Автор: Денис Аветисян
Новый подход к управлению распределенными сервисами искусственного интеллекта обеспечивает предсказуемую производительность и надежность в гетерогенных средах.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал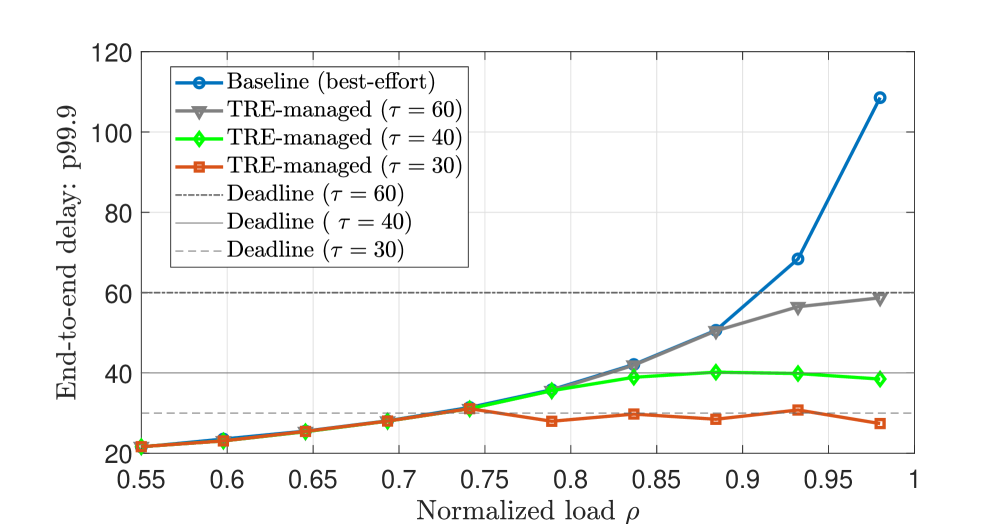
Предлагается фреймворк для оркестрации федеративного ИИ-как-сервиса, использующий композитные контракты (TRE) для обеспечения сквозных гарантий качества и ответственности между различными административными доменами.
Несмотря на растущий спрос на сервисы ИИ как услугу (AIaaS), обеспечение надежной и предсказуемой производительности в условиях федеративных, многодоменных сетей представляет собой сложную задачу. В работе «High-Fidelity Network Management for Federated AI-as-a-Service: Cross-Domain Orchestration» предложен инновационный подход к управлению AIaaS, основанный на использовании компонуемых контрактов (Tail-Risk Envelopes — TRE), позволяющих гарантировать сквозную производительность и обеспечивать прозрачность ответственности между административными доменами. Разработанный фреймворк, использующий стохастический сетевой анализ, позволяет оптимизировать распределение рисков и эффективно изолировать арендаторов, предотвращая влияние всплесков трафика на задержку. Возможно ли создание полностью самооптимизирующихся систем управления AIaaS, способных адаптироваться к динамически меняющимся условиям сети и требованиям пользователей?
Искусственный интеллект как услуга: от подключения к интеллекту
Коммуникационные провайдеры (CSPs) все активнее интегрируют искусственный интеллект как услугу (AIaaS) в свой основной спектр предложений, что знаменует собой фундаментальный сдвиг в их роли. Если ранее CSPs обеспечивали преимущественно подключение к сети, то теперь они стремятся стать поставщиками интеллектуальных сервисов, предоставляя доступ к возможностям ИИ по требованию. Этот переход предполагает не просто добавление новых функций, но и полную трансформацию бизнес-модели, где анализ данных и машинное обучение становятся ключевыми элементами ценностного предложения. Развитие AIaaS позволяет CSPs монетизировать свои сетевые ресурсы и экспертизу в области данных, предлагая клиентам готовые решения для широкого спектра задач — от оптимизации сетевого трафика до персонализированных рекомендаций и автоматизации бизнес-процессов.
Традиционные гарантии сетевой производительности, ориентированные на среднюю задержку, оказываются недостаточными для эффективного функционирования сервисов искусственного интеллекта как услуги (AIaaS). Это связано с тем, что приложения ИИ крайне чувствительны к даже незначительным колебаниям задержки, особенно в «хвосте» распределения — то есть, к редким, но критически важным случаям наихудшей производительности. Вместо усредненных показателей необходимо фокусироваться на экстремальных процентилях задержки, поскольку именно они определяют способность модели ИИ выдавать точные результаты и обеспечивать стабильный пользовательский опыт. Игнорирование этих «хвостовых» рисков может привести к существенному снижению точности моделей, ошибкам в принятии решений и, как следствие, к негативным последствиям для пользователей и бизнеса.
Переход к предоставлению искусственного интеллекта как услуги (AIaaS) ставит перед поставщиками услуг связи (CSPs) новую задачу, связанную с так называемым «хвостовым риском». Этот риск заключается в возможности редких, но критических ухудшений производительности сети, способных серьезно повлиять на точность работы моделей искусственного интеллекта и, следовательно, на пользовательский опыт. В отличие от традиционных гарантий производительности, ориентированных на средние показатели задержки, для AIaaS требуется фокус на экстремальных процентилях. Разработанный фреймворк позволяет количественно оценивать и бюджетировать этот хвостовой риск, обеспечивая прозрачность и ответственность между различными административными доменами сети. Это позволяет операторам связи не только предоставлять услуги AIaaS, но и эффективно управлять потенциальными негативными последствиями, гарантируя стабильно высокое качество обслуживания для критически важных приложений искусственного интеллекта.
Хвостовые контракты и огибающая риска хвоста
Традиционные соглашения об уровне обслуживания (SLA) часто фокусируются на средней задержке, что не всегда релевантно для приложений искусственного интеллекта как сервиса (AIaaS). В отличие от этого, «хвостовой контракт» (Tail Contract) ориентирован на гарантирование производительности на экстремальных процентилях, таких как p99 или p99.9. Это означает, что контракт определяет максимальную задержку, которую можно ожидать в 99% или 99.9% случаев, а не среднее значение. Такой подход критически важен для AIaaS, где даже небольшие задержки в «хвосте» распределения могут значительно повлиять на качество обслуживания и пользовательский опыт, поскольку алгоритмы машинного обучения чувствительны к времени отклика. Гарантии, предоставляемые «хвостовыми контрактами», позволяют более эффективно оптимизировать ресурсы и обеспечивать предсказуемую производительность для критически важных приложений.
Оболочка риска хвоста (Tail-Risk Envelope, TRE) представляет собой формализованный механизм для выражения и обеспечения соглашений об уровне обслуживания (SLA), ориентированных на гарантии производительности в экстремальных процентилях (например, p99, p99.9). Данный подход позволяет создавать композитные гарантии производительности, охватывающие различные сетевые домены, что особенно важно для федеративных сред AIaaS. В отличие от традиционных SLA, ориентированных на средние значения задержки, TRE позволяет выразить и подтвердить количественные гарантии производительности на уровне p99/p99.9, обеспечивая предсказуемость работы сервисов искусственного интеллекта, критичных к задержкам в крайних случаях.
Основой для определения Tail-Risk Envelope (TRE) служат математические инструменты, в частности, момент-генерирующая функция (MGF). MGF(t) = E[e^{tX}] , где X — случайная величина, описывающая задержку, а E — математическое ожидание. Использование MGF позволяет строго анализировать и верифицировать границы производительности, поскольку моменты распределения задержки могут быть вычислены как производные MGF в нуле. Это, в свою очередь, позволяет формально определить вероятностные гарантии, такие как p99 или p99.9, и убедиться, что контракт на производительность (Tail Contract) будет соблюден даже при экстремальных нагрузках. Строгий математический аппарат MGF обеспечивает возможность композиции гарантий производительности в распределенных AIaaS средах, что невозможно при использовании только эмпирических измерений.
Аудит хвостового риска с помощью теории экстремальных значений
Теория экстремальных значений (TEЗ) представляет собой статистический подход, предназначенный для анализа редких событий и оценки экстремальных процентилей на основе наблюдаемых данных. В отличие от традиционных статистических методов, предполагающих нормальное распределение, TEЗ фокусируется на поведении распределения в «хвосте», то есть в области редких, но потенциально критических значений. Это достигается за счет моделирования асимптотических свойств экстремальных значений, что позволяет экстраполировать данные за пределы непосредственно наблюдаемого диапазона и оценивать вероятности событий, которые не были зафиксированы в данных. Ключевыми инструментами TEЗ являются обобщенный экстремальный максимум (GEM) и метод превышения порога (POT), позволяющие оценить параметры, определяющие поведение «хвоста» распределения и, следовательно, вероятность возникновения экстремальных событий. P(X > x) \approx (1/s) \cdot \sigma^{-1} \cdot (x - \mu)/\sigma, где μ и σ — параметры местоположения и масштаба, а s — параметр формы.
Метод превышения порога (Peak-Over-Threshold, POT) в рамках экстремальной теории значений (EVT) позволяет точно оценивать поведение «хвоста» распределения данных, полученных из телеметрии. В рамках POT, фиксируется порог, и анализируются только те события, которые его превышают. На основе анализа величины и частоты этих превышений, строится обобщенное распределение экстремальных значений, что позволяет оценивать вероятности редких, но критичных событий. Полученные оценки используются для валидации Требований к Надежности (TRE), подтверждая, что система способна выдерживать экстремальные нагрузки с заданной вероятностью, и позволяя количественно оценить риски, связанные с отклонением от заданных параметров производительности.
Использование стохастической сетевой теории (SNC) в сочетании с гарантированными скоростями обслуживания (TRE) позволяет вывести границы задержки от конца до конца, обеспечивая предсказуемую производительность для приложений искусственного интеллекта. Проведенные эксперименты показали, что при использовании TRE задержка поддерживалась близкой к установленному сроку τ даже при изменяющейся нагрузке. В отличие от этого, при использовании подхода «best-effort» наблюдалось быстрое увеличение задержки, свидетельствующее о его неспособности обеспечивать предсказуемое поведение в условиях высокой нагрузки.
Федеративный AIaaS и координация с учетом конфиденциальности
Будущее AIaaS неразрывно связано с федерацией — расширением сервисов на несколько доменов операторов, что позволяет создать более масштабную и мощную экосистему искусственного интеллекта. Кажется, что всё больше операторов стремятся к объединению ресурсов для создания более совершенных AI-сервисов. Это не только увеличивает общую производительность и возможности системы, но и позволяет решать задачи, которые были бы невозможны для отдельных операторов. Подобный подход открывает перспективы для инноваций и развития новых AI-приложений, обеспечивая более широкую доступность и эффективность искусственного интеллекта для различных отраслей и пользователей. Федерация способствует формированию децентрализованной и устойчивой AI-инфраструктуры, способной адаптироваться к меняющимся требованиям и потребностям.
Развитие федеративных систем искусственного интеллекта (AIaaS) неизбежно требует новых механизмов координации ресурсов и обеспечения подотчетности между различными участниками. В традиционных централизованных моделях контроль и ответственность четко определены, однако в федеративной среде, где данные и вычислительные мощности распределены между множеством независимых организаций, возникает потребность в подходах, гарантирующих надежность и безопасность обмена информацией. Это предполагает разработку систем, способных эффективно распределять задачи, отслеживать использование ресурсов и обеспечивать соблюдение соглашений об уровне обслуживания (SLA) между всеми вовлеченными сторонами. В частности, возникает необходимость в решениях, позволяющих верифицировать целостность данных и вычислительных процессов, а также устанавливать ответственность в случае возникновения ошибок или нарушений. Соответствующие методы должны учитывать как технические аспекты, так и юридические и этические нормы, обеспечивая прозрачность и доверие в рамках федеративной экосистемы.
Метод множителей и направленных итераций (ADMM) представляет собой перспективный подход к координации в федеративных системах искусственного интеллекта, позволяющий предоставлять AI-сервисы из различных источников, сохраняя при этом конфиденциальность пользовательских данных. Исследования показали, что при использовании ADMM с управлением на основе приоритетов (TRE) удается поддерживать стабильную задержку на уровне p99.9, даже при возрастающей интенсивности атак. В отличие от этого, использование общей очереди FIFO (First-In, First-Out) приводит к значительному увеличению задержки для пострадавшего пользователя при увеличении интенсивности атак, что указывает на превосходство подхода TRE в обеспечении надежной и безопасной координации в федеративных средах AIaaS.
Операционализация AIaaS с помощью MLOps и API
Операции машинного обучения (MLOps) играют ключевую роль в практическом внедрении и поддержании AIaaS в сетевой инфраструктуре. Обеспечивая комплексное управление жизненным циклом моделей машинного обучения — от разработки и тестирования до развертывания и мониторинга — MLOps позволяет автоматизировать процессы, повысить надежность и масштабируемость AIaaS. Реализация MLOps предполагает не только непрерывную интеграцию и доставку (CI/CD) моделей, но и постоянный мониторинг их производительности, выявление отклонений и оперативное внесение корректировок. Такой подход гарантирует, что AIaaS функционирует стабильно и эффективно, адаптируясь к изменяющимся требованиям сети и обеспечивая стабильное предоставление интеллектуальных сервисов.
Интерфейсы прикладного программирования (API) играют ключевую роль в раскрытии потенциала искусственного интеллекта и сетевых сервисов для разработчиков и приложений, стимулируя инновации в различных областях. Эти API позволяют создавать гибкие и масштабируемые решения, интегрируя интеллектуальные возможности непосредственно в существующие системы и приложения. Благодаря стандартизированным протоколам взаимодействия, разработчики могут легко получать доступ к моделям машинного обучения и сетевым функциям, не углубляясь в детали их реализации. Это значительно ускоряет процесс разработки и позволяет создавать новые, интеллектуальные сервисы, отвечающие потребностям современного цифрового мира. Использование API способствует формированию экосистемы, где инновации становятся более доступными и быстро реализуемыми, что, в свою очередь, способствует развитию новых бизнес-моделей и повышению эффективности существующих.
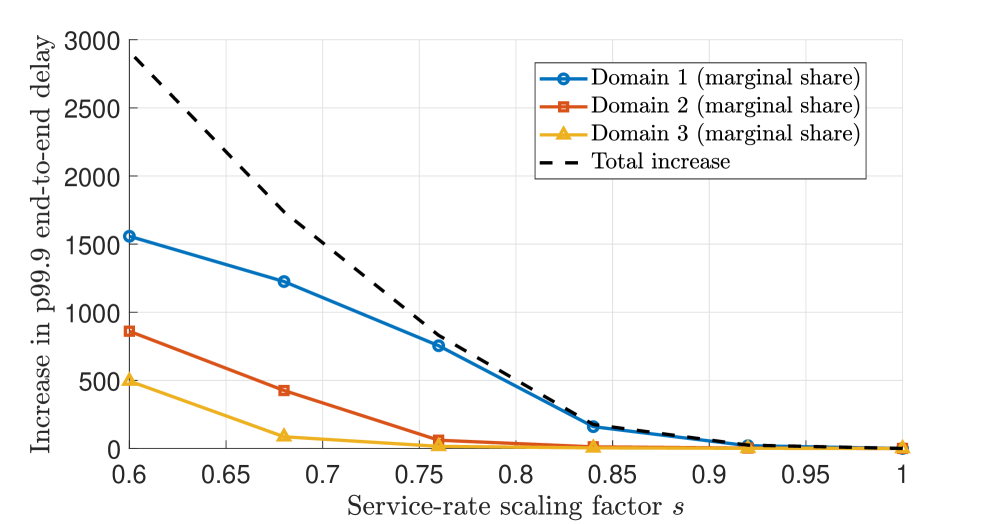
Для валидации производительности сети и оптимизации распределения ресурсов при федеративных развертываниях AIaaS используются моделирования, основанные на методах обслуживания запросов FIFO (First-In, First-Out) в сочетании с сетевой нейтрализацией (SNC). Проведенные исследования выявили, что вклад отдельных доменов в увеличение рисков “хвоста” (tail-risk) непропорционально велик. Это позволяет целенаправленно оценивать и контролировать риски, связанные с использованием AIaaS, и обеспечивать более эффективное распределение ресурсов для минимизации потенциальных негативных последствий в условиях повышенной нагрузки или нестабильности сети.
Наблюдатель отмечает, что стремление к созданию federated AI-as-a-Service (AIaaS) с гарантированными характеристиками — это, по сути, попытка обуздать хаос, зафиксированный в договорах, подобных Tail-Risk Envelope (TRE). Это напоминает о словах Марвина Мински: «Лучший способ предсказать будущее — создать его». Разработчики, предлагая composable contracts для изоляции и ответственности между административными доменами, стремятся не просто предвидеть риски, но и активно формировать надежную основу для сложных систем. Однако, опыт подсказывает, что любое элегантное решение рано или поздно встретится с суровой реальностью продакшена, где теоретические гарантии столкнутся с непредсказуемыми сетевыми проблемами и ограничениями ресурсов.
Что дальше?
Предложенная в данной работе концепция композируемых контрактов для управления федеративным AIaaS, безусловно, представляет собой элегантную попытку обуздать хаос междоменной оркестрации. Однако, как показывает опыт, любая система гарантий неизбежно упирается в проблему верификации. Неизбежно возникнет вопрос: кто проверяет проверяющих? И как оценить стоимость поддержания этих самых гарантий, когда производственные нагрузки начнут испытывать систему на прочность?
В перспективе, акцент, вероятно, сместится с поиска «идеальных» контрактов на разработку эффективных механизмов мониторинга и адаптации. Вместо того, чтобы пытаться предвидеть все возможные сценарии отказа, следует сосредоточиться на создании систем, способных быстро обнаруживать и смягчать последствия нештатных ситуаций. Нам не нужно больше микросервисов — нам нужно меньше иллюзий о полной предсказуемости.
В конечном счете, эта работа лишь подчеркивает фундаментальную истину: любая «революционная» технология завтра станет техдолгом. Элегантные теории неизбежно столкнутся с суровой реальностью производственных ограничений и непредсказуемого поведения пользователей. И, как всегда, прод найдет способ сломать даже самую совершенную архитектуру.
Оригинал статьи: https://arxiv.org/pdf/2602.15281.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- Крипто-археология: Снижение активности, накопление BTC и геополитическая неопределенность (09.04.2026 04:45)
- Прогноз нефти
- Стоит ли покупать доллары за юани сейчас или подождать?
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
- Группа Аренадата акции прогноз. Цена DATA
- АЛРОСА акции прогноз. Цена ALRS
2026-02-18 22:33