Автор: Денис Аветисян
Новый подход к разрежению весов и данных позволяет значительно повысить эффективность вычислений в моделях Mixture-of-Experts, особенно в задачах мультимодального обучения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал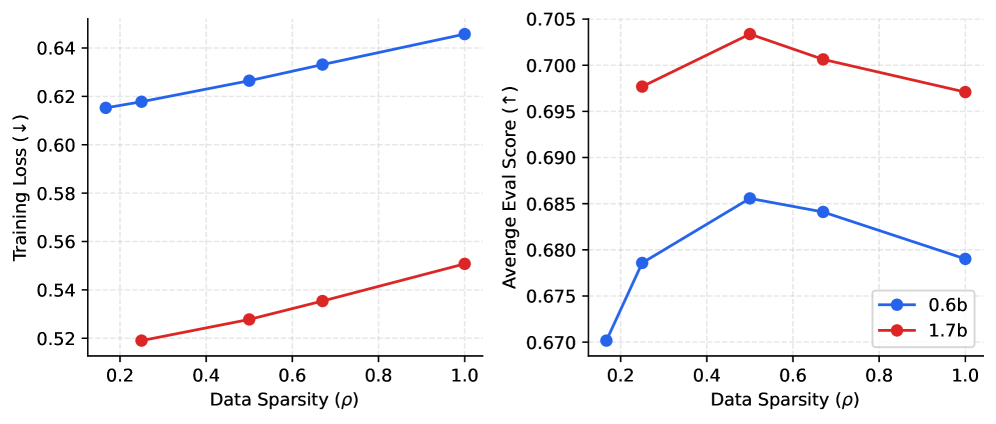
Комбинирование разреженности весов и данных с использованием «нулевых экспертов» улучшает распределение нагрузки и позволяет адаптировать вычислительные ресурсы в моделях с выбором токенов.
Несмотря на эффективность разреженных моделей экспертов (MoE) в снижении вычислительных затрат, достижение оптимальной производительности требует баланса между разреженностью весов и данных. В работе ‘Improving MoE Compute Efficiency by Composing Weight and Data Sparsity’ предлагается подход, сочетающий разреженность весов и данных посредством использования «нулевых» экспертов в архитектуре token-choice MoE. Показано, что такая композиция позволяет добиться более эффективного использования вычислительных ресурсов и адаптивного распределения нагрузки, особенно в задачах мультимодального обучения, таких как обработка изображений и текста. Сможет ли предложенный метод стать основой для создания еще более экономичных и производительных моделей экспертов в различных областях применения?
Преодоление Масштабируемости в Современных Языковых Моделях
Современные языковые модели, основанные на архитектуре Transformer, демонстрируют впечатляющие возможности, однако сталкиваются с серьезной проблемой масштабируемости. В основе этой сложности лежит квадратичная зависимость вычислительных затрат и потребления памяти от длины обрабатываемой последовательности текста. Это означает, что при увеличении длины текста вдвое, необходимые ресурсы растут в четыре раза, что существенно ограничивает возможности эффективной обработки длинных документов, книг или сложных диалогов. Такое ограничение препятствует применению этих моделей в задачах, требующих понимания и генерации текстов большой протяженности, и стимулирует поиск новых архитектур и алгоритмов, способных преодолеть это фундаментальное ограничение масштабируемости.
Ограничение масштабируемости современных языковых моделей напрямую влияет на вычислительные затраты и требования к памяти. С увеличением длины обрабатываемой последовательности, количество необходимых операций FLOPs (операций с плавающей точкой в секунду) растет квадратично, что делает обработку длинных текстов крайне ресурсоемкой. Это приводит к значительному увеличению требований к объему оперативной памяти и времени вычислений, создавая узкое место для решения сложных задач, таких как анализ больших массивов данных, перевод длинных текстов или генерация связных и последовательных повествований. В результате, дальнейшее увеличение масштаба моделей сталкивается с практическими ограничениями, связанными с доступностью вычислительных ресурсов и энергопотреблением.
Разреженность через Mixture-of-Experts: Новый Подход к Эффективности
Модель «Mixture-of-Experts» (MoE) реализует разреженность весов путем репликации полносвязных нейронных сетей в несколько «экспертов» и использования маршрутизатора (router) для выборочной активации подмножества экспертов для каждого токена входной последовательности. Вместо активации всей модели для каждого токена, MoE динамически выбирает небольшое число экспертов, наиболее подходящих для обработки конкретного токена. Это достигается за счет распределения токенов между различными экспертами, где каждый эксперт специализируется на определенной части входных данных. Таким образом, для обработки каждого токена используется лишь часть общего числа параметров модели, что значительно снижает вычислительные затраты и повышает эффективность.
Подход Mixture-of-Experts (MoE) значительно снижает вычислительную нагрузку за счет того, что не все параметры модели используются при обработке каждого входного токена. В традиционных плотных моделях все веса участвуют в каждом вычислении, что требует значительных ресурсов. MoE, напротив, активирует лишь подмножество экспертов (feed-forward сетей) для каждого токена, определяемое маршрутизатором. Это приводит к снижению количества необходимых операций умножения-сложения и, следовательно, к повышению эффективности и скорости обработки данных. Фактически, для обработки одного токена требуется лишь небольшая часть от общего числа параметров модели, что особенно важно при работе с большими языковыми моделями и огромными объемами данных.
Компонент маршрутизации (Router) в архитектуре Mixture-of-Experts играет ключевую роль в обеспечении эффективности и масштабируемости модели. Он анализирует каждый токен входной последовательности и направляет его к наиболее подходящим «экспертам» — специализированным нейронным сетям. Этот процесс назначения не случаен; маршрутизатор использует обучаемые веса для определения релевантности каждого эксперта для конкретного токена, что позволяет максимально задействовать параллельные вычисления. Выбор небольшого подмножества экспертов для обработки каждого токена значительно снижает вычислительную нагрузку и увеличивает пропускную способность системы, поскольку не все параметры модели активны одновременно.

Token-Choice MoE: Сохранение Причинности и Оптимизация Производительности
В отличие от других вариантов MoE, Token-Choice MoE позволяет каждому токену независимо выбирать экспертов для обработки, что особенно важно для авторегрессионных моделей, где сохранение причинно-следственной связи является ключевым требованием. В традиционных подходах, где эксперты выбираются для всей последовательности или ее части, нарушается порядок обработки токенов, что приводит к нестабильности обучения и снижению качества генерации. Token-Choice MoE, напротив, обеспечивает обработку каждого токена в соответствии с его контекстом и зависимостями, гарантируя соблюдение причинно-следственной связи и повышая стабильность и эффективность обучения модели.
В отличие от архитектур Expert-Choice MoE, где выбор экспертов осуществляется на уровне всей последовательности или блоков токенов, Token-Choice MoE позволяет каждому токену независимо выбирать экспертов для обработки. Такой подход критически важен для авторегрессионных моделей, поскольку архитектуры Expert-Choice нарушают причинно-следственную связь, передавая информацию от экспертов, обработавших предыдущие токены, к экспертам, отвечающим за текущий токен. Это может привести к нестабильности обучения, поскольку эксперты обучаются на данных, которые содержат информацию о будущих токенах. Token-Choice MoE устраняет эту проблему, обеспечивая, чтобы каждый токен обрабатывался экспертами, основываясь исключительно на предшествующей информации, сохраняя тем самым причинно-следственную структуру модели и стабилизируя процесс обучения.
Для повышения стабильности обучения в рамках Token-Choice MoE используются такие методы, как Z-Loss, минимизирующий расхождения в распределениях экспертов и предотвращающий их деградацию. Оптимизация вычислительной эффективности и снижения потребления памяти достигается за счет применения Grouped GEMM — метода, группирующего матричные умножения для повышения пропускной способности, — и Adaptive Checkpointing, позволяющего динамически сохранять промежуточные результаты вычислений и возобновлять обучение с минимальными затратами ресурсов. Эти техники позволяют эффективно масштабировать модели Token-Choice MoE, сохраняя при этом приемлемую скорость обучения и потребление памяти.
Разреженность данных в Token-Choice MoE достигается за счет стратегического использования «нулевых экспертов» (Null Experts). Этот подход позволяет эффективно внедрять разреженность без снижения выразительности модели. В отличие от традиционных методов разрежения, которые могут привести к потере информации, Null Experts позволяют модели выборочно исключать определенные эксперты для конкретных токенов, не влияя на общую способность модели к обучению и обобщению. В результате, наблюдается монотонное снижение функции потерь в процессе обучения на моделях различных масштабов, что подтверждает стабильность и эффективность данного метода для достижения разреженности.
В ходе экспериментов с данной архитектурой удалось достичь доли токенов, не требующих вычислений (zero-compute token ratio), превышающей 60% при более высоких уровнях разреженности. Это свидетельствует о значительном потенциале для снижения вычислительных затрат. Максимальные оценки производительности модели наблюдаются при уровне разреженности ρ=0.5. Данный результат указывает на возможность эффективного использования вычислительных ресурсов без существенной потери качества генерации, что особенно важно для масштабных языковых моделей.
![Эксперименты показывают, что разреженные модели экспертов (MoE) с использованием неактивных экспертов последовательно превосходят плотные модели на аналогичных вычислительных бюджетах, демонстрируя более низкие потери при обучении и более высокие оценки, при этом прозрачность маркеров указывает на уровень разреженности ρ, а метки отображают масштаб модели и ожидаемое количество активных экспертов [latex] \mathbb{E}[K] [/latex].](https://arxiv.org/html/2601.15370v1/x2.png)
Расширение на Визуально-Языковые Модели: Унифицированный Разреженный Подход
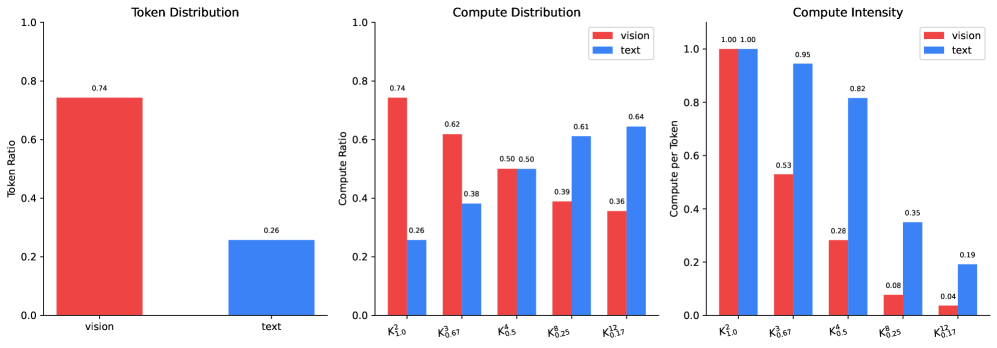
Визуально-языковые модели получают значительную выгоду от применения принципов Token-Choice MoE, что позволяет эффективно обрабатывать мультимодальные входные данные. В основе этого подхода лежит динамический выбор небольшого подмножества «экспертов» для обработки каждого токена, вместо того чтобы задействовать всю модель. Это приводит к существенному снижению вычислительной нагрузки и повышению скорости обработки, особенно при работе с большими объемами данных, такими как изображения и текст. Эффективность Token-Choice MoE заключается в способности модели концентрировать вычислительные ресурсы на наиболее релевантных частях входных данных, игнорируя менее важные, что позволяет достичь более высокой точности и скорости при сохранении приемлемого уровня сложности.
Принцип разреженности, лежащий в основе Token-Choice MoE, обнаруживает естественное соответствие с механизмами разреженного внимания, что позволяет значительно снизить вычислительные затраты. Вместо обработки всех возможных взаимодействий между элементами данных, модель фокусируется лишь на наиболее значимых, отбрасывая избыточную информацию. Такой подход не только ускоряет процесс обучения и инференса, но и позволяет эффективно использовать ограниченные ресурсы, особенно при работе с большими объемами мультимодальных данных. Комбинация этих двух методов создает синергетический эффект, позволяя моделям достигать высокой производительности, требуя при этом значительно меньше вычислительных операций FLOPs, чем традиционные плотные архитектуры.
Оптимизация распределения вычислительных ресурсов является ключевым фактором повышения эффективности современных моделей, работающих с визуальной и текстовой информацией. Исследования демонстрируют, что стратегическое выделение ресурсов позволяет достичь превосходных результатов при значительном снижении вычислительной нагрузки, измеряемой в FLOPs (операциях с плавающей точкой в секунду). Такой подход не только ускоряет обработку данных, но и делает возможным развертывание сложных моделей на устройствах с ограниченными ресурсами, открывая перспективы для широкого спектра практических применений, включая обработку изображений и видео в реальном времени, интеллектуальных ассистентов и автоматизированный анализ мультимедийного контента. Подобная экономия вычислительных ресурсов имеет решающее значение для масштабирования и внедрения этих технологий в реальные условия.
Исследование демонстрирует, что эффективная архитектура системы напрямую зависит от её внутренней структуры и способности к адаптации. Как и в случае с Mixture-of-Experts, где сочетание разреженности весов и данных через ‘нулевых экспертов’ оптимизирует вычислительную эффективность, важно избегать излишнего усложнения. Если система опирается на ‘костыли’, это указывает на то, что мы переусложнили её. Алан Тьюринг однажды заметил: «Иногда люди, у которых нет воображения, считают, что у меня его нет». Этот принцип применим и к разработке моделей: простота и ясность структуры позволяют добиться большей гибкости и эффективности, особенно в задачах мультимодального обучения, где адаптивное распределение ресурсов играет ключевую роль.
Куда Ведет Этот Путь?
Представленная работа демонстрирует, что совместное применение разреженности весов и данных, посредством концепции “нулевых экспертов”, открывает возможности для адаптивного распределения вычислительных ресурсов. Однако, элегантность подобного решения не должна затмевать более глубокие вопросы. Насколько эффективно подобный подход масштабируется на модели с существенно большим числом экспертов? Балансировка нагрузки, хоть и улучшена, остается сложной задачей, особенно при обработке данных, отличающихся по своей природе и сложности.
Попытки оптимизации вычислительной эффективности часто напоминают игру с тенями: улучшение в одной области может привести к неожиданным проблемам в другой. Очевидно, что будущее исследований лежит не только в разработке новых алгоритмов разреженности, но и в более глубоком понимании архитектуры моделей. Необходимо исследовать, как различные формы разреженности взаимодействуют друг с другом и как их можно динамически адаптировать к конкретным задачам и данным.
Особый интерес представляет возможность применения данной концепции в мультимодальном обучении. Способность модели адаптировать вычислительные ресурсы к различным модальностям данных — это шаг к созданию действительно гибких и эффективных систем. Но не стоит забывать, что истинная сложность заключается не в самом алгоритме, а в понимании того, как различные модальности взаимодействуют друг с другом и как их можно эффективно интегрировать в единую модель.
Оригинал статьи: https://arxiv.org/pdf/2601.15370.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Нефть, Геополитика и Рубль: Что ждет инвесторов в ближайшую неделю
- HSBC and Standard Chartered Lead Hong Kong’s Stablecoin Push as Wider Reforms Take Shape
- Газпром акции прогноз. Цена GAZP
- Российская экономика: Бюджетное давление, геополитика и новые экспортные возможности (11.03.2026 21:32)
- Театр энергетики: акции, которые обещают вечность
- Стоит ли покупать доллары за гривны сейчас или подождать?
- +160% За последний месяц, может ли компания OpenDoor стать следующей Carvana?
- После увеличения в цене на 112,700% с момента проведения IPO, стоит ли покупать акции Netflix, продавать их или держать до конца 2025 года?
- Стоит ли покупать акции AMD перед 5 августа?
2026-01-24 03:04