Автор: Денис Аветисян
Новый подход позволяет одновременно оптимизировать ценность, справедливость действий и справедливость результатов при принятии решений с помощью многоцелевой оптимизации.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал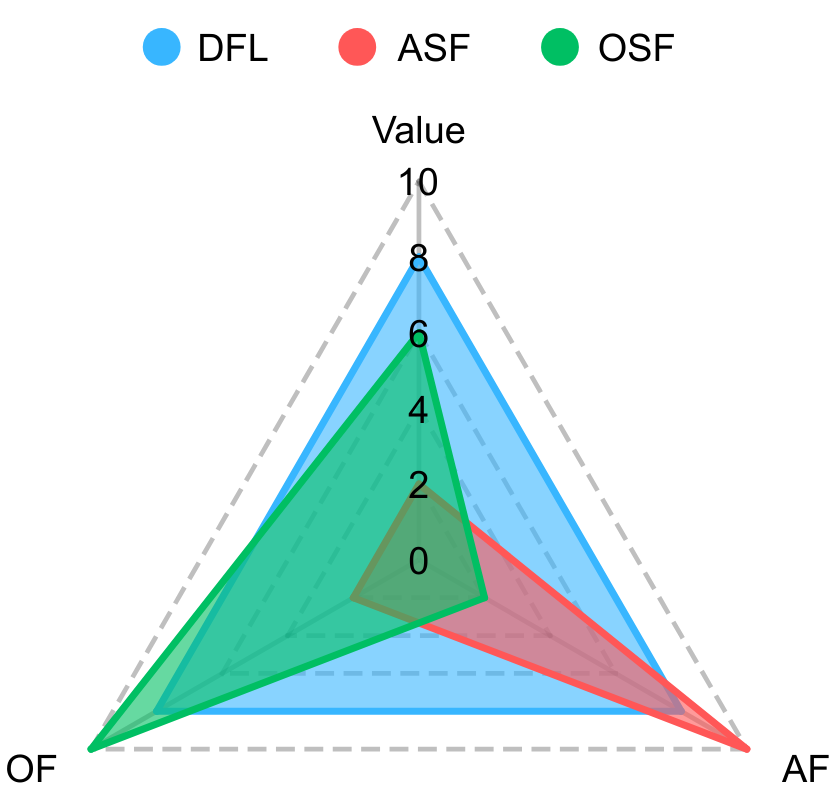
Предложена новая структура для одновременной оптимизации ценности, справедливости действий и справедливости результатов в процессе обучения политик.
Несмотря на растущее внимание к справедливости в машинном обучении, вопросы обеспечения равноправия в обучении с подкреплением остаются недостаточно изученными. В данной работе, посвященной теме ‘Double Fairness Policy Learning: Integrating Action Fairness and Outcome Fairness in Decision-making’, предложен новый подход к одновременной оптимизации как справедливости действий, так и справедливости последствий при обучении стратегий. Разработанная схема двойной справедливости (DFL) интегрирует эти цели в многоцелевую оптимизацию, позволяя находить решения Парето даже в невыпуклых пространствах. Способствует ли предложенный метод созданию более этичных и эффективных систем принятия решений в различных областях применения?
Вызов справедливой и эффективной политики
Традиционные методы обучения политик, как правило, ориентированы на максимизацию суммарной награды, не учитывая при этом различия в результатах для различных групп населения. Это может приводить к разработке политик, которые, хотя и эффективны в целом, оказываются несправедливыми по отношению к определенным слоям общества. Например, алгоритм, оптимизированный для повышения средней успеваемости в школе, может непреднамеренно усугубить неравенство, если не учитывать начальные условия и потребности учащихся из разных социально-экономических групп. Подобный подход, фокусирующийся исключительно на общей эффективности, игнорирует важность равноправия и может привести к снижению доверия к системам принятия решений и ухудшению благосостояния общества в целом. Таким образом, становится очевидной необходимость разработки новых подходов к обучению политик, которые бы учитывали не только суммарную награду, но и справедливость распределения выгод между различными группами.
Несмотря на благие намерения, существующие алгоритмы разработки политик часто оптимизируются исключительно под общую эффективность, игнорируя потенциальное неравенство в результатах для различных социальных групп. Такой подход может приводить к формированию дискриминационных политик, даже если подобный исход не был намеренным. Последствия подобной несправедливости выходят далеко за рамки материального ущерба, подрывая доверие граждан к институтам власти и снижая общее благосостояние. Потеря доверия, в свою очередь, может приводить к социальной напряженности, снижению гражданской активности и препятствовать реализации долгосрочных стратегий развития, что подчеркивает необходимость учитывать вопросы справедливости на всех этапах разработки и внедрения политических решений.
Достижение как высокой эффективности, так и справедливости в политиках требует тонкого подхода к определению и оптимизации целевых функций. Недавняя разработка демонстрирует новую основу, способную достичь сопоставимой ценностной функции с оптимальными политиками, при этом значительно улучшая показатели справедливости. Вместо простого максимизирования общей выгоды, предложенный фреймворк учитывает распределение выгод между различными группами, позволяя смягчить потенциальные дискриминационные эффекты, даже если они не были намеренными. Такой подход позволяет создавать политики, которые не только эффективны в достижении поставленных целей, но и обеспечивают более равномерное распределение преимуществ, укрепляя доверие и способствуя общественному благополучию. Данная методика представляет собой важный шаг к разработке более инклюзивных и социально ответственных систем принятия решений.
Многокритериальная оптимизация для проектирования политики
Многокритериальная оптимизация (MultiObjectiveOptimization) предоставляет структуру для согласования конкурирующих целей в процессе обучения политик. В отличие от традиционной оптимизации, где целью является максимизация или минимизация единственной функции полезности, многокритериальная оптимизация позволяет одновременно оптимизировать несколько критериев, которые могут быть противоречивыми. Это позволяет разработчикам политик явно учитывать компромиссы между различными целями, например, между эффективностью и безопасностью, или между краткосрочной и долгосрочной прибылью. Вместо поиска единственного «оптимального» решения, многокритериальная оптимизация стремится к определению множества Парето-оптимальных решений, каждое из которых представляет собой наилучший возможный компромисс между заданными критериями. Выбор конкретного решения из множества Парето-оптимальных осуществляется на основе предпочтений принимающего решение лица.
Поиск оптимальных решений в многоцелевых пространствах может быть вычислительно затратным, особенно при работе со сложными политиками. Сложность обусловлена экспоненциальным ростом числа возможных решений при увеличении числа оптимизируемых целей и параметров политики. Традиционные методы оптимизации, такие как градиентный спуск, могут столкнуться с проблемами локальных оптимумов или требовать значительных вычислительных ресурсов для исследования всего пространства решений. Это особенно актуально для задач обучения с подкреплением, где оценка политики требует большого количества симуляций или взаимодействия с окружающей средой, что усугубляет вычислительную сложность.
Методы, такие как лексикографическая взвешенная скаляризация Чебышева, обеспечивают эффективное исследование парето-фронта — множества не доминируемых решений. В рамках этого подхода, многокритериальная задача оптимизации сводится к однокритериальной путем взвешивания различных целей и последующего применения скалярной функции Чебышева. Лексикографический подход позволяет последовательно оптимизировать каждую цель, начиная с наиболее приоритетной, обеспечивая тем самым управляемое исследование пространства решений и выявление компромиссных вариантов, удовлетворяющих заданным критериям. В отличие от других методов, требующих полного перебора пространства, данная техника позволяет значительно снизить вычислительные затраты при поиске решений на парето-фронте, особенно в задачах с большим количеством целей и сложными ограничениями.
![В отличие от линейной скаляризации, не способной идентифицировать оптимальные решения в невыпуклых областях парето-фронта из-за отсутствия поддерживающих гиперплоскостей ([latex]Miettinen, 1999[/latex]), взвешенная скаляризация Чебышева позволяет находить все оптимальные решения, независимо от формы пространства целей (по материалам [latex]Lin et al., 2024[/latex]).](https://arxiv.org/html/2601.19186v1/x5.png)
DoubleFairnessLearning: Основа для справедливых результатов
DoubleFairnessLearning представляет собой расширение традиционного обучения с подкреплением, которое одновременно оптимизирует три ключевых компонента: справедливость действий (action fairness), справедливость результатов (outcome fairness) и общую ценность, определяемую функцией вознаграждения (RewardFunction). В отличие от стандартных методов, которые фокусируются исключительно на максимизации вознаграждения, DoubleFairnessLearning интегрирует метрики справедливости непосредственно в процесс оптимизации политики. Это позволяет генерировать политики, которые учитывают потенциальные предубеждения и стремятся к более равноправным результатам, одновременно обеспечивая высокую производительность. Оптимизация осуществляется путем совместного учета всех трех компонентов, что позволяет находить баланс между справедливостью и эффективностью.
В рамках DoubleFairnessLearning, метрики справедливости (как по действиям, так и по результатам) непосредственно включаются в процесс оптимизации политики обучения с подкреплением. Это достигается путем добавления компонентов, учитывающих отклонения от желаемой справедливости, в функцию потерь, которую алгоритм стремится минимизировать. В результате, получаемые политики менее склонны к воспроизведению существующих в данных систематических ошибок и предвзятостей, что подтверждается улучшением показателей справедливости как в выборе действий, так и в распределении итоговых результатов для различных групп пользователей. Такой подход позволяет разрабатывать более этичные и надежные системы, избегающие дискриминации и обеспечивающие более справедливое отношение ко всем.
В основе DoubleFairnessLearning лежит использование функции ценности ValueFunction, которая представляет собой ожидаемую награду за выполнение действия в определенном состоянии. Этот подход позволяет формализовать компромисс между справедливостью и производительностью, поскольку функция ценности может быть модифицирована для учета метрик справедливости наряду с традиционной функцией вознаграждения RewardFunction. Оптимизируя функцию ценности с учетом как справедливости (действия и результата), так и общей эффективности, DoubleFairnessLearning обеспечивает генерацию политик, которые демонстрируют повышенную устойчивость к предвзятостям и обеспечивают более этичное поведение в различных сценариях.
![Предложенный метод DFL демонстрирует улучшенные показатели справедливости действий ([latex]\Delta\\_{1}(\\pi)[/latex] - чем ниже, тем лучше) и результатов ([latex]\Delta\\_{2}(\\pi)[/latex] - чем ниже, тем лучше), а также более высокую ценность функции ([latex]V(\\pi)[/latex] - чем выше, тем лучше) в сравнении с альтернативными подходами, согласно принципу равных возможностей, что подтверждено усредненными результатами по 100 повторениям на тестовом наборе из 5000 примеров при [latex]K=10[/latex] и размере обучающей выборки 200.](https://arxiv.org/html/2601.19186v1/x1.png)
Демонстрация справедливости на практике
Применение алгоритма DoubleFairnessLearning к данным по искам о возмещении ущерба при ДТП продемонстрировало его способность снижать предвзятость при оценке страховых случаев. Исследование показало, что данный подход позволяет выявлять и корректировать систематические ошибки, возникающие из-за неявных предубеждений в данных или алгоритмах. В результате, система оценки становится более справедливой и объективной, обеспечивая более равномерное распределение выплат пострадавшим в зависимости от реального ущерба, а не от демографических или социальных факторов. Этот подход представляет собой значительный шаг к созданию более прозрачной и ответственной системы страхования, где решения принимаются на основе фактических данных и исключают дискриминацию.
Анализ данных об участии в программах предпринимательского обучения продемонстрировал потенциал разработанной системы для обеспечения равного доступа к возможностям для представителей меньшинств. Исследование выявило конкретную политику, направленную на поддержку участия в стажировках, которая позволила значительно сократить разрыв в вероятности получения стажировки для представителей меньшинств. До внедрения этой политики вероятность получения стажировки для данной группы была примерно на 20% ниже, чем у основной группы. После внедрения политики наблюдалось существенное улучшение, что свидетельствует об эффективности системы в создании более справедливых условий и расширении возможностей для представителей различных социальных групп.
Анализ причинно-следственных связей, интегрированный с предложенной системой, позволяет выйти за рамки простого выявления предвзятости и углубиться в понимание механизмов, определяющих справедливость или несправедливость в результатах реализации политик. Вместо констатации факта неравенства, методика позволяет установить, какие именно факторы приводят к неравномерному распределению возможностей или ресурсов. Например, исследование может показать, что кажущаяся предвзятость в процессе отбора на стажировки обусловлена не прямым дискриминационным отношением, а косвенными факторами, такими как неравный доступ к качественному образованию или недостаток информации о возможностях. Выявляя эти опосредованные причины, можно разработать более эффективные и целенаправленные стратегии для устранения несправедливости и обеспечения равных возможностей для всех заинтересованных сторон. Такой подход позволяет перейти от симптоматического лечения к устранению первопричин неравенства, что является ключевым для построения действительно справедливой системы.
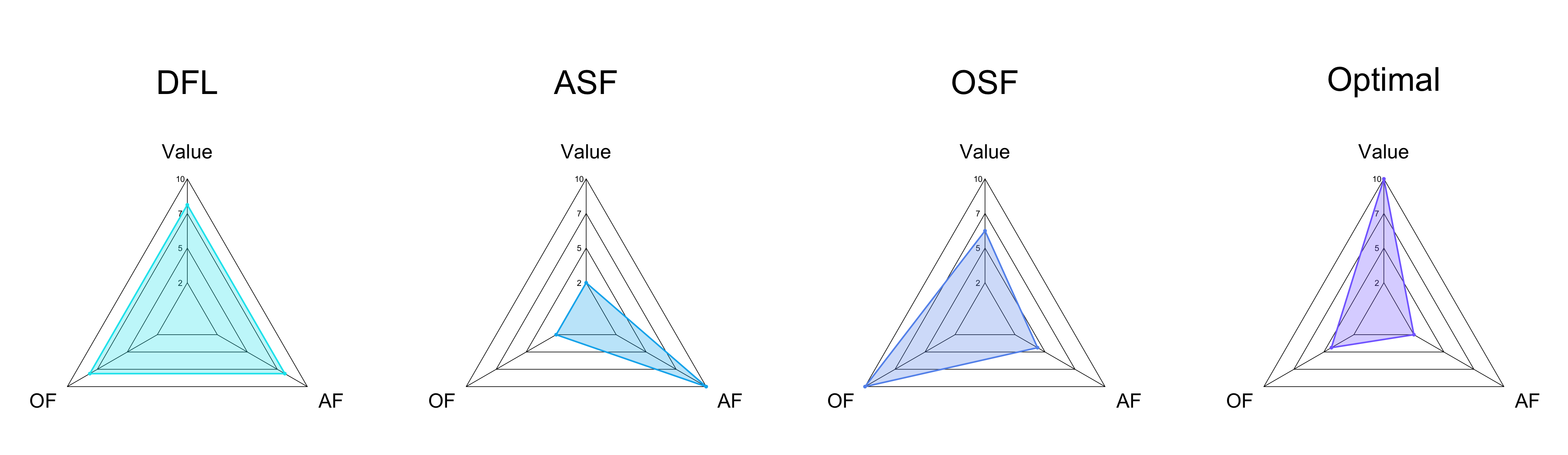
![Предложенный метод DFL демонстрирует лучшие показатели справедливости действий ([latex]\Delta\\_{1}(\\pi)[/latex], чем ниже, тем лучше) и результатов ([latex]\Delta\\_{2}(\\pi)[/latex], чем ниже, тем лучше), а также более высокую ценность функции ([latex]V(\\pi)[/latex]) по сравнению с другими подходами, что подтверждено средними значениями, полученными в результате 100 повторных экспериментов с [latex]K=10[/latex] и обучающей выборкой размером 200.](https://arxiv.org/html/2601.19186v1/x2.png)
Исследование демонстрирует, что стремление к справедливости в обучении политик требует комплексного подхода, выходящего за рамки простой оптимизации. Авторы предлагают учитывать как справедливость действий, так и справедливость результатов, что согласуется с идеей о том, что порядок возникает из локальных правил, а не из централизованного дизайна. Как заметила Симона де Бовуар: «Старость — это не состояние, которое нужно исправить, а фаза жизни, которую нужно прожить». Эта фраза, хотя и относится к иной сфере, отражает принцип принятия сложности и многогранности, который лежит в основе предложенного подхода к двойной справедливости. Оптимизация по нескольким целям, включая ценность, справедливость действий и справедливость результатов, позволяет найти компромиссные решения, соответствующие принципам Парето-оптимальности и обеспечивающие более сбалансированный и этичный процесс принятия решений.
Что дальше?
Представленная работа, стремясь к одновременной оптимизации ценности, справедливости действий и исходов, лишь обозначает сложность вопроса. Лес развивается без лесника, но с правилами света и воды. Попытки навязать “двойную справедливость” — это, по сути, попытка смоделировать эти правила, что неизбежно ведёт к упрощениям. Остается открытым вопрос, насколько вообще возможно создать алгоритм, способный учесть все нюансы контекста, влияющие на восприятие справедливости.
Настоящая проблема, вероятно, не в поиске идеальной метрики, а в понимании, что порядок — это результат локальных взаимодействий, а не директив. Дальнейшие исследования должны быть направлены не на глобальное навязывание справедливости, а на создание систем, способных адаптироваться к различным контекстам и учитывать индивидуальные предпочтения. Необходимо отойти от представления о “справедливом” решении как об абсолютной истине.
Вместо стремления к контролю, следует сосредоточиться на влиянии. Вместо создания “справедливых” алгоритмов, стоит разрабатывать инструменты, позволяющие пользователям самостоятельно оценивать и корректировать результаты, формируя таким образом систему, наиболее соответствующую их ценностям. Иллюзия контроля — опасна; влияние — реально.
Оригинал статьи: https://arxiv.org/pdf/2601.19186.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Газовый кризис и валютные риски: что ждет российский рынок? (14.03.2026 18:32)
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Будущее WLD: прогноз цен на криптовалюту WLD
- Нефть, Бюджет и Ставка: Что ждет Российский Рынок в Ближайшее Время? (12.03.2026 15:32)
- Cere Network: Раскрытие Систематического Мошенничества на $157 Миллионов и Связь с Новым AI-Проектом (17.03.2026 22:45)
- Является ли эта искусственная интеллект-транспортационная акция самой большой угрозой амбициям Теслы по созданию автономии?
- Будущее TRX: прогноз цен на криптовалюту TRX
- 5 Причин Купить Акции Energy Transfer, Как Будто Завтра Никогда Не Наступит
- 5 горячих акций, которые взорвут ваш портфель
2026-01-28 16:39