Автор: Денис Аветисян
Исследователи создали размеченную базу данных писем, чтобы оценить возможности современных языковых моделей в выявлении вредоносных рассылок и эмоционального воздействия.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал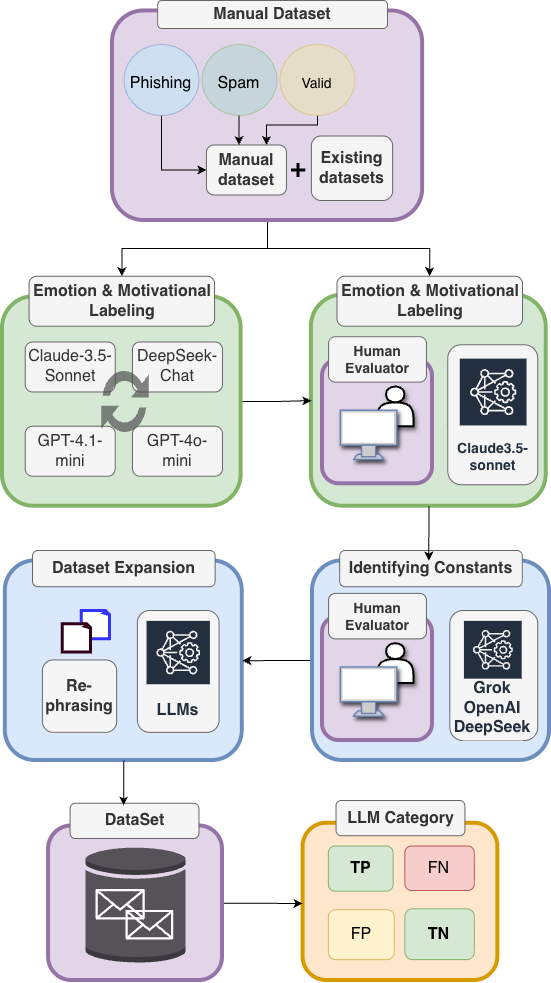
Представлен детально аннотированный набор данных электронных писем для тестирования эффективности моделей обработки естественного языка в задачах обнаружения фишинга и спама, с акцентом на анализ эмоциональной окраски и устойчивость к перефразировке.
Несмотря на прогресс в области кибербезопасности, фишинговые и спам-рассылки остаются серьезной угрозой, усугубляемой использованием генеративных моделей искусственного интеллекта. В данной работе, ‘Constructing and Benchmarking: a Labeled Email Dataset for Text-Based Phishing and Spam Detection Framework’, представлен всесторонний набор данных, включающий размеченные электронные письма, позволяющий различать фишинговые, спам и легитимные сообщения, а также выявлять признаки, созданные человеком или ИИ. Показано, что современные языковые модели способны эффективно обнаруживать вредоносные письма и анализировать эмоциональную окраску, даже при перефразировке текста, однако задача разграничения спама и легитимной корреспонденции остается сложной. Какие дополнительные инструменты и подходы необходимы для создания более надежных систем защиты электронной почты?
Эволюция Угроз и Вызовы Классификации
Традиционные методы фильтрации спама и выявления фишинговых атак сталкиваются с растущими трудностями, поскольку злоумышленники постоянно совершенствуют свои стратегии. Раньше достаточно было блокировать письма по ключевым словам или известным отправителям, однако современные атаки используют методы обфускации, маскировки и социальной инженерии, чтобы обойти эти простые барьеры. Особенно остро эта проблема проявляется в связи с ростом объемов спама, генерируемого автоматизированными системами, и способностью злоумышленников адаптироваться к новым фильтрам практически в режиме реального времени. Эффективность старых подходов снижается, поскольку атаки становятся более изощренными и направленными, требуя разработки новых, более интеллектуальных систем защиты, способных анализировать контекст и поведение отправителей, а не только содержание писем.
Появление больших языковых моделей (LLM) существенно изменило ландшафт киберугроз, требуя перехода от простых методов обнаружения спама и фишинга, основанных на сопоставлении ключевых слов, к более глубокому анализу содержания электронных писем. Злоумышленники активно используют LLM для создания правдоподобных и персонализированных сообщений, которые сложно отличить от легитимной корреспонденции. Простая проверка на наличие определенных слов или фраз уже недостаточна, поскольку сгенерированные тексты демонстрируют высокий уровень лингвистической сложности и контекстуальной релевантности. Необходимо учитывать не только лексику, но и стилистические особенности, эмоциональную окраску и общую структуру сообщения, чтобы выявить манипулятивные намерения и предотвратить успешные атаки.
Для точной классификации электронных писем недостаточно анализа исключительно содержания сообщения. Современные исследования показывают, что критически важным является понимание контекста коммуникации — то, как и почему было составлено письмо. Оценивается не только наличие ключевых слов, но и стилистические особенности, эмоциональная окраска, структура предложений и даже используемый тон. Это позволяет выявлять манипулятивные техники и скрытые намерения, которые могут указывать на фишинговые атаки или другие вредоносные действия, даже если само содержание выглядит безобидно. Анализ прагматических аспектов коммуникации, таких как цель отправителя и предполагаемая реакция получателя, значительно повышает эффективность систем обнаружения угроз и обеспечивает более надежную защиту от сложных кибератак.
Анализ с Помощью LLM: Новый Взгляд на Понимание Электронных Писем
Для классификации электронных писем используется подход, основанный на больших языковых моделях (LLM), в частности, Claude 3.5 Sonnet. Проводится анализ как эмоциональной окраски текста, так и мотивационных факторов, заложенных в содержании письма. Этот анализ позволяет выявлять признаки, указывающие на потенциально вредоносные намерения отправителя. В рамках данной системы LLM используется для определения эмоциональных сигналов и мотивационных интентов, что позволяет более точно классифицировать входящие сообщения и выявлять потенциальные угрозы безопасности.
Анализ входящей корреспонденции на предмет злонамеренных намерений осуществляется путем выявления эмоциональных сигналов и мотивационных установок, содержащихся в тексте электронных писем. Это предполагает определение таких характеристик, как тональность сообщения (позитивная, негативная, нейтральная), проявление срочности, попытки манипулирования или оказания давления, а также скрытые призывы к действию. Выявление этих элементов позволяет оценить вероятность того, что письмо является частью фишинговой атаки, попыткой вымогательства или иного вида мошенничества. Идентификация эмоциональных и мотивационных факторов в сочетании с анализом контекста письма является ключевым компонентом системы обнаружения вредоносной активности.
Ключевым аспектом разработки системы является создание высококачественного набора данных, обеспечивающего надежное обучение модели. Процесс построения набора данных включал в себя тщательный отбор и аннотацию электронных писем с целью выявления эмоциональной окраски и мотивационных факторов. Полученный набор данных позволил добиться стабильной точности классификации на уровне 66-67% при использовании модели Claude 3.5 Sonnet, что подтверждает значимость качественной подготовки данных для эффективной работы алгоритмов анализа электронной почты.
Обеспечение Надежности: Устойчивость через Перефразирование Контента
Для оценки устойчивости модели к вариациям входных данных была применена техника перефразирования. Суть метода заключается в автоматической генерации альтернативных версий электронных писем с сохранением их основного смысла. Изменение формулировок и синтаксиса осуществлялось с целью имитации атак, основанных на незначительных изменениях содержания. Полученные перефразированные данные использовались для проверки способности модели классификации электронной почты поддерживать точность определения при незначительных изменениях в тексте сообщений.
Для генерации перефразированных версий электронных писем использовались большие языковые модели (LLM), такие как GPT-4 и DeepSeek-Chat. Процесс осуществлялся автоматически: исходный текст письма передавался в LLM, которая генерировала несколько вариантов с сохранением основного смысла. Каждый сгенерированный вариант рассматривался как отдельное письмо для последующей оценки модели классификации электронной почты. Использование LLM позволило создать разнообразный набор перефразированных писем, охватывающий различные стилистические и лексические вариации, что обеспечило более полное тестирование устойчивости модели к манипуляциям с текстом.
Для оценки устойчивости модели классификации электронной почты на основе LLM к вариациям входных данных, результаты автоматической перефразировки электронных писем, выполненной с использованием моделей GPT-4 и DeepSeek-Chat, были использованы для проверки сохранения точности. Анализ показал стабильную точность классификации в диапазоне 66-67% даже при обработке перефразированных писем, что демонстрирует высокую устойчивость модели к так называемым «атакам перефразировкой» — попыткам обхода классификатора путем изменения формулировок при сохранении смысла сообщения.
Количественная Оценка Сходства: Подтверждение Анализа с Помощью Показателя Жаккара
Для объективной оценки качества анализа эмоциональной окраски и мотивации использовался показатель Якобсона (Jaccard Similarity). Данный метод позволяет количественно определить степень пересечения между предсказанными и фактическими метками, обеспечивая строгую оценку эффективности моделей. По сути, он измеряет отношение количества общих элементов к общему количеству уникальных элементов в двух наборах данных, что делает его надежным инструментом для сравнения и валидации результатов анализа. Применение данного подхода позволило получить воспроизводимые и сопоставимые данные, необходимые для выявления наиболее эффективных моделей в задачах эмоционального и мотивационного анализа.
Для обеспечения объективной оценки качества анализа эмоций и мотиваций, использовался показатель Яккарда, позволяющий количественно определить степень совпадения между предсказанными моделью и фактическими метками. Этот метод вычисляет отношение пересечения множеств предсказанных и истинных значений к их объединению, предоставляя числовую меру схожести. Более высокий показатель Яккарда указывает на более точное соответствие между предсказаниями и реальностью, что делает его надежным инструментом для строгой оценки производительности моделей машинного обучения. Использование данного подхода позволило провести непредвзятую и воспроизводимую оценку эффективности различных языковых моделей в задачах анализа эмоциональной окраски и мотивационных факторов.
Анализ показал, что модель Claude 3.5 Sonnet демонстрирует наивысший уровень соответствия между предсказанными и фактическими эмоциональными метками, достигнув показателя Jaccard Similarity в 0.60 среди протестированных больших языковых моделей (GPT-4o-mini, GPT-4.1-mini, DeepSeek-Chat). Кроме того, при анализе мотивации, данная модель позволила добиться точности в 42%, оцениваемой как «достаточно близко» к эталонным значениям, что также является лучшим результатом среди всех исследуемых моделей. Полученные данные свидетельствуют о значительном превосходстве Claude 3.5 Sonnet в задачах автоматического определения эмоциональной окраски и мотивационных факторов, что открывает перспективы для более точного анализа текстов и улучшения качества работы систем, основанных на обработке естественного языка.
Исследование, представленное в статье, вновь подтверждает извечную истину: системы безопасности, подобно живым организмам, адаптируются и эволюционируют, но никогда не достигают абсолютной защиты. Даже самые передовые языковые модели, способные распознавать манипуляции и эмоциональный окрас сообщений, оказываются бессильны перед размыванием границ между полезной информацией и нежелательным контентом. Блез Паскаль некогда заметил: «Все проблемы человечества происходят от того, что люди не могут спокойно сидеть в одной комнате». В контексте кибербезопасности, это можно перефразировать: все уязвимости систем происходят от неспособности четко разграничить дозволенное и запретное. Попытки создать идеальную систему обнаружения фишинга и спама обречены на провал, ведь любая классификация — это всегда компромисс, застывший во времени, и иллюзия порядка в хаотичном потоке информации.
Куда Ведёт Дорога?
Представленный труд демонстрирует, что современные языковые модели способны выявлять признаки вредоносных писем, даже если их формулировки изменены. Однако, разделение спама и легитимной корреспонденции остаётся проблемой. Это не провал алгоритмов, а закономерность. Система выявляет намерения, но не различает потребности. Каждый критерий, добавленный для классификации, — это лишь отсрочка неизбежной ошибки, пророчество о будущем ложного срабатывания.
Необходимо признать: настоящая уязвимость — не в текстах писем, а в самой структуре коммуникации. Попытки построить «идеальный фильтр» — это иллюзия. Все взаимосвязано, и любая система, стремящаяся к абсолютной безопасности, неизбежно порождает новые векторы атак. Рано или поздно, все взаимосвязанные компоненты рухнут синхронно, под тяжестью собственных зависимостей.
Будущие исследования должны сместить фокус с поиска «правильных» алгоритмов на понимание эволюции коммуникационных паттернов. Необходимо изучать не только содержание писем, но и контекст, отношения между отправителями и получателями, а также динамику социальных сетей. Иначе, мы просто строим более сложные инструменты для решения симптомов, игнорируя глубинные причины.
Оригинал статьи: https://arxiv.org/pdf/2511.21448.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Стоит ли покупать фунты за йены сейчас или подождать?
- Российский рынок: Ожидание ставки, стабилизация рубля и рост прибылей компаний (20.03.2026 02:32)
- Coinbase, Квантовая Безопасность и Юридические Риски: Обзор Ключевых Событий Крипто-Недели (21.03.2026 09:15)
- Будущее BNB: прогноз цен на криптовалюту BNB
- Будущее WLD: прогноз цен на криптовалюту WLD
- Рынок в ожидании ставки: падение прибыли гигантов и переток инвесторов (20.03.2026 11:32)
- Рост Альфабет ускорился во втором квартале
- Прогноз: покупка Hexcel сегодня может обеспечить вас на всю жизнь
- Искусственный Разум и Судьбы: Взгляд Инвестора
2025-11-29 13:51