее биткоина к рублю: прогноз цен на криптовалюту BTC
- Будущее биткоина: прогноз цен на криптовалюту BTC
- Стоит ли покупать фунты за йены сейчас или подождать?
- Пошлины Трампа и падение «ЕвроТранса»: что ждет инвесторов? (21.02.2026 23:32)
- Золото прогноз
- Риски для бизнеса и туристический спрос: что ждет российскую экономику? (22.02.2026 18:32)
- Геопространственные модели для оценки оползневой опасности: новый уровень точности
- Почему акции Joby взлетают: приобретение Blade
- Серебро прогноз
2026-02-22 15:48