Автор: Денис Аветисян
Исследователи представили комплексный набор данных FinMTM для оценки способности моделей понимать финансовую информацию и принимать решения в сложных ситуациях.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал
FinMTM — это мультимодальный бенчмарк, предназначенный для проверки возможностей моделей обработки изображений и текста в задачах финансового анализа и планирования.
Сложность анализа финансовых данных, требующего одновременной обработки визуальной информации и глубоких специализированных знаний, представляет серьезный вызов для современных мультимодальных моделей. В данной работе представлена новая мультимодальная платформа ‘FinMTM: A Multi-Turn Multimodal Benchmark for Financial Reasoning and Agent Evaluation’, предназначенная для всесторонней оценки способностей моделей к финансовому анализу и принятию решений в диалоговом режиме. Платформа включает в себя 11\,133 англо- и китаеязычных вопросов, основанных на финансовых графиках и отчетах, и охватывает различные типы задач, включая ответы на вопросы с выбором ответа, многоходовые диалоги и задачи для агентов. Какие перспективы открываются для разработки более интеллектуальных и эффективных финансовых инструментов на основе мультимодальных моделей, способных к долгосрочному анализу и сложному планированию?
Финансовый анализ: иллюзия компетентности или реальная способность?
Несмотря на впечатляющие успехи в области мультимодального понимания, современные визуальные языковые модели (VLM) сталкиваются с серьезными трудностями при решении задач, требующих сложного финансового мышления. В то время как модели демонстрируют способность распознавать и интерпретировать визуальную и текстовую информацию, анализ финансовых отчетов, прогнозирование рыночных тенденций или оценка рисков требуют не только понимания данных, но и способности к абстрактному мышлению, логическим выводам и стратегическому планированию. Это проявляется в неспособности моделей адекватно реагировать на нюансы финансового контекста, оценивать долгосрочные последствия решений или эффективно оперировать сложными финансовыми инструментами, что подчеркивает необходимость разработки новых подходов к обучению и оценке финансовых способностей VLM.
Существующие оценочные критерии для визуальных языковых моделей (ВЯМ) в сфере финансов зачастую не обладают достаточной глубиной и тонкостью, чтобы адекватно оценить их реальные способности к финансовому анализу. Стандартные наборы данных и метрики, используемые для тестирования, склонны упрощать сложные финансовые сценарии, игнорируя нюансы, контекст и необходимость долгосрочного планирования. В результате, модели могут демонстрировать высокие показатели на этих упрощенных тестах, создавая иллюзию компетентности, которая не соответствует их реальной способности принимать обоснованные финансовые решения в более сложных и реалистичных условиях. Это несоответствие между показателями на тестах и реальной производительностью создает значительную проблему при разработке и внедрении ВЯМ в финансовые приложения.
Разработка эффективных финансовых агентов требует гораздо большего, чем просто умения интерпретировать данные. Успешная работа в этой области подразумевает наличие надежного механизма планирования, позволяющего агенту последовательно достигать поставленных финансовых целей. При этом, критически важным является умение использовать внешние инструменты — калькуляторы, базы данных, аналитические платформы — для расширения собственных возможностей и повышения точности принимаемых решений. Агент должен не просто «видеть» информацию, но и активно использовать ее для построения долгосрочных стратегий и адаптации к изменяющимся рыночным условиям, что требует интеграции с различными внешними сервисами и API.
Современные визуальные языковые модели (ВЯМ) сталкиваются со значительными трудностями при обработке продолжительных диалогов, особенно в контексте финансовых взаимодействий. Способность сохранять и эффективно использовать информацию из предыдущих этапов беседы, необходимая для сложных финансовых рассуждений, пока ограничена. Модели часто теряют нить обсуждения, неверно интерпретируют предыдущие указания или забывают ключевые детали, что приводит к неточным прогнозам и неоптимальным решениям. Данная проблема усугубляется сложностью финансовых данных и необходимостью учитывать множество факторов на протяжении длительного периода времени, что требует от ВЯМ не только понимания отдельных запросов, но и способности к последовательному мышлению и интеграции информации на протяжении всей беседы.

FinMTM: Строгий экзамен для финансовых интеллектов
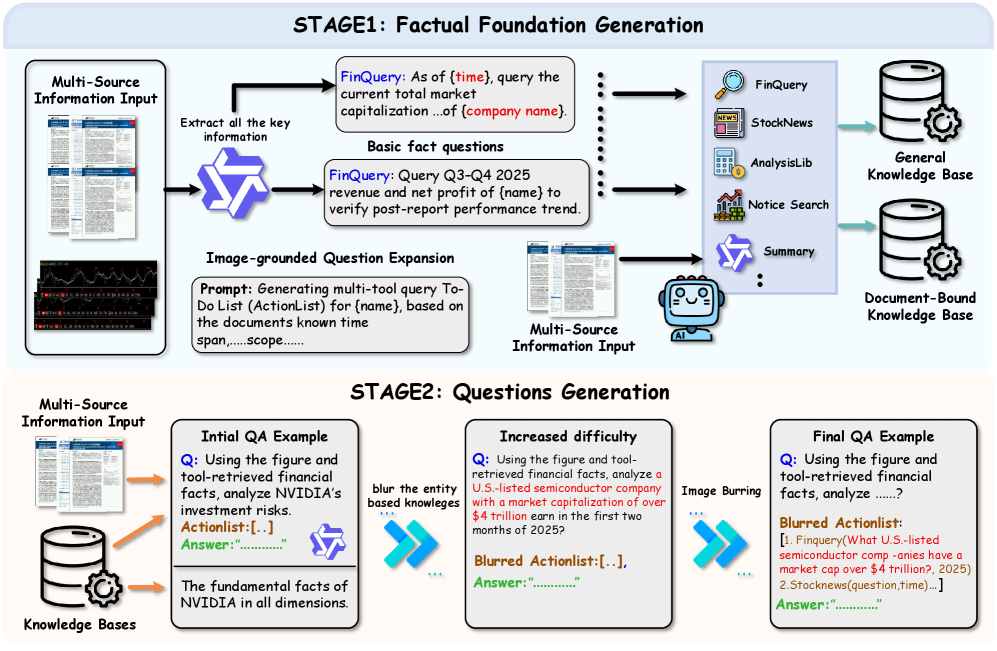
Бенчмарк FinMTM разработан для обеспечения строгой оценки способностей визуально-языковых моделей (VLM) к финансовому рассуждению. В отличие от существующих оценочных наборов данных, FinMTM использует многооборотные, мультимодальные сценарии, имитирующие реальные финансовые задачи. Это означает, что модели должны не просто интерпретировать отдельные изображения или текстовые фрагменты, но и поддерживать контекст на протяжении всей последовательности взаимодействия, интегрируя информацию из различных источников (изображения графиков, текстовые вопросы, предыдущие ответы) для принятия обоснованных решений. Такой подход позволяет более точно оценить способность моделей к комплексному анализу и планированию в условиях финансовой неопределенности.
Бенчмарк FinMTM использует комбинированный подход к оценке, включающий задачи с объективными ответами (multiple-choice), вопросы, требующие развернутого ответа, и сложные задания, моделирующие действия финансового агента. Объективные вопросы позволяют проверить базовые знания и способность к быстрому извлечению информации. Вопросы открытого типа оценивают навыки аргументации и синтеза данных. Задания, требующие выполнения роли финансового агента, проверяют способность модели к планированию последовательности действий, использованию внешних инструментов и принятию решений в условиях неопределенности, что комплексно оценивает разнообразные когнитивные способности, необходимые для финансового анализа.
FinMTM делает акцент на возможностях агентов, требуя от моделей использования внешних инструментов и планирования стратегических действий, что выходит за рамки пассивной интерпретации данных. В отличие от традиционных задач, где модель просто отвечает на вопрос, FinMTM предполагает взаимодействие с окружением, например, использование калькулятора или API для получения котировок. Это подразумевает не только понимание финансовой информации, но и способность разрабатывать последовательность действий для достижения конкретной цели, такой как оптимизация портфеля или принятие инвестиционного решения. Оценка проводится на основе не только правильности ответа, но и эффективности плана действий и корректности использования инструментов.
В основе FinMTM лежит использование финансовых графиков в качестве ключевого входного сигнала, что отражает реальные рабочие процессы финансового анализа. Данные графики, представляющие собой визуализацию рыночных тенденций, показателей компаний и других финансовых данных, требуют от модели способности к интерпретации визуальной информации и ее интеграции с другими входными данными. Это позволяет оценивать не только понимание числовых значений, но и способность к распознаванию паттернов, трендов и аномалий на графиках, что критически важно для принятия обоснованных финансовых решений. Использование графиков в FinMTM имитирует задачи, с которыми сталкиваются финансовые аналитики в повседневной практике, и позволяет более адекватно оценить возможности моделей в решении реальных финансовых задач.
Методы оценки: Точность и последовательность финансовых рассуждений
Оценка ответов на вопросы с четко определенными правильными ответами осуществляется с помощью метода Set-Based Scoring. Данный метод количественно определяет степень пересечения между предсказанным моделью ответом и эталонным (ground truth) ответом, рассматривая оба как множества элементов. Метрика вычисляется как отношение количества общих элементов в предсказанном и эталонном ответах к общему числу уникальных элементов в обоих множествах. Это позволяет объективно измерить точность и полноту ответа модели, независимо от порядка представления элементов в ответе. Результат Set-Based Scoring представляет собой значение в диапазоне от 0 до 1, где 1 указывает на полное совпадение, а 0 — на отсутствие общих элементов.
Для оценки ответов на вопросы открытого типа используется система Dual-Rule LLM-Judge, представляющая собой двухкомпонентный подход. Первый компонент оценивает качество ответов на каждом отдельном шаге взаимодействия (turn-level capability), анализируя релевантность, логичность и полноту ответа по отношению к предыдущему запросу. Второй компонент оценивает общую связность и согласованность всего сеанса взаимодействия (session-level coherence), проверяя, поддерживает ли модель последовательную логику и сохраняет ли контекст на протяжении всего диалога. Данная система позволяет более точно и комплексно оценивать способность модели к ведению осмысленных и последовательных бесед.
Оценка задач финансового агента осуществляется посредством Траекторной Оценки (Trajectory-Based Evaluation), которая фокусируется на анализе качества планирования и последовательности действий модели. Данный метод предполагает разбивку задачи на отдельные этапы планирования и исполнения, после чего оценивается логичность и эффективность каждого шага. Оценка производится не только по конечному результату, но и по промежуточным решениям, что позволяет выявить слабые места в стратегии агента и оценить его способность к адаптации в различных финансовых сценариях. Траекторная Оценка позволяет комплексно оценить не только достижение цели, но и процесс её достижения, что критически важно для оценки надежности и предсказуемости финансового агента.
Для повышения устойчивости оценки, используется стратегия фаззинга (Fuzz Strategy), заключающаяся в намеренном введении неоднозначности и шума в входные данные. Это достигается путем внесения небольших изменений и искажений в запросы, например, синонимизацией слов, добавлением орфографических ошибок или изменением порядка слов. Целью фаззинга является проверка способности агента корректно обрабатывать нечеткие или неполные входные данные, имитируя реальные пользовательские запросы, которые часто содержат неточности. Такой подход позволяет выявить слабые места в логике агента и оценить его устойчивость к различным типам входного шума, что критически важно для обеспечения надежности в реальных условиях эксплуатации.
Итоги и перспективы: Где сильны и слабы современные финансовые интеллекты?
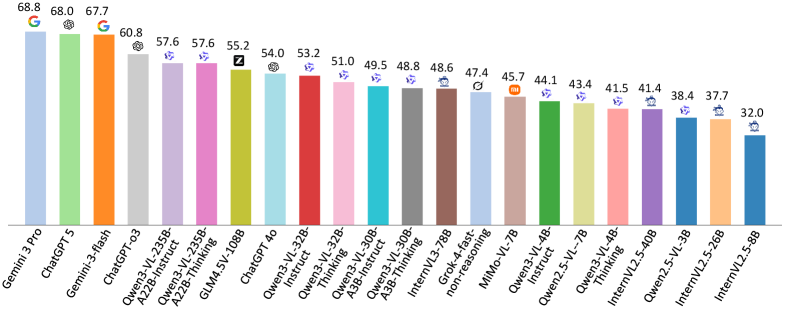
Оценка возможностей современных больших языковых моделей (ВЛМ), таких как Gemini 3 Pro и ChatGPT-4o, с использованием специализированного бенчмарка FinMTM, выявила существенные различия в их способностях к комплексному финансовому анализу и выполнению задач, требующих автономного принятия решений. Результаты исследований демонстрируют, что проприетарные модели, в отличие от моделей с открытым исходным кодом, показывают более высокую эффективность в решении сложных финансовых задач и в роли интеллектуальных агентов, способных к планированию и реализации финансовых стратегий. Этот анализ подчеркивает важность дальнейших разработок в области финансовых ВЛМ и необходимость создания более совершенных инструментов для автоматизации финансовых процессов и поддержки принятия обоснованных инвестиционных решений.
Исследование, проведенное с использованием FinMTM, наглядно демонстрирует, что эффективное функционирование финансовых агентов напрямую зависит от доступа к структурированной базе знаний. Отсутствие подобной поддержки существенно ограничивает возможности моделей в принятии обоснованных решений, особенно в сложных финансовых сценариях, требующих анализа большого объема информации и учета множества факторов. Интеграция базы знаний позволяет агентам не только получать точные данные, но и понимать контекст, выявлять взаимосвязи и прогнозировать возможные последствия, что критически важно для успешного выполнения финансовых задач и минимизации рисков. Данный подход значительно повышает надежность и эффективность работы агентов, позволяя им действовать более осознанно и предсказуемо в динамичной финансовой среде.
Бенчмарк FinMTM особо подчёркивает необходимость для современных языковых моделей не только понимать отдельные запросы, но и сохранять контекст на протяжении развернутых диалогов. Исследование выявило, что способность поддерживать последовательность рассуждений в многоходовых взаимодействиях является критически важной для успешного выполнения финансовых задач, требующих учета предыдущих шагов и информации. Модели, демонстрирующие низкую способность к сохранению контекста, испытывают трудности в сложных финансовых сценариях, где решения принимаются на основе эволюционирующей информации и прошлых взаимодействий, что указывает на важность развития механизмов долговременной памяти и контекстуального понимания в области искусственного интеллекта.
Оценка моделей в рамках FinMTM продемонстрировала значительные различия в их производительности. В частности, Gemini 3 Flash показал ведущие результаты в сложном задании Fuzzed Agent Task Performance, достигнув 53.6/62.6 баллов, что свидетельствует о его эффективности в задачах, требующих быстрого и адаптивного принятия решений. В то же время, Gemini 3 Pro превзошел конкурентов в понимании открытых вопросов, набрав 87.5 баллов, подтверждая его способность к глубокому анализу и интерпретации информации. Модель ChatGPT-4o, в свою очередь, продемонстрировала высокую точность в задачах с множественным выбором, достигнув 79.6 баллов, что указывает на её надежность в ситуациях, требующих однозначного ответа. Полученные данные подчеркивают, что различные модели демонстрируют сильные стороны в определенных областях финансового анализа и принятия решений.

Этот FinMTM, конечно, заявлен как некий полигон для оценки финансовых моделей. Но, как показывает опыт, любые «революционные» бенчмарки быстро превращаются в наборы эвристик, которые модели научаются обходить. Задачка с долгосрочным контекстом и сложным анализом, представьте себе, требует от модели не просто обработки данных, а понимания причинно-следственных связей. А это, судя по всему, пока что роскошь. Как метко заметил Джеффри Хинтон: «Чем сложнее модель, тем сложнее понять, почему она работает». И в данном случае, если баг воспроизводится — значит, у нас стабильная система, а не прогресс в понимании финансового анализа.
Что дальше?
Представленный бенчмарк FinMTM, безусловно, выявляет слабые места существующих моделей в области финансового рассуждения. Однако, каждая «революция» в машинном обучении неизбежно порождает новый вид технического долга. Вероятно, последующие поколения моделей смогут демонстрировать лучшие результаты на FinMTM, но это лишь сдвинет планку сложности, обнажая новые, более изощренные ограничения. Иллюзия «понимания» финансов, создаваемая алгоритмами, всегда будет хрупкой.
В перспективе, стоит ожидать дальнейшей гонки за контекстным окном и усложнением архитектур. Но даже если модели научатся обрабатывать бесконечные потоки данных, фундаментальная проблема останется: любая абстракция умирает от продакшена. Реальные финансовые рынки — это хаос, и никакая модель не сможет его полностью предсказать. Но зато красиво умирает.
В конечном итоге, кажется неизбежным, что всё, что можно задеплоить, однажды упадёт. Поэтому, вероятно, более продуктивным направлением исследований станет не столько повышение точности предсказаний, сколько разработка систем, способных элегантно справляться с неизбежными ошибками и неопределенностью. Иначе говоря, искусство управления рисками, а не иллюзия всезнания.
Оригинал статьи: https://arxiv.org/pdf/2602.03130.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Стоит ли покупать фунты за йены сейчас или подождать?
- Российский рынок: Ожидание ставки, стабилизация рубля и рост прибылей компаний (20.03.2026 02:32)
- Аэрофлот акции прогноз. Цена AFLT
- Рынок в ожидании: ставка ЦБ, риски для маркетплейсов и убытки регулятора (21.03.2026 01:32)
- Аналитический обзор рынка (08.10.2025 12:32)
- Аналитический обзор рынка (15.09.2025 02:32)
- Нейросети, предсказывающие скачки цен: новый подход к высокочастотной торговле
- Стоит ли покупать доллары за бразильские реалы сейчас или подождать?
- Рынок в ожидании ставки: падение прибыли гигантов и переток инвесторов (20.03.2026 11:32)
2026-02-04 18:37