Обучение языковых моделей с подкреплением: как избежать «трюков» и добиться стабильности
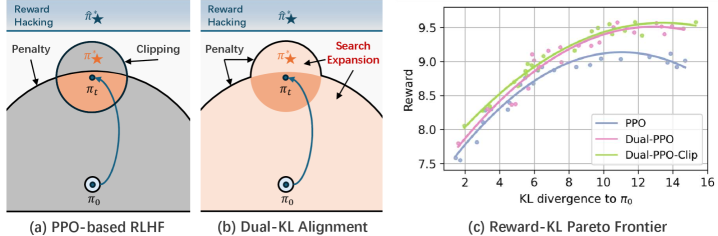
Новая работа предлагает подход к обучению больших языковых моделей с использованием обратной связи от человека, который позволяет избежать манипуляций с системой вознаграждения и обеспечивает более устойчивый процесс обучения.
![При фиксированном объеме поставок [latex] \bar{Q} = 150 [/latex] в сто городах, свободный рынок обеспечивает плавное распределение товаров, в то время как ценовое регулирование приводит к насыщению наиболее дешевых городов и оставлению около тридцати без обслуживания, демонстрируя неэффективность административного контроля над распределением ресурсов.](https://arxiv.org/html/2602.12066v1/x4.png)
![Циклическая модель марковского процесса принятия решений (MDP) с [latex]K=3[/latex] стадиями рассматривается, где каждая стадия [latex]\mathcal{M}_{k}[/latex] состоит из [latex]\tau_{k}[/latex] шагов, соединенных переходами [latex]\phi_{k}[/latex] с коэффициентами дисконтирования [latex]\gamma_{k}[/latex], что позволяет оценить оптимальную Q-функцию [latex]Q_{k}^{\ast}[/latex] для каждой стадии путем максимизации ожидаемой дисконтированной награды в бесконечном цикле, начиная с любой стадии [latex]k[/latex].](https://arxiv.org/html/2602.11679v1/x1.png)