Автор: Денис Аветисян
В новой работе показано, как оптимизировать обобщенные аддитивные модели для достижения оптимального сочетания предсказательной силы, простоты интерпретации и компактности.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал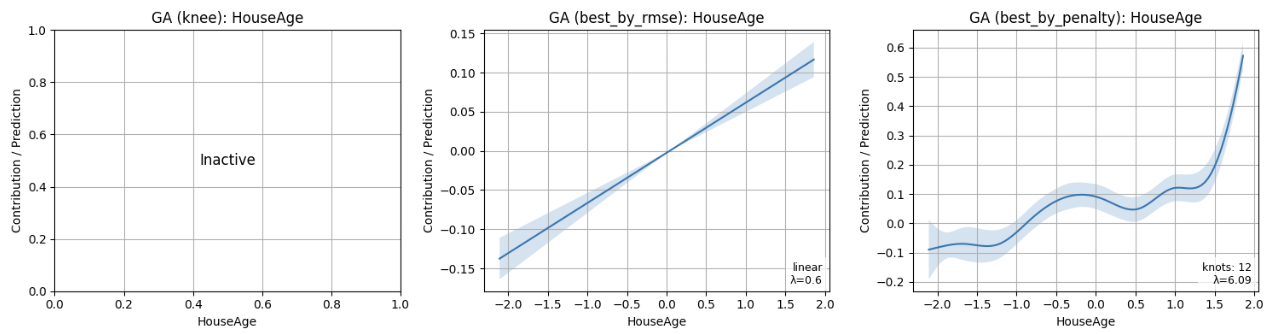
Применение алгоритма NSGA-II для многокритериальной оптимизации структуры обобщенных аддитивных моделей (GAM).
Построение моделей, сочетающих высокую предсказательную точность и интерпретируемость, представляет собой сложную задачу. В статье ‘Genetic Generalized Additive Models’ предлагается подход к автоматической оптимизации обобщенных аддитивных моделей (GAM) с использованием многоцелевого генетического алгоритма NSGA-II. Показано, что данный алгоритм позволяет одновременно минимизировать ошибку предсказания и сложность модели, обеспечивая баланс между точностью, разреженностью и гладкостью. Возможно ли дальнейшее развитие этого фреймворка для автоматизированного построения прозрачных и эффективных моделей в различных областях применения?
Разрушая Чёрный Ящик: Проблема Интерпретируемости Прогнозов
Многие современные прогностические модели, демонстрирующие высокую точность предсказаний, страдают от недостатка прозрачности, что существенно ограничивает доверие к ним и возможности практического применения. Невозможность понять логику, лежащую в основе принятия решений моделью, создает проблемы при интерпретации результатов и не позволяет извлечь полезные знания из данных. Вместо того чтобы служить инструментом для понимания явлений, такие модели часто функционируют как “черные ящики”, выдающие прогнозы без объяснений, что особенно критично в областях, требующих обоснованных и проверяемых решений, таких как медицина, финансы и право.
Сложные «черные ящики» в моделях предсказания, несмотря на потенциально незначительное повышение точности, зачастую лишены прозрачности, что существенно ограничивает их применение на практике. Повышение предсказательной силы, достигаемое за счет усложнения алгоритма, может оказаться бесполезным, если невозможно понять, какие факторы привели к конкретному результату. Это особенно критично в областях, где требуется обоснование решений, например, в медицине, финансах или юриспруденции. Невозможность интерпретировать логику модели подрывает доверие к ней и препятствует эффективному использованию полученных прогнозов, ведь понимание почему модель пришла к тому или иному выводу часто важнее самого предсказания.
В настоящее время наблюдается острая необходимость в создании прогностических моделей, которые не просто демонстрируют высокую точность, но и позволяют понять логику, лежащую в основе их предсказаний. Простое достижение максимальной производительности уже недостаточно; всё большее значение приобретает возможность интерпретации результатов и выявления факторов, влияющих на принятие решений моделью. Это особенно важно в критически важных областях, таких как медицина или финансы, где необходимо не только предсказать исход, но и обосновать его, чтобы обеспечить доверие и возможность принятия обоснованных мер. Разработка таких моделей — это не просто техническая задача, но и этическая необходимость, позволяющая использовать искусственный интеллект ответственно и эффективно.
Обобщенные Аддитивные Модели: Фундамент Интерпретируемого Моделирования
Обобщенные аддитивные модели (GAM) представляют собой гибкий инструмент для моделирования нелинейных зависимостей, сохраняя при этом возможность интерпретации результатов. В отличие от линейных моделей, GAM позволяют каждой независимой переменной вносить вклад в прогноз нелинейным образом, используя, например, сплайн-функции или другие гладкие функции. При этом, общая предсказательная способность модели формируется как сумма вкладов от каждой переменной, что упрощает анализ влияния отдельных признаков и понимание структуры данных. \hat{y} = f_1(x_1) + f_2(x_2) + ... + f_p(x_p) , где \hat{y} — предсказанное значение, x_i — i-я независимая переменная, а f_i — нелинейная функция, описывающая вклад этой переменной в прогноз.
Обоснованием высокой интерпретируемости обобщенных аддитивных моделей (GAM) является их способность разлагать предсказания на сумму вкладов от отдельных признаков. Каждый признак в GAM моделируется как независимая функция, f_i(x_i), и общее предсказание является суммой этих функций: \hat{y} = \sum_{i=1}^{p} f_i(x_i). Это позволяет напрямую оценивать важность каждого признака, анализируя вклад соответствующей функции f_i(x_i) в конечное предсказание. Кроме того, анализ формы функции f_i(x_i) позволяет понять, как конкретный признак влияет на предсказания модели, например, является ли влияние линейным, нелинейным или имеет определенные пороги.
В обобщенных аддитивных моделях (GAM) использование сплайнов позволяет моделировать нелинейные зависимости между предикторами и целевой переменной, сохраняя при этом свойство аддитивности. Сплайны — это кусочно-полиномиальные функции, которые аппроксимируют сложную кривую, используя отдельные полиномиальные сегменты, соединенные в точках, обеспечивая гладкость перехода. Это позволяет GAM моделировать более сложные отношения, чем, например, линейная регрессия, без потери возможности интерпретировать вклад каждого предиктора как сумму его индивидуальных эффектов. Различные типы сплайнов, такие как кубические сплайны или регрессионные сплайны, могут быть использованы для контроля степени гладкости и гибкости модели. f(x) = \sum_{j=1}^{p} a_j N_j(x) , где N_j(x) — базисные функции сплайна, а a_j — коэффициенты.
NSGA-II: Оптимизация GAM для Производительности и Простоты
Для оптимизации гиперпараметров GAM используется NSGA-II, многоцелевой генетический алгоритм, который одновременно балансирует между точностью предсказаний (измеряемой как среднеквадратичная ошибка — RMSE) и сложностью модели. В отличие от одноцелевой оптимизации, NSGA-II позволяет находить набор решений, представляющих собой компромисс между этими двумя критериями. Алгоритм ищет конфигурации GAM, минимизирующие RMSE, но при этом учитывает и сложность модели, что позволяет получить более интерпретируемые и устойчивые к переобучению модели. Это достигается путем формирования популяции GAM-моделей и последовательного улучшения их характеристик с помощью генетических операторов, таких как кроссовер и мутация.
Алгоритм NSGA-II одновременно оптимизирует конфигурации GAM для минимизации ошибки предсказания (RMSE) и максимизации разреженности модели. В ходе экспериментов NSGA-II продемонстрировал наименьшее значение RMSE среди всех использованных вариантов (включая Decision Tree и базовый LinearGAM) при различных начальных условиях (seeds). Достижение разреженности происходит за счет поиска параметров, приводящих к отключению незначащих эффектов, что повышает интерпретируемость модели и упрощает ее анализ. Оптимизация ведется по двум целям одновременно, позволяя находить компромисс между точностью и сложностью модели.
Алгоритм использует генетические операторы, такие как кроссовер и мутация, для эффективного исследования пространства гиперпараметров GAM. Оценка каждой конфигурации осуществляется на основе двух критериев: среднеквадратичной ошибки (RMSE) и штрафа, зависящего от неопределенности модели. В ходе оптимизации использовалась популяция из 80 особей, эволюционировавшая в течение 50 поколений. Вероятность кроссовера составляла 0.3, а адаптивная скорость мутации начиналась с 0.15 и уменьшалась с течением времени, что способствовало более точному поиску оптимальных параметров.
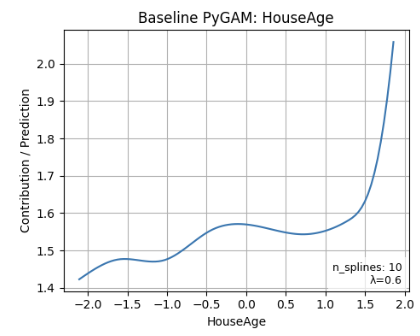
Алгоритм NSGA-II формирует фронт Парето, состоящий из оптимальных конфигураций GAM, позволяя пользователю осознанно выбирать между предсказательной точностью и сложностью модели. Полученные NSGA-GAM модели демонстрируют более высокую разреженность по сравнению с базовым PyGAM за счет отключения незначащих эффектов, что достигается путем установки соответствующих параметров в неактивное состояние. Это обеспечивает возможность создания более интерпретируемых моделей без существенной потери в точности предсказаний, предоставляя пользователю контроль над компромиссом между производительностью и простотой.
Балансируя Точность и Интерпретируемость: Практические Последствия
Полученный фронт Парето представляет собой ценный инструмент для специалистов, позволяющий выбрать конфигурацию GAM, наилучшим образом соответствующую их конкретным приоритетам. Он позволяет гибко балансировать между высокой точностью предсказаний и простотой интерпретации модели. В зависимости от задач — будь то максимальное повышение производительности или обеспечение прозрачности процесса принятия решений — можно выбрать оптимальный вариант, находящийся на фронте Парето. Такой подход особенно важен в областях, где понимание логики работы модели играет ключевую роль, например, в медицине или финансах, позволяя не только прогнозировать результаты, но и обосновывать их.
Исследование демонстрирует возможность создания высокоэффективных и при этом легко интерпретируемых прогностических моделей за счёт явного включения разреженности в процесс оптимизации. Вместо стремления к максимальной сложности, алгоритм нацелен на выявление наиболее значимых факторов, отбрасывая несущественные. Такой подход позволяет не только повысить точность прогнозов, но и существенно упростить понимание логики работы модели, что особенно важно в областях, где требуется прозрачность и доверие к результатам. Разреженность, по сути, является инструментом для отсева «шума» и выделения ключевых взаимосвязей в данных, что ведет к созданию более надежных и понятных моделей.
Предложенная методология оптимизации обобщённых аддитивных моделей (GAM) не ограничивается лишь анализом данных о ценах на жильё в Калифорнии. Разработанный подход представляет собой универсальную основу для построения и тонкой настройки GAM в различных областях и с использованием разнообразных наборов данных. Ключевым является возможность балансировки между точностью предсказаний и интерпретируемостью модели, что позволяет адаптировать алгоритм к специфическим требованиям конкретной задачи, будь то финансовый анализ, медицинская диагностика или прогнозирование спроса. Универсальность фреймворка обеспечивается за счёт возможности настройки параметров, определяющих степень разреженности модели и штраф за сложность, что позволяет находить оптимальные конфигурации для различных типов данных и задач.
В практических задачах машинного обучения часто возникает необходимость балансировать между точностью модели и её интерпретируемостью. Высокая точность не всегда является достаточным условием, особенно в областях, где важна прозрачность и возможность понимания логики принятия решений. Представленное исследование демонстрирует, что намеренное ограничение сложности модели, при одновременной оптимизации точности, позволяет создавать эффективные и понятные прогнозы. Для обеспечения надёжности полученных результатов применялась 5-кратная кросс-валидация, а при расчете штрафа за сложность использовались веса U = 0.70, отражающие важность точности, и S = 0.30, определяющие значимость простоты модели. Такой подход позволяет выбирать оптимальную конфигурацию, соответствующую конкретным требованиям и приоритетам в реальных приложениях.
Исследование демонстрирует, что оптимизация структуры обобщенных аддитивных моделей (GAM) с помощью алгоритма NSGA-II позволяет достичь баланса между предсказательной точностью и интерпретируемостью модели. Этот подход, по сути, представляет собой интеллектуальное «взламывание» системы, выявление оптимальной конфигурации, которая максимизирует производительность, не жертвуя при этом пониманием. Как однажды заметил Пол Эрдёш: «Математика — это искусство открывать закономерности, скрытые в хаосе». Подобно тому, как математик ищет элегантное решение, данная работа стремится к созданию разреженных и интерпретируемых моделей, что является ключом к извлечению полезных знаний из данных.
Куда двигаться дальше?
Представленная работа демонстрирует, что баланс между предсказательной силой и понятностью обобщенных аддитивных моделей (GAM) может быть достигнут посредством эволюционных алгоритмов, в частности NSGA-II. Однако, это лишь первый шаг к пониманию истинной стоимости упрощения. Парето-фронт, полученный в ходе оптимизации, является не конечной целью, а скорее картой потенциальных компромиссов. Следует помнить: каждая «оптимальная» модель — это всего лишь приближение к реальности, а не сама реальность.
Очевидным направлением дальнейших исследований является исследование других эволюционных стратегий и метрик оценки. Вместо слепого следования принципу «чем проще, тем лучше», необходимо разработать более тонкие инструменты для измерения информативности и значимости отдельных компонентов модели. Вопрос о том, как именно «интерпретируемость» соотносится с человеческим пониманием, остается открытым — и, возможно, принципиально неразрешимым.
Настоящая безопасность — в прозрачности, а не в обфускации. Вместо создания «черных ящиков», необходимо стремиться к моделям, которые не только предсказывают, но и объясняют. Задача состоит не в том, чтобы создать идеальную модель, а в том, чтобы понять, почему любая модель несовершенна. Именно в этом несовершенстве и кроется ключ к новому знанию.
Оригинал статьи: https://arxiv.org/pdf/2602.15877.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- Группа Аренадата акции прогноз. Цена DATA
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- Крипто-археология: Снижение активности, накопление BTC и геополитическая неопределенность (09.04.2026 04:45)
- Прогноз нефти
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
- РУСАЛ акции прогноз. Цена RUAL
- Стоит ли покупать доллары за юани сейчас или подождать?
2026-02-19 10:26