Устойчивое обучение: как привязать языковые модели к реальности
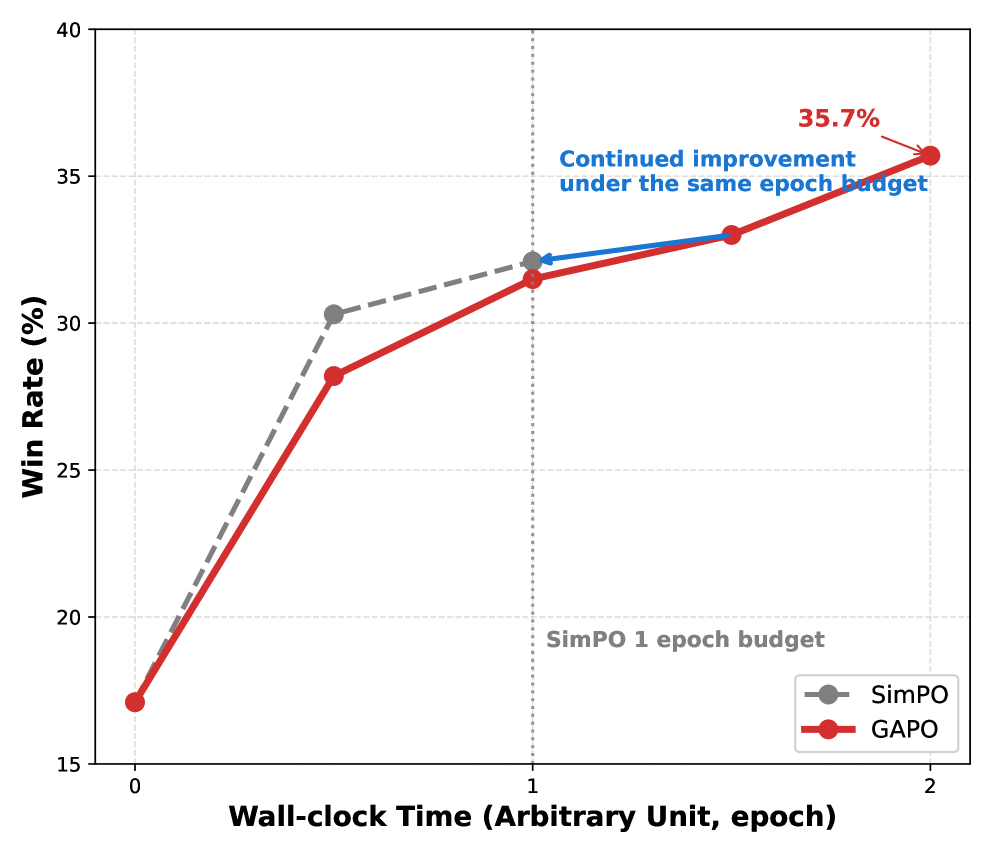
Новый подход позволяет стабилизировать процесс обучения больших языковых моделей на основе предпочтений человека, делая их более надежными и соответствующими ожиданиям.
Новый подход позволяет стабилизировать процесс обучения больших языковых моделей на основе предпочтений человека, делая их более надежными и соответствующими ожиданиям.
![Наблюдается эволюция энтропии как в неконструированном, так и в случае с ограничением по CBF, при этом порог энтропии установлен на уровне [latex]\epsilon = 3[/latex], что демонстрирует динамику изменения неопределённости системы в зависимости от наложенных ограничений.](https://arxiv.org/html/2602.05011v1/x4.png)
Новый подход к управлению роем роботов гарантирует соблюдение ограничений безопасности и стабильности благодаря интеграции макроскопических ограничений и децентрализованных алгоритмов управления.
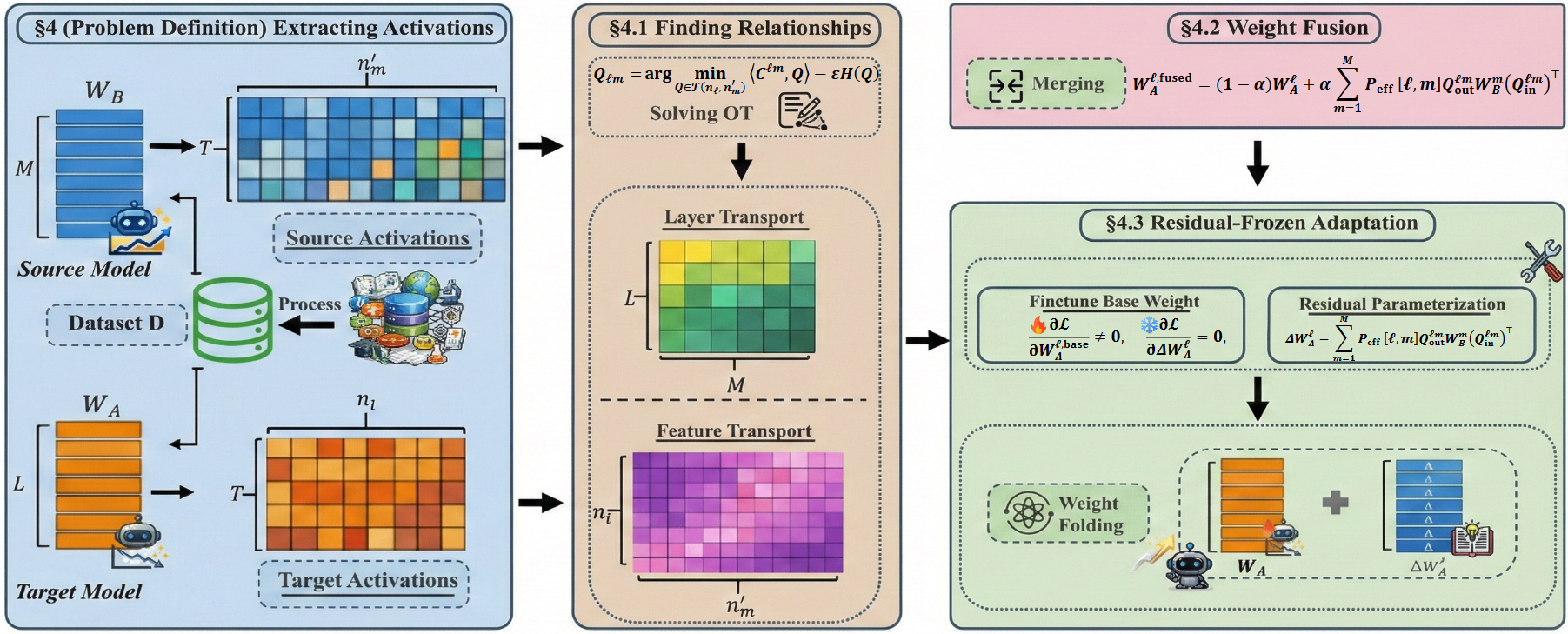
Новый метод позволяет эффективно объединять большие языковые модели, даже если они построены на разных архитектурах, расширяя возможности для малоресурсных языков.
В новой работе исследователи предлагают модель, учитывающую социальные и когнитивные факторы, для разработки справедливых стратегий стимулирования принятия инноваций в условиях неопределенности.
![Алгоритм 1 и метод градиентного спуска (EG) демонстрируют свою эффективность при решении задачи поиска контрпримера (см. (E.1)), в то время как алгоритм 4 и алгоритм из [38] успешно справляются с задачей оптимизации без ограничений (E.2) при наличии операторного шума, распределенного по закону Стьюдента и Лапласа.](https://arxiv.org/html/2602.05531v1/results_laplace_n7_alpha0_12_df116.png)
В статье представлены эффективные алгоритмы, позволяющие решать стохастические вариационные неравенства без предположения об ограниченной дисперсии, расширяя область их применимости.