Оптимизация онлайн: снижение сложности стохастических методов Ньютона
Новый алгоритм позволяет существенно сократить вычислительные затраты при онлайн-оптимизации, приближаясь по эффективности к методам первого порядка.
Новый алгоритм позволяет существенно сократить вычислительные затраты при онлайн-оптимизации, приближаясь по эффективности к методам первого порядка.
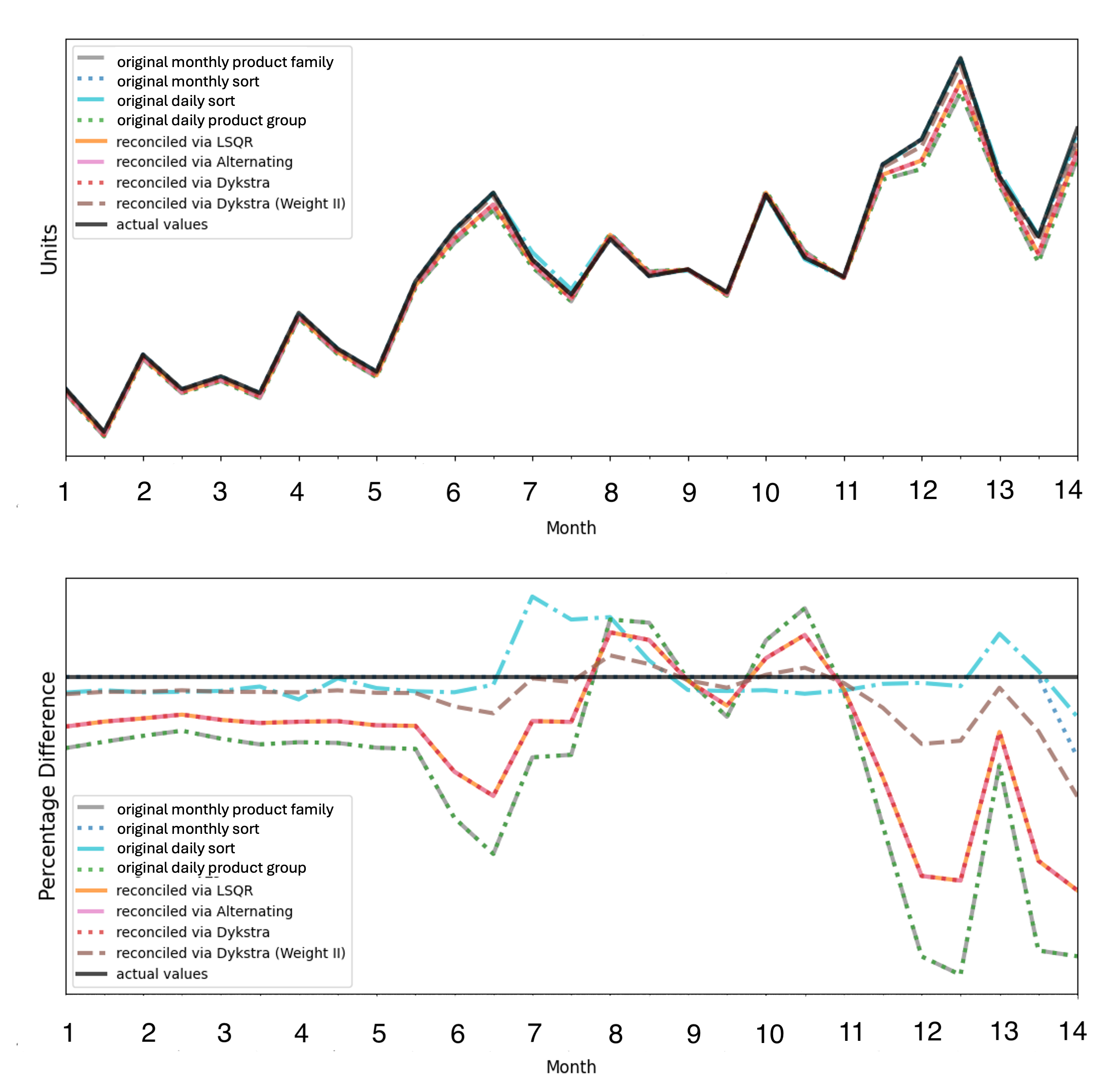
Новые алгоритмы позволяют эффективно решать задачи согласования прогнозов в условиях огромных объемов данных, типичных для современной розничной торговли.
![В процессе обучения многослойный перцептрон (MLP) формирует стратегию [latex]\pi_{\theta}[/latex] посредством минимизации трех различных функций потерь, после чего, на основе полученной стратегии и динамики системы игрока 2, аппроксимируется наилучший ответ [latex]\widehat{\mathcal{B}}_{2}[/latex], что позволяет решить предложенное упрощенное условие Каруша-Куна-Таккера (KKT) с использованием суррогата этого ответа.](https://arxiv.org/html/2602.05324v1/x1.png)
Исследователи предлагают метод разложения динамических игр, позволяющий оптимизировать стратегии для роботов в условиях асимметричной информации.
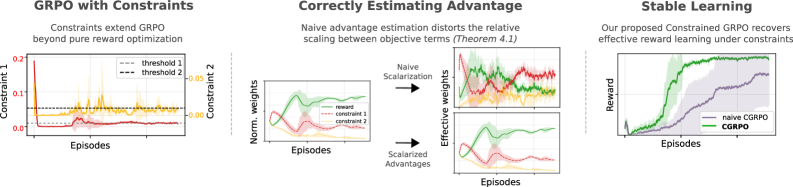
В статье представлена методика, позволяющая эффективно накладывать ограничения на поведение агента в процессе обучения с подкреплением, сохраняя при этом баланс между различными ограничениями.
![Влияние выбросов на оценку порогового значения [latex]uu[/latex] проявляется в последующем искажении оценок параметров масштаба σ и формы ξ обобщенного распределения Парето, что демонстрирует чувствительность модели к качеству исходных данных и необходимость предварительной обработки для исключения нерепрезентативных наблюдений.](https://arxiv.org/html/2602.05351v1/x1.png)
Новая модель позволяет точнее оценивать риски, учитывая влияние обычных данных на анализ редких, но критически важных событий.