Автор: Денис Аветисян
Исследователи предлагают инновационную систему, использующую адаптивное обучение с подкреплением для повышения безопасности и эффективности автономных автомобилей в условиях сложного городского трафика.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал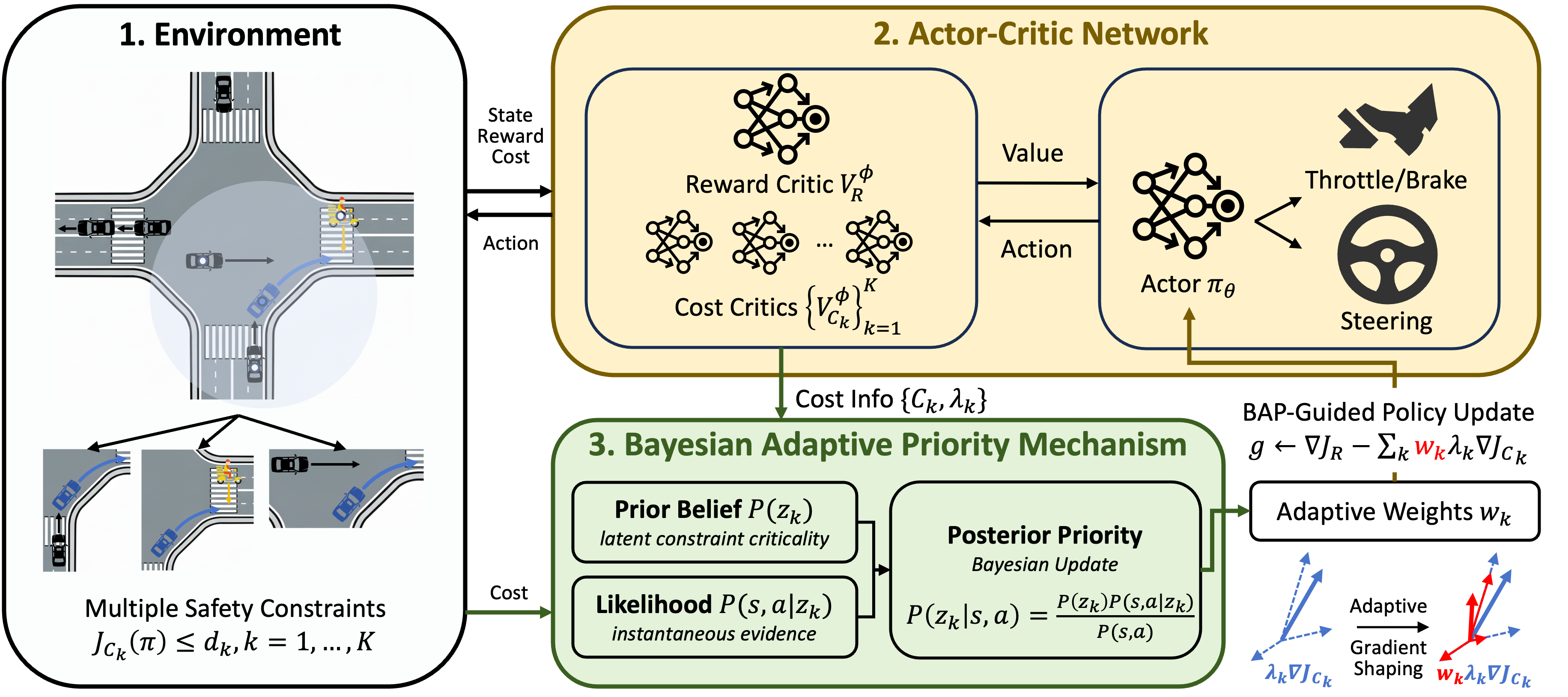
Представлен алгоритм BAP-SRL, использующий байесовскую оптимизацию и механизм приоритетов для разрешения конфликтов и обеспечения безопасного движения в условиях смешанного трафика.
Несмотря на значительный прогресс в области автономного вождения, обеспечение безопасности при взаимодействии с разнородным трафиком на городских перекрестках остается сложной задачей. В данной работе, посвященной разработке алгоритма ‘BAP-SRL: Bayesian Adaptive Priority Safe Reinforcement Learning for Vehicle Motion Planning at Mixed Traffic Intersections’, предложен новый подход к безопасному обучению с подкреплением, основанный на байесовском адаптивном определении приоритетов для разрешения конфликтующих ограничений безопасности. Предложенный алгоритм BAP-SRL динамически оценивает критичность ограничений, что позволяет эффективно справляться с многообразными рисками и оптимизировать траектории движения. Способен ли этот подход значительно повысить надежность и эффективность автономных транспортных средств в условиях реального городского трафика?
Противоречия в Автономном Движении: Искусство Баланса
Автономные транспортные средства сталкиваются с весьма сложными задачами обеспечения безопасности, обусловленными необходимостью соблюдения множества противоречивых ограничений в процессе движения. Например, алгоритм может одновременно требовать минимизации риска столкновения, соблюдения правил дорожного движения и поддержания комфорта пассажиров. Эти ограничения часто вступают в конфликт: резкое торможение для предотвращения столкновения может привести к дискомфорту, а строгое соблюдение скоростного режима может создать опасность в ситуациях, требующих быстрого маневра. Такое сосуществование противоречивых требований представляет собой серьезную проблему для разработчиков, поскольку требует создания систем, способных находить оптимальный баланс между различными приоритетами и адаптироваться к постоянно меняющимся условиям на дороге. Эффективное решение этой проблемы является ключевым фактором для обеспечения безопасной и надежной работы автономных транспортных средств в реальных условиях.
Традиционные методы обучения с подкреплением, ориентированные на безопасность, часто сталкиваются с трудностями при разрешении конфликтующих ограничений. В результате, алгоритмы склонны к формированию чрезмерно осторожной стратегии поведения, что существенно ограничивает возможности автономного транспортного средства и снижает его эффективность в реальных условиях. Альтернативно, при попытке обойти жесткие ограничения, может возникнуть непредсказуемое поведение, представляющее опасность для окружающих. Данная проблема обусловлена тем, что стандартные подходы рассматривают ограничения как абсолютные барьеры, не позволяющие гибко адаптироваться к сложным и динамичным ситуациям на дороге, что приводит к параличу алгоритма при возникновении противоречивых требований.
В процессе обучения автономных транспортных средств часто возникают ситуации, когда различные ограничения безопасности вступают в противоречие друг с другом. Представьте, что автомобиль должен одновременно избегать столкновения с пешеходом и соблюдать правила дорожного движения, которые могут потребовать выполнения маневра, кажущегося опасным для пешехода. В таких случаях, попытка жесткого приоритизировать одно ограничение над другим приводит к параличу системы принятия решений — автомобиль не может выбрать действие, поскольку любое решение нарушает одно из важных ограничений. Это явление, известное как паралич политики, становится серьезным препятствием для создания надежных и безопасных автономных систем, требуя разработки более сложных механизмов разрешения конфликтующих требований и учета контекста ситуации.
Для успешного преодоления сложных ситуаций, возникающих в процессе автономного вождения, требуется принципиально новый подход к управлению ограничениями, выходящий за рамки простой статической приоритизации. Вместо жёсткого выбора одного приоритета над другим, современные исследования направлены на разработку систем, способных динамически оценивать важность каждого ограничения в зависимости от конкретной ситуации. Такой подход позволяет транспортному средству учитывать множество факторов, таких как скорость, расстояние до препятствий и дорожная обстановка, и находить компромиссные решения, обеспечивающие безопасность и эффективность. Вместо паралича в условиях противоречивых требований, система адаптируется, минимизируя риски и одновременно стремясь к оптимальному выполнению поставленной задачи. Это достигается за счёт использования алгоритмов, способных к взвешенному принятию решений и гибкой адаптации к меняющимся условиям окружающей среды.
Динамическая Приоритизация Безопасности: Новый Подход
Представлен новый фреймворк — Bayesian Adaptive Priority Safe RL, предназначенный для динамической приоритизации ограничений безопасности на основе оценки рисков в реальном времени. В отличие от статических подходов, данная система непрерывно анализирует текущую ситуацию и корректирует важность каждого ограничения, позволяя агенту адаптироваться к изменяющимся условиям. Оценка рисков осуществляется посредством анализа данных, поступающих от среды, и сопоставления их с априорными знаниями о сложности ограничений. Это обеспечивает гибкое управление балансом между соблюдением ограничений безопасности и достижением целевой производительности, что критически важно в задачах, где нарушение ограничений может привести к серьезным последствиям.
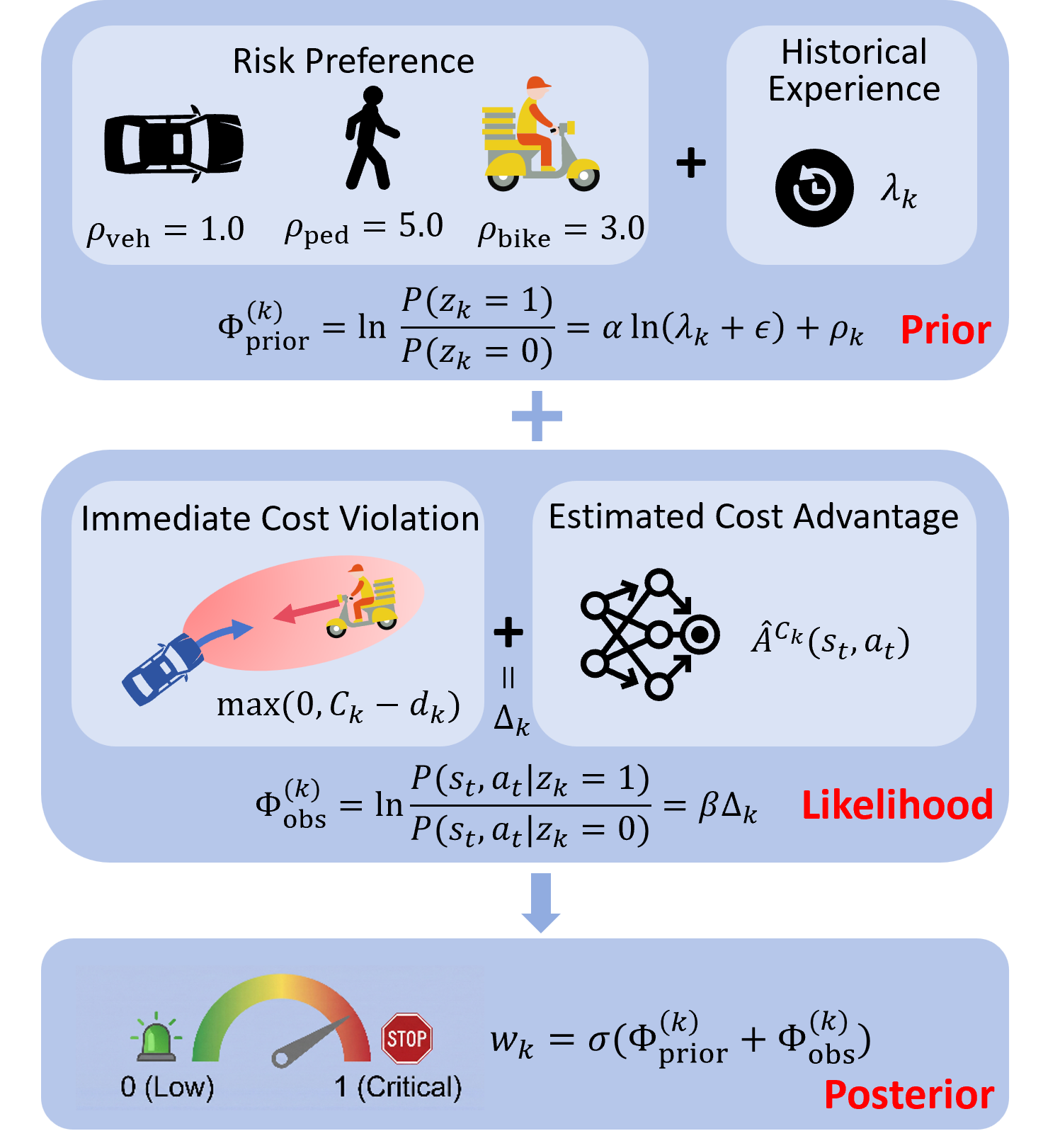
В основе предложенного подхода лежит байесовский вывод, позволяющий комбинировать априорные знания о сложности ограничений с текущими данными о риске. Априорные знания, представляющие собой начальную оценку сложности выполнения каждого ограничения, обновляются на основе поступающей информации о фактическом риске нарушения этого ограничения в процессе обучения. Это обновление происходит посредством применения теоремы Байеса, что позволяет динамически корректировать приоритеты безопасности. В частности, ограничения, для которых текущие данные свидетельствуют о повышенном риске нарушения, получают более высокий приоритет, в то время как ограничения, которые легко выполняются, могут временно отойти на второй план. Такой подход обеспечивает гибкую приоритизацию, адаптирующуюся к изменяющимся условиям и обеспечивающую оптимальный баланс между безопасностью и производительностью агента.
Данный подход позволяет агенту интеллектуально балансировать конкурирующие ограничения, оптимизируя как безопасность, так и производительность. Это достигается за счет динамической адаптации приоритетов ограничений на основе текущей оценки рисков и накопленных знаний о сложности каждого ограничения. Агент не просто стремится выполнить все ограничения одновременно, а формирует приоритеты, позволяющие ему эффективно исследовать пространство действий и находить решения, которые минимизируют риск нарушения критических ограничений при одновременном максимизировании вознаграждения. Такая адаптация позволяет агенту эффективно функционировать в сложных и динамичных средах, где требования к безопасности и производительности могут меняться со временем.
В основе алгоритма лежит использование функций стоимости (CostFunction) и вознаграждения (RewardFunction) в рамках процесса принятия решений Маркова с ограничениями (ConstrainedMarkovDecisionProcess). CostFunction определяет штраф за нарушение ограничений безопасности, а RewardFunction — величину вознаграждения за достижение целевого состояния. Оптимизация обучения происходит путем минимизации совокупной стоимости и максимизации совокупного вознаграждения, что позволяет агенту находить стратегии, удовлетворяющие ограничениям безопасности и одновременно достигающие поставленных целей. Взаимодействие этих функций в рамках ConstrainedMarkovDecisionProcess обеспечивает структурированный подход к обучению с учетом ограничений.
Формирование Градиентов и Реализация Алгоритма
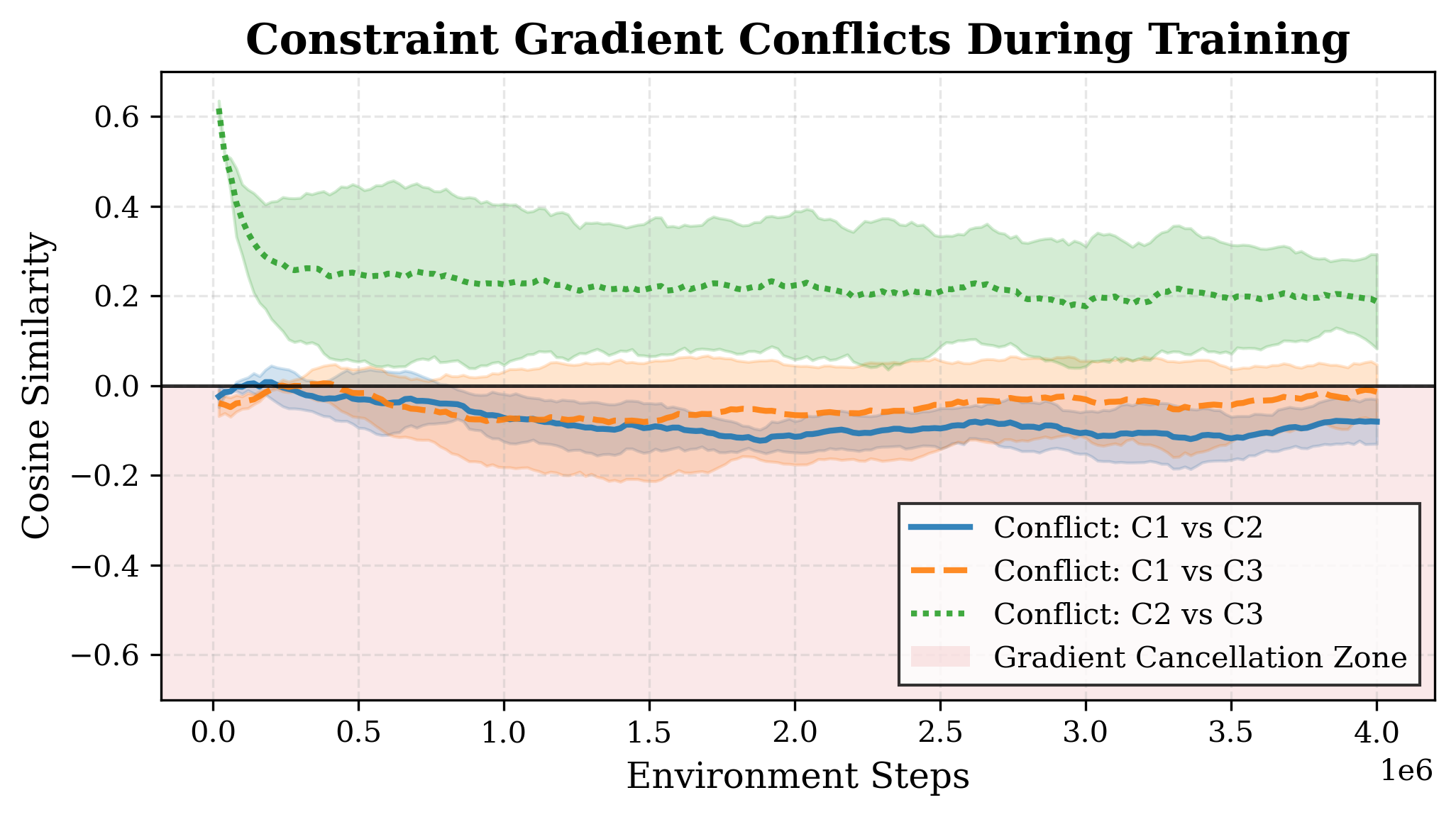
В основе нашего подхода лежит вероятностный механизм формирования градиентов — `BAPMechanism`, который динамически регулирует вклад градиентов ограничений на основе апостериорной критичности. Данный механизм оценивает важность каждого градиента ограничения, определяя его влияние на достижение целевой функции и соблюдение ограничений. Регулировка осуществляется путем взвешивания градиентов: градиенты, признанные более критичными для обеспечения соблюдения ограничений и оптимизации целевой функции, получают больший вес, в то время как менее значимые градиенты могут быть ослаблены или полностью исключены из процесса оптимизации. Такой подход позволяет избежать ситуации, когда градиенты, направленные в противоположные стороны, нейтрализуют друг друга, что может привести к замедлению или остановке обучения.
Явление \text{GradientCancellation} возникает в процессе обучения с ограничениями, когда градиенты, соответствующие целевой функции и ограничениям, направлены в противоположные стороны. Это приводит к взаимному ослаблению или нейтрализации сигналов градиента, что замедляет или останавливает процесс обучения. Механизм динамического взвешивания градиентов, реализованный в нашей системе, предотвращает \text{GradientCancellation} путем избирательной блокировки или ослабления градиентов ограничений, когда они вступают в конфликт с градиентами целевой функции. Таким образом, обеспечивается более стабильное и эффективное продвижение к оптимальному решению, сохраняя при этом выполнение заданных ограничений.
Алгоритм PPO-Lagrangian представляет собой комбинацию алгоритма обучения с подкреплением Proximal Policy Optimization (PPO) и метода релаксации Лагранжа. Использование релаксации Лагранжа позволяет эффективно решать задачи оптимизации с ограничениями, преобразуя их в задачу без ограничений путем добавления штрафных членов к целевой функции. Интеграция с PPO обеспечивает стабильность и эффективность обучения, позволяя алгоритму находить оптимальные политики, удовлетворяющие заданным ограничениям. Такой подход позволяет решать сложные задачи управления, требующие соблюдения определенных границ и условий, и обеспечивает более быструю сходимость по сравнению с традиционными методами оптимизации с ограничениями.
Алгоритм разработан для функционирования в системе координат Френе (FrenetCoordinateSystem), что обеспечивает надежное и релевантное представление состояния транспортного средства. Данная система координат описывает траекторию движения как кривую в пространстве, а положение автомобиля задается через длину дуги этой кривой и поперечное смещение. Использование координат Френе позволяет упростить моделирование динамики автомобиля и эффективно учитывать ограничения, связанные с геометрией траектории и физическими возможностями транспортного средства. В частности, это позволяет более точно контролировать ориентацию автомобиля относительно траектории и минимизировать ошибки, возникающие при следовании по заданной кривой.
Результаты Моделирования и Оценка Эффективности
Для подтверждения эффективности разработанного подхода, его валидация проводилась в реалистичной среде симулятора CARLA, широко используемой в исследованиях автономного вождения. Платформа CARLA предоставляет детальную физическую модель окружения, включая различные типы дорог, транспортных средств и пешеходов, что позволяет проводить всестороннее тестирование алгоритмов управления в контролируемых, но реалистичных условиях. Использование CARLA гарантирует, что полученные результаты будут релевантны и применимы к реальным сценариям вождения, а также облегчает воспроизводимость экспериментов и сравнение с другими существующими подходами в области безопасного обучения с подкреплением.
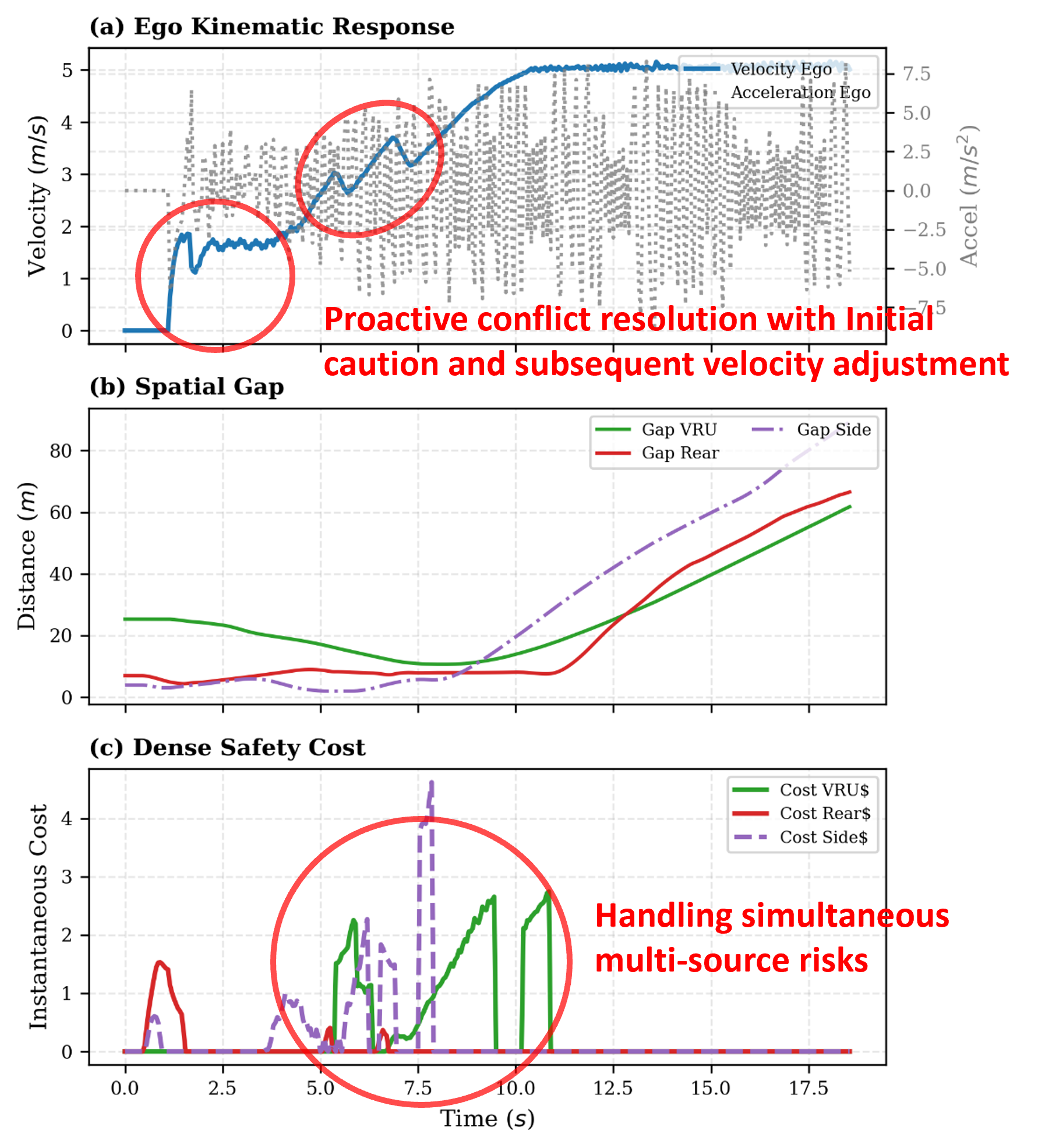
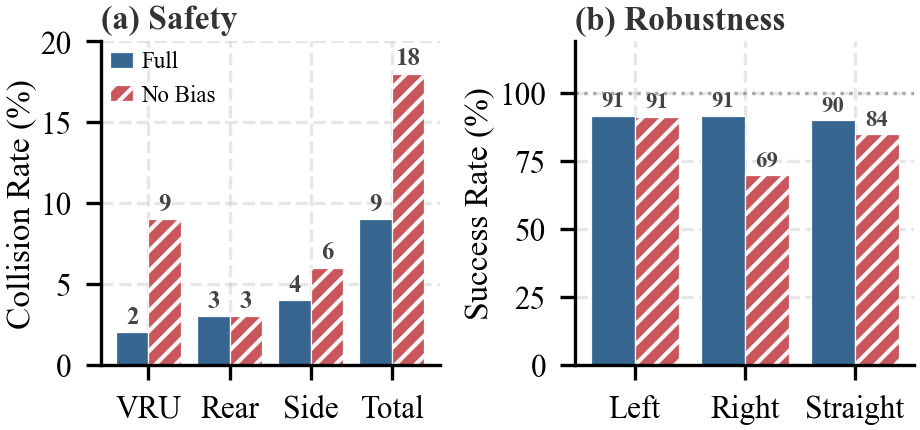
Результаты моделирования продемонстрировали существенное снижение частоты столкновений до 9,00%, что представляет собой уменьшение на 60,87% по сравнению с другими методами обучения с подкреплением с ограничениями. Данное достижение указывает на повышенную безопасность предложенного подхода в виртуальной среде. Снижение частоты столкновений является ключевым показателем эффективности систем автономного управления, поскольку напрямую влияет на предотвращение аварийных ситуаций и обеспечение надежной работы транспортного средства. Полученные данные подтверждают, что разработанная методика способна эффективно решать задачу обеспечения безопасности в сложных условиях, превосходя по этому показателю существующие аналоги.
Исследования показали, что разработанный подход демонстрирует существенно более низкий средний уровень риска и повышенную устойчивость политики в сложных сценариях, характеризующихся конфликтующими ограничениями. В ходе моделирования, средний риск был снижен до 0.48, что является наименьшим показателем среди всех сравниваемых методов. Это указывает на то, что предложенная методология способна более эффективно справляться с неопределенностью и потенциальными опасностями, возникающими в динамичной среде, обеспечивая более безопасное и надежное поведение автономного транспортного средства даже в критических ситуациях. Повышенная устойчивость политики позволяет системе сохранять работоспособность и избегать нежелательных последствий при столкновении с непредвиденными обстоятельствами и противоречивыми требованиями.
В ходе симуляций было зафиксировано увеличение средней скорости и сокращение времени достижения цели по сравнению с алгоритмом PPOLag (Min-Max). В частности, разработанный подход демонстрирует более эффективное выполнение маневров, что подтверждается достижением показателя успешности выполнения правого поворота в 91.67% — наивысшего значения среди всех протестированных методов. Данные результаты указывают на способность системы не только обеспечивать безопасность движения, но и оптимизировать траекторию, что способствует повышению общей эффективности и скорости автономного вождения в сложных условиях.
Полученные результаты демонстрируют значительный потенциал подхода Bayesian Adaptive Priority Safe RL для повышения безопасности и надежности автономных транспортных средств. Проведенные исследования в симуляторе CARLA показали, что применение данной методики позволяет существенно снизить частоту столкновений и общий уровень риска в сложных сценариях, где необходимо соблюдать несколько ограничений одновременно. В частности, зафиксировано снижение показателя CollisionRate на 60.87% и достижение минимального значения AverageRisk среди сравниваемых методов, что свидетельствует о повышенной устойчивости системы к нештатным ситуациям. Улучшение показателей Average Speed и Time to Goal, а также высокий Success Rate (Right Turn) в 91.67%, подтверждают эффективность разработанного подхода в обеспечении не только безопасности, но и оптимальной производительности автономного вождения.
В представленной работе исследуется проблема безопасного планирования движения автономных транспортных средств на сложных перекрестках. Авторы предлагают BAP-SRL — систему, способную адаптироваться к конфликтующим ограничениям безопасности, что особенно важно в условиях смешанного трафика. Этот подход напоминает философское утверждение Сёрена Кьеркегора: «Жизнь — это не поиск себя, а создание себя». Подобно тому, как человек создает себя через выбор и действие, BAP-SRL создает безопасную траекторию, адаптируясь к меняющейся обстановке. Система не просто реагирует на существующие ограничения, а активно формирует траекторию, минимизируя риски и повышая эффективность. В конечном итоге, подобно архитектуре, которая откладывает хаос, BAP-SRL откладывает потенциальные столкновения, обеспечивая более плавное и безопасное движение.
Что дальше?
Представленная работа, стремясь к решению проблемы безопасного планирования движения в условиях смешанного трафика, лишь добавляет ещё один слой сложности в уже запутанную сеть зависимостей. Был создан алгоритм, адаптирующий приоритеты, но не отменена фундаментальная истина: каждая оптимизация — это предсказание будущей точки отказа. Система становится всё более хрупкой, всё более подверженной каскадным сбоям, даже если сейчас демонстрирует впечатляющие результаты в симуляции.
Разделение задачи на подзадачи, как это реализовано в подходе BAP-SRL, не устраняет, а лишь маскирует системные риски. Мы разделили систему, но не судьбу. Конфликты, разрешённые на одном уровне, неизбежно возникнут на другом, в новых, ещё более изощрённых формах. Следующим шагом видится не поиск идеального алгоритма разрешения конфликтов, а исследование механизмов самовосстановления и адаптации к непредсказуемым изменениям в окружающей среде.
Будущие исследования должны сместить фокус с «безопасности» как статического свойства, на «устойчивость» как динамический процесс. Необходимо изучать, как системы могут учиться на своих ошибках, предсказывать и смягчать последствия сбоев, и, самое главное, как они могут деградировать предсказуемым образом, не приводя к катастрофическим последствиям. Всё связанное когда-нибудь упадёт синхронно — задача состоит в том, чтобы сделать этот процесс контролируемым.
Оригинал статьи: https://arxiv.org/pdf/2601.21679.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Газовый кризис и валютные риски: что ждет российский рынок? (14.03.2026 18:32)
- Российский рынок: Ожидание ставки, стабилизация рубля и рост прибылей компаний (20.03.2026 02:32)
- Будущее WLD: прогноз цен на криптовалюту WLD
- Биткоин в турбулентности: Макрофакторы, волатильность и риски коррекции (20.03.2026 10:45)
- Аэрофлот акции прогноз. Цена AFLT
- О нет! Стратегический запас биткоинов сталкивается с крахом! 😱 (См. график №4)
- Самые умные хай-йелдовые промежуточные акции, которые стоит купить сейчас за $2,000
- Как акции Meta могут достичь отметки в $2 триллиона
2026-02-01 13:09