Командная Работа в Неопределенности: Новая Стратегия Обучения Агентов
Исследователи предлагают новый подход к обучению мультиагентных систем, позволяющий им эффективно действовать в условиях непредсказуемой среды.
Исследователи предлагают новый подход к обучению мультиагентных систем, позволяющий им эффективно действовать в условиях непредсказуемой среды.

Исследователи предлагают инновационный метод выравнивания диффузионных моделей, переосмысливающий оптимизацию вознаграждения как задачу минимизации дисперсии весов важности.
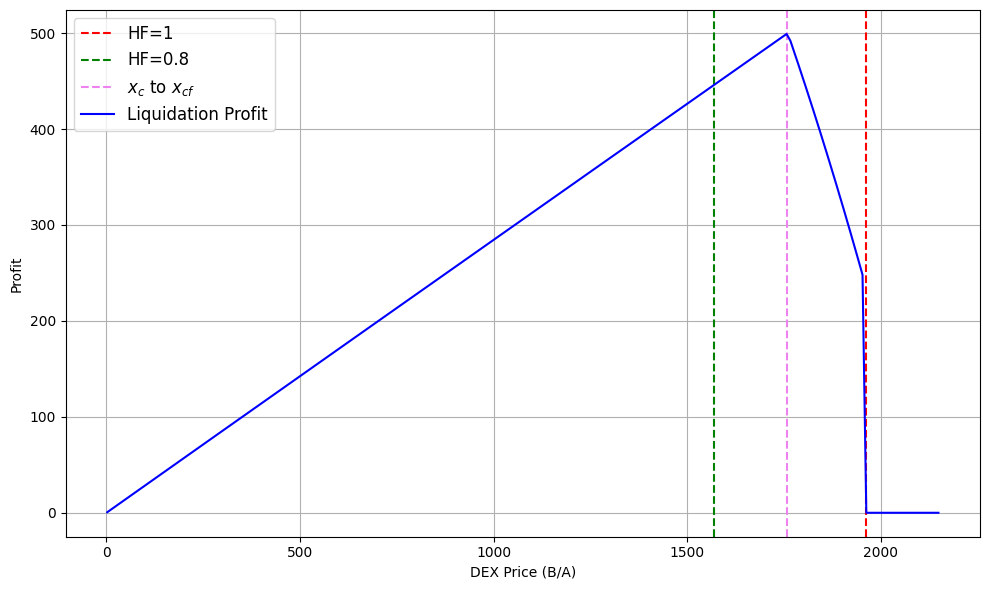
Новое исследование показывает, как правильно настроенные комиссии за транзакции могут эффективно предотвратить манипуляции с ценами в децентрализованных финансовых протоколах.
В статье представлен новый подход к доказательству существования, характеристике и разработке алгоритмов обучения для равновесий Нэша в контексте Марковских игр и их обобщений.
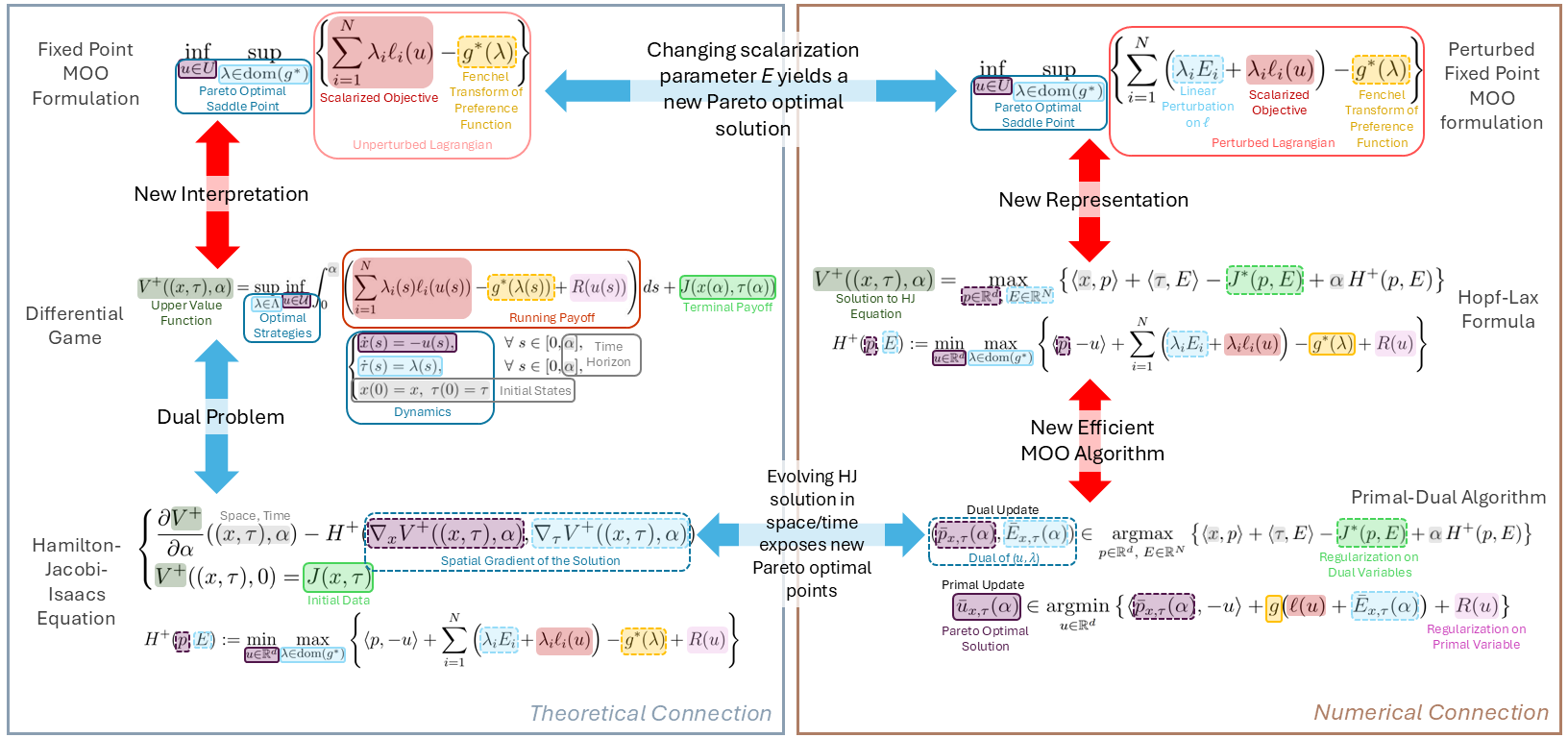
Исследователи предлагают оригинальный алгоритм, использующий принципы дифференциальных игр, для эффективного поиска решений на невыпуклых Парето-фронтах.