Устойчивость пенсионных фондов: новый подход к управлению рисками
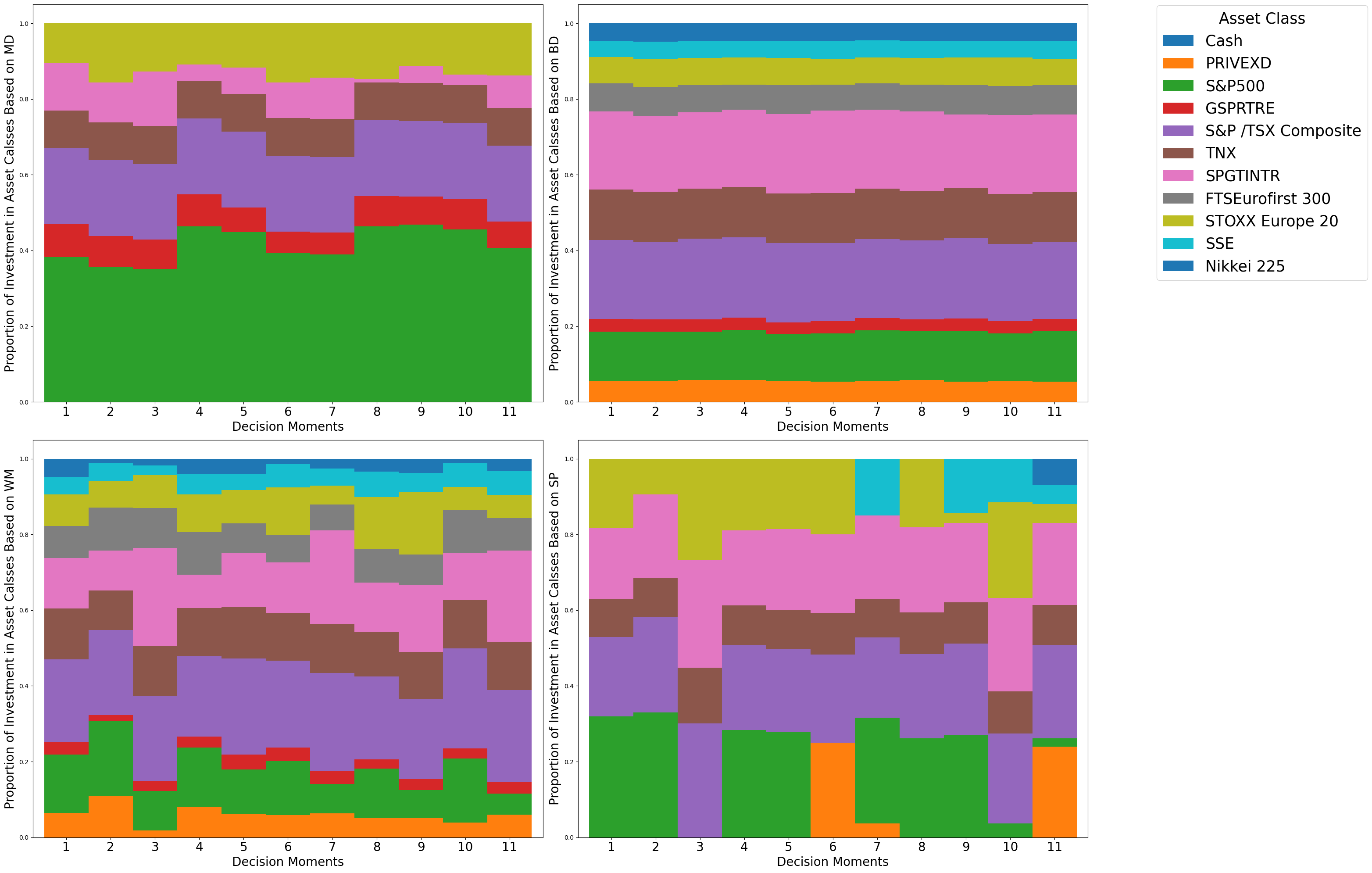
В статье представлен инновационный метод повышения стабильности пенсионных накоплений за счет оптимизации управления активами и обязательствами.
В статье представлен инновационный метод повышения стабильности пенсионных накоплений за счет оптимизации управления активами и обязательствами.
![Различные генераторы расхождений, используемые в алгоритме DPO - [latex]t\logt[/latex], [latex]\chi\chi PO(\tfrac{1}{2}(t-1)^{2}+t\log t)[/latex] и [latex]SquaredPO(\tfrac{1}{2}(\log t)^{2})[/latex] - демонстрируют различную устойчивость к смещению правдоподобия, причём функция [latex]SquaredPO[/latex], имеющая глобальный минимум при [latex]t=1[/latex], оказывается наиболее устойчивой к подобным искажениям.](https://arxiv.org/html/2602.06788v1/figures/fs.png)
Новое исследование предлагает расширенный класс математических функций, позволяющих более эффективно и стабильно настраивать языковые модели в соответствии с человеческими оценками.
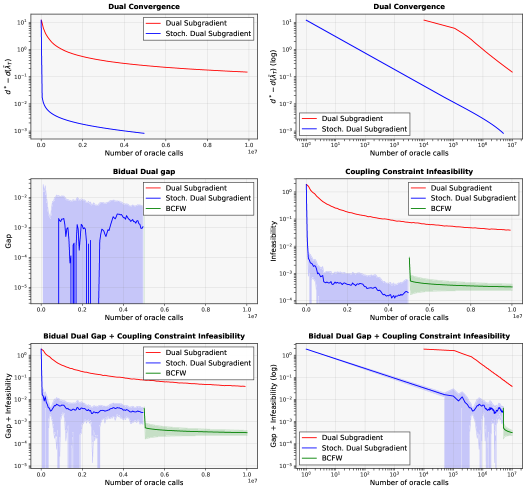
Исследователи предлагают инновационный подход к решению крупномасштабных задач разделяемой оптимизации, обеспечивающий более быструю сходимость даже для невыпуклых функций.
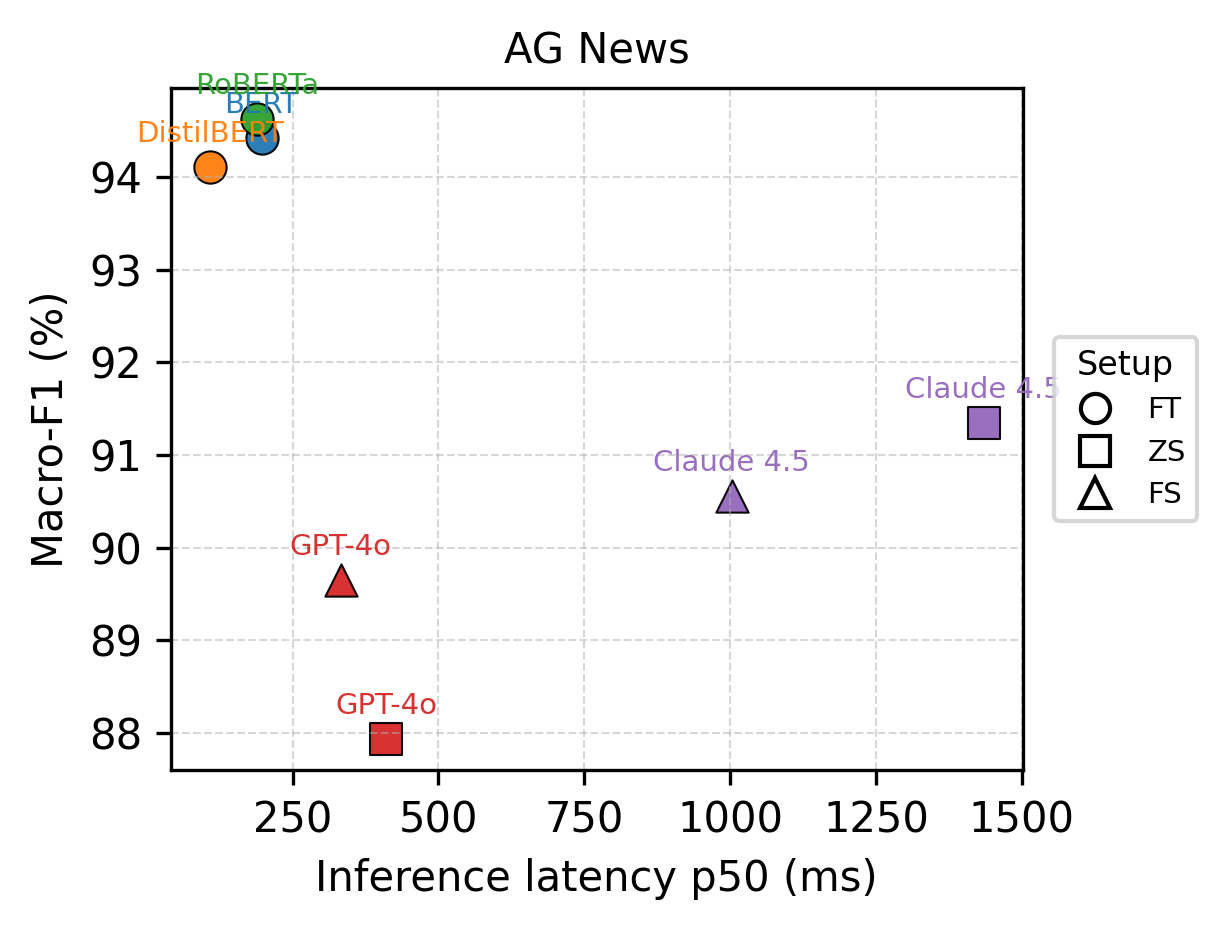
Новое исследование показывает, как оптимизировать затраты и производительность при решении задач классификации текста в реальных условиях.
Новое исследование показывает, что многие алгоритмы многокритериальной оптимизации демонстрируют систематические искажения в поиске, зависящие от расположения в пространстве решений.