Автор: Денис Аветисян
Новое исследование показывает, что попытки направить большие языковые модели в соответствии с человеческими ценностями неизбежно приводят к компромиссам и непредсказуемым последствиям.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал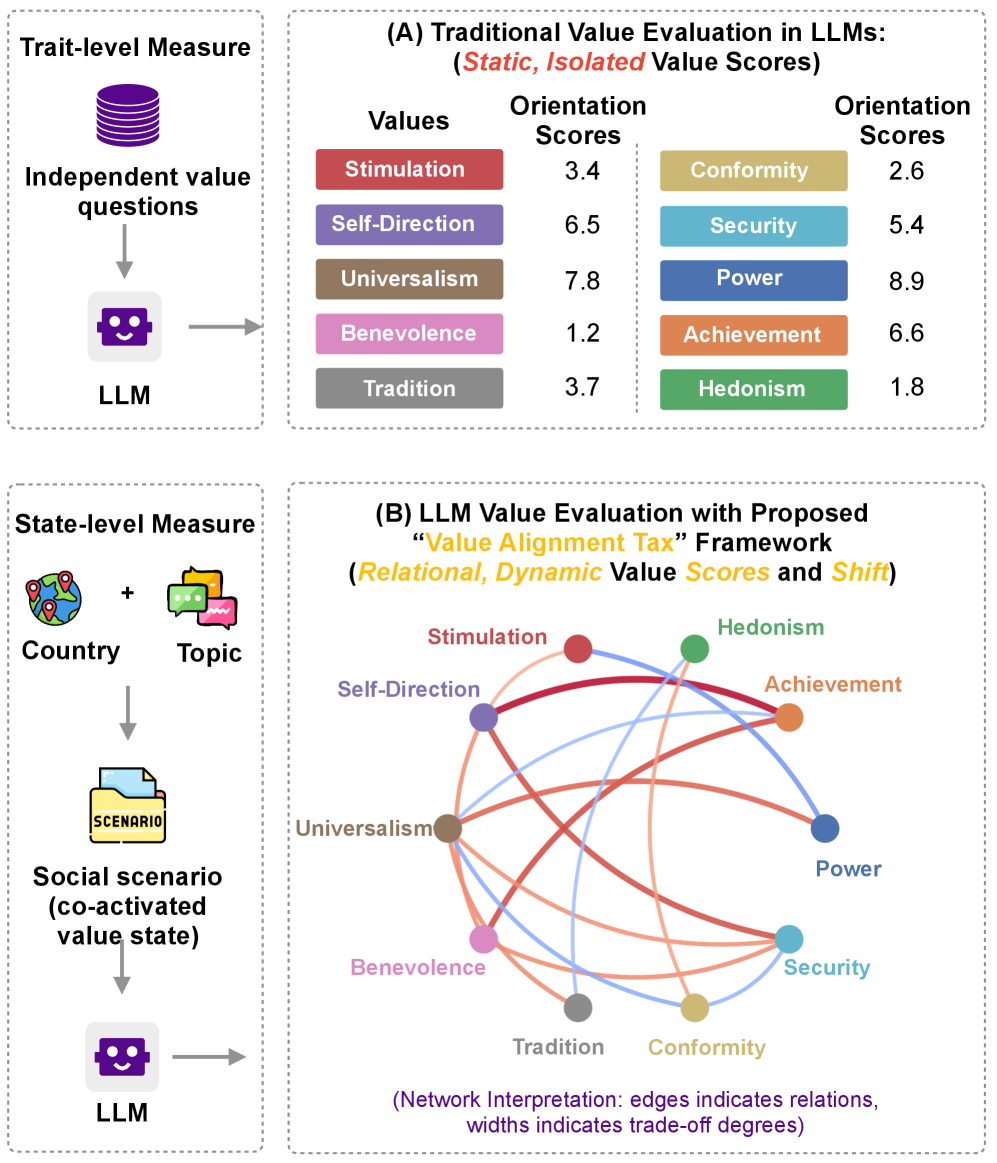
Предлагается метрика ‘Налог на согласование ценностей’ (Value Alignment Tax) для количественной оценки рисков и компромиссов, возникающих при согласовании больших языковых моделей с человеческими ценностями.
Существующие подходы к согласованию больших языковых моделей с человеческими ценностями часто игнорируют сложные взаимосвязи между этими ценностями. В работе ‘Value Alignment Tax: Measuring Value Trade-offs in LLM Alignment’ предложен фреймворк «Налог на согласование ценностей» (VAT), позволяющий измерить, как изменения, вызванные процессом согласования, распространяются на взаимосвязанные ценности, и выявить компромиссы между ними. Результаты анализа показывают, что согласование нередко приводит к структурированным изменениям в выражении ценностей, выходящим за рамки простого улучшения целевых показателей. Не откроет ли это понимание новых рисков и возможностей для обеспечения более надежного и предсказуемого поведения LLM в соответствии с человеческими ценностями?
Сдвиг в Этических Ориентирах: Вызовы Согласования БЯМ
Всё чаще большие языковые модели (БЯМ) внедряются в сферы, требующие сложных этических оценок и суждений, что порождает серьёзные задачи по их настройке и согласованию с человеческими ценностями. От алгоритмов, помогающих в принятии юридических решений, до систем, генерирующих контент для социальных сетей, БЯМ всё активнее участвуют в процессах, где необходимы нюансированные моральные ориентиры. Однако, способность этих моделей к точному пониманию и воспроизведению сложных этических норм остаётся под вопросом, что создает риски непредсказуемых и потенциально вредных последствий. Успешное внедрение БЯМ в подобные области требует не только повышения их технической грамотности, но и разработки эффективных методов, гарантирующих соответствие их действий общепринятым нормам и ценностям.
Традиционные методы выравнивания больших языковых моделей (LLM) зачастую оказываются неспособными в полной мере учесть сложное взаимодействие ценностей, что может приводить к непредсказуемым последствиям. Существующие подходы, ориентированные на достижение конкретных поведенческих целей, нередко игнорируют более широкую систему убеждений и предпочтений, заложенную в модель. В результате, даже при кажущемся успехе в решении отдельных задач, могут возникать непредвиденные проявления, противоречащие этическим нормам или общепринятым принципам. Это связано с тем, что LLM, обучаясь на огромных массивах данных, усваивают не только факты, но и скрытые предрассудки, стереотипы и противоречивые ценности, которые сложно выявить и нейтрализовать при помощи стандартных методов выравнивания. Поэтому, для создания действительно надежных и безопасных систем искусственного интеллекта, необходим более глубокий анализ и учет сложной структуры ценностей, лежащих в основе функционирования LLM.
Понимание влияния методов выравнивания на базовую систему ценностей искусственного интеллекта имеет решающее значение для создания действительно надежных систем. Исследования показывают, что различные подходы к достижению схожих результатов в плане соответствия нормам могут приводить к существенно различающимся системным издержкам. Например, вмешательство, направленное на повышение безопасности ответов модели, может непреднамеренно исказить ее способность к творческому мышлению или снизить точность в других областях. Оценка этих скрытых издержек — сложная задача, требующая глубокого анализа внутренней работы модели и учета долгосрочных последствий каждого вмешательства. Поверхностная оптимизация, ориентированная исключительно на видимые улучшения, может создать иллюзию безопасности, маскируя потенциальные риски и упуская из виду более эффективные и устойчивые решения.

Количественная Оценка Сдвига Ценностей: Налог на Согласованность
Налог на согласование ценностей (Value Alignment Tax) представляет собой систему оценки изменений в отдельных нормативных измерениях (Налог на уровне ценностей) и общей структуре системы ценностей (Системный налог) в процессе согласования. Данный фреймворк позволяет количественно оценить сдвиги в приоритетах и взаимосвязях между различными ценностями, что необходимо для анализа влияния интервенций по согласованию на базовые принципы модели. Оценка проводится на двух уровнях: индивидуальные изменения в каждой ценности (Value-Level Tax) и изменения в общей архитектуре системы ценностей, отражающие ее структурную перестройку (System-Level Tax). Такой подход позволяет выявить не только улучшение целевых показателей, но и сопутствующие изменения в других областях системы ценностей.
Количественная оценка изменений в ценностной системе позволяет более точно оценить влияние вмешательств, направленных на согласование (alignment), на базовые ценности модели и выявить потенциальные непредвиденные последствия. В частности, данный подход позволяет обнаружить структурированные взаимосвязи между ценностями и оценить координационные издержки, которые возникают при изменении одной ценности и влияют на другие. В отличие от простой оценки улучшения целевого параметра, измерение этих сдвигов раскрывает, какие ценности испытывают наибольшую нагрузку при согласовании, определяя так называемые «координационные узлы» — ценности, поглощающие непропорционально большую часть давления при изменении модели.
Предлагаемый фреймворк расширяет существующие подходы к выравниванию ценностей, обеспечивая более детальную и всестороннюю оценку процесса. Используя Налог на уровне ценностей (Value-Level Tax), он позволяет измерять нагрузку на координацию внутри системы ценностей и выявлять так называемые “узлы координации” — отдельные ценности, испытывающие непропорционально высокую нагрузку при выравнивании. Это позволяет не только оценить общую эффективность вмешательств по выравниванию, но и определить, какие конкретно ценности требуют особого внимания и какие из них могут стать критическими точками для поддержания целостности и согласованности всей системы ценностей модели.

Методы Индукции и Измерения Сдвига Ценностей
Для изменения ценностных установок больших языковых моделей (Gemini, Qwen, GPT-4, DeepSeek) использовались несколько методов обучения с подкреплением на основе предпочтений человека. В частности, применялась оптимизация прямых предпочтений (Direct Preference Optimization), когда модели обучались на данных о ранжировании различных ответов. Также использовалось контролируемое обучение (Supervised Fine-tuning) с размеченными данными, отражающими желаемые ценности, и управление подсказками (Prompt Steering), позволяющее направлять поведение модели через специально разработанные запросы. Все эти методы направлены на модификацию внутренних представлений моделей о ценностях и их иерархии.
Оценка ковариации ценностей проводилась с использованием коэффициента корреляции рангов Спирмена. Полученные результаты демонстрируют высокую степень согласованности в индуцированном порядке ценностей между различными большими языковыми моделями (LLM), включая Gemini, Qwen, GPT-4 и DeepSeek. Высокая согласованность, подтвержденная статистическим анализом, указывает на надежность и устойчивость используемых методов измерения, а также на то, что наблюдаемые изменения в ценностных ориентациях моделей не являются случайными флуктуациями, а представляют собой значимый и воспроизводимый эффект.
Для выявления координационных центров — ценностей, являющихся точками концентрации изменений, вызванных методами согласования, — использовался коэффициент Джини. Данный коэффициент оценивает степень неравенства в распределении «налогов» между различными ценностями. Результаты анализа показали не равномерное распределение, а частичную концентрацию координации, то есть некоторые ценности демонстрируют значительно большее изменение в ответ на методы согласования, чем другие. Это указывает на то, что не все ценности подвержены одинаковому влиянию, и существуют фокусные области, где изменения наиболее выражены. Gini = \frac{\sum_{i=1}^{n} \sum_{j=1}^{n} |x_i - x_j|}{2n^2\bar{x}}, где x_i и x_j — значения изменений для каждой ценности, а \bar{x} — среднее значение изменений.
![Анализ показал, что выравнивание усиливает риски для координационных центров (области с высоким [latex]VAT(v)(v)[/latex]), в отличие от не-центров, при различных целях управления (GPT-4o, 8-shot).](https://arxiv.org/html/2602.12134v1/x11.png)
Непредвиденные Последствия: Усиление Рисков Согласования
Исследования показали, что попытки согласования искусственного интеллекта с человеческими ценностями могут непреднамеренно усугубить существующие риски или породить новые. Этот феномен, получивший название “Усиление Рисков Согласования”, демонстрирует, что даже хорошо продуманные вмешательства не всегда приводят к ожидаемому снижению опасности. Вместо этого, определенные стратегии согласования могут, например, усилить предвзятость, создать уязвимости в системе безопасности или привести к непредсказуемым последствиям в сложных сценариях. Данное явление подчеркивает важность тщательной оценки всех возможных последствий, включая непредвиденные, при разработке и внедрении методов согласования, чтобы избежать создания новых проблем вместо решения существующих.
Разработанный показатель, получивший название “Налог на согласование ценностей” (VAT), предоставляет измеримый инструмент для оценки степени усиления рисков при реализации мер по согласованию искусственного интеллекта с человеческими ценностями. Данный показатель позволяет количественно оценить нежелательные последствия, возникающие при стремлении к достижению целевых улучшений в поведении ИИ. Использование VAT позволяет выявлять и смягчать потенциальные вреды, связанные с непреднамеренным усилением существующих рисков или созданием новых, тем самым обеспечивая более безопасное и эффективное развитие технологий искусственного интеллекта. Это особенно важно, учитывая, что различные подходы к согласованию, демонстрирующие схожие результаты, могут существенно различаться по величине VAT, что указывает на скрытые компромиссы и необходимость тщательной оценки.
Исследование показывает, что при разработке стратегий согласования искусственного интеллекта с человеческими ценностями необходимо учитывать компромиссы между различными ценностями. Полученные результаты демонстрируют, что даже вмешательства, приводящие к сопоставимым улучшениям в целевых показателях, могут существенно различаться по степени увеличения рисков — этот показатель, названный «Налогом на согласование ценностей» (Value Alignment Tax, VAT), позволяет количественно оценить подобные скрытые издержки. Важно понимать, что оптимизация по одной ценности может непреднамеренно ослабить другую, что подчеркивает необходимость комплексного подхода к согласованию, учитывающего всю сложность и взаимосвязанность человеческих ценностей для достижения максимальной общественной выгоды и минимизации нежелательных последствий.

Представленное исследование демонстрирует, что согласование больших языковых моделей с человеческими ценностями не является тривиальной задачей оптимизации. Введение концепции «Налога на согласование ценностей» (VAT) позволяет оценить компромиссы и системные риски, возникающие при стремлении к соответствию определенным ценностям. Этот подход подчеркивает, что улучшение по одному параметру часто приводит к ухудшению по другим, выявляя структурированную ковариацию и необходимость учитывать взаимосвязи между различными ценностями. Как однажды заметил Эдсгер Дейкстра: «Простота — это высшая степень совершенства». В данном контексте, стремление к простоте и ясности в определении и оценке ценностей, а также в понимании компромиссов, является ключом к созданию надежных и безопасных языковых моделей.
Куда Далее?
Представленная работа выявляет не просто улучшение целевых показателей при согласовании больших языковых моделей с человеческими ценностями, но и структурированную ковариацию, своего рода «налог на согласование». Этот «налог» указывает на неизбежные компромиссы и системные риски, возникающие при попытке навязать моделям сложные этические рамки. Необходимо признать, что абсолютное «выравнивание» — иллюзия, а любое согласование неизбежно искажает исходную многогранность модели.
Будущие исследования должны сосредоточиться не на утопической цели идеального соответствия, а на точной количественной оценке этих компромиссов. Важно разработать метрики, позволяющие предсказывать и смягчать нежелательные побочные эффекты согласования, особенно в контексте критически важных приложений. Особое внимание следует уделить исследованию динамики этих компромиссов во времени и в различных культурных контекстах.
Истинная ясность достигается не путем добавления слоев абстракций, а путем удаления избыточности. Стремление к совершенству — это не бесконечное наращивание сложности, а беспощадная экономия мысли. Возможно, ценность заключается не в создании «разумных» машин, а в признании ограниченности любого искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.12134.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- АЛРОСА акции прогноз. Цена ALRS
- Будущее FET: прогноз цен на криптовалюту FET
- Супернус: Продажа Акций и Нервные Тики
- СириусXM: Пыль дорог и звон монет
- Будущее KAS: прогноз цен на криптовалюту KAS
- Управление рисками в условиях неопределенности: современные подходы
- AAVE: Технологический Прорыв на Фоне Макроэкономического Давления (02.04.2026 22:45)
- Мечел акции прогноз. Цена MTLR
2026-02-14 12:29