Автор: Денис Аветисян
Исследователи представили инновационную систему, позволяющую агентам на базе больших языковых моделей более эффективно исследовать сложные среды и находить оптимальные решения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал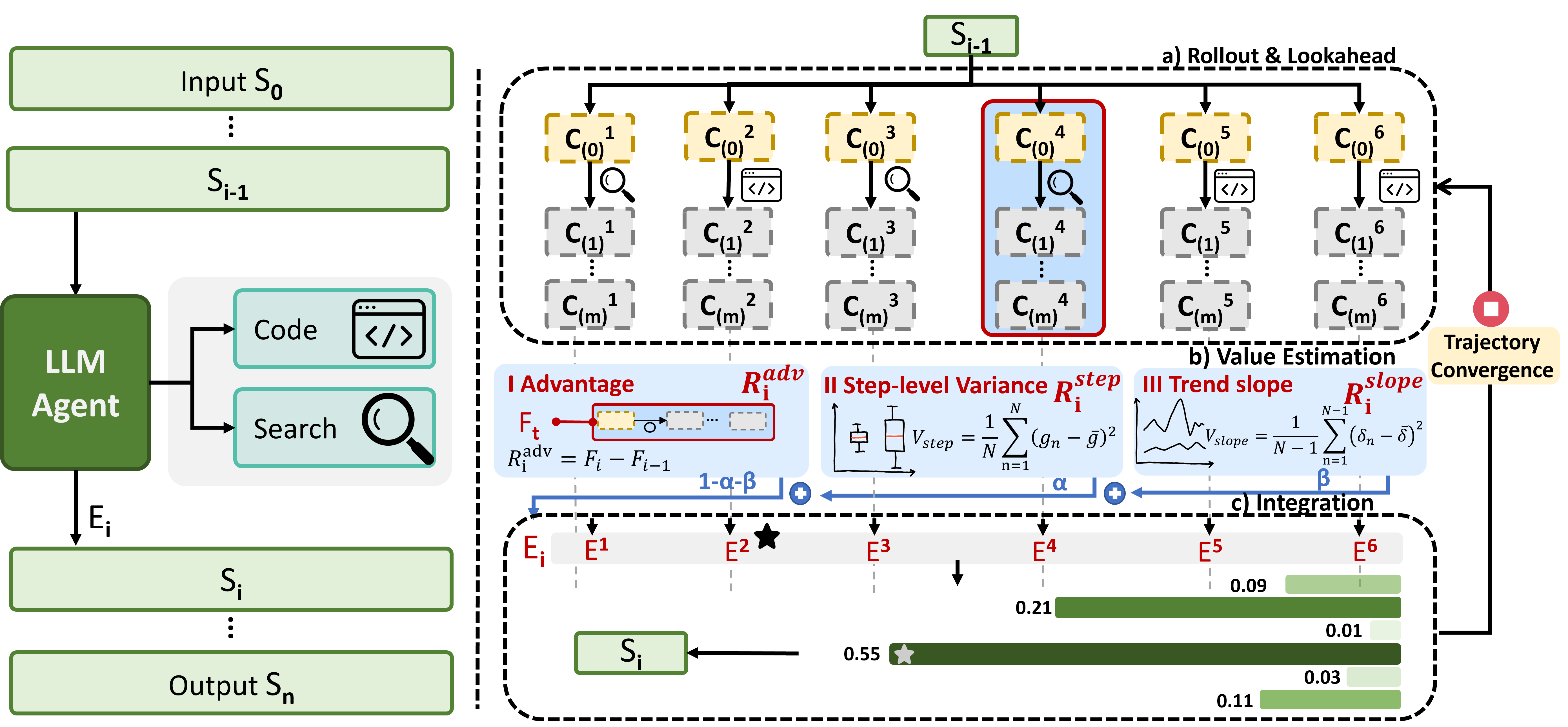
MAXS: Мета-адаптивное исследование с использованием агентов, основанных на больших языковых моделях, сочетает перспективный поиск, стабильную оценку ценности и сходимость траекторий.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в качестве агентов, их рассуждения часто страдают от недальновидности и нестабильности траекторий. В данной работе представлена система ‘MAXS: Meta-Adaptive Exploration with LLM Agents’ — метаадаптивный фреймворк, использующий перспективный поиск, стабильную оценку ценности действий и механизм сходимости траекторий для повышения эффективности и надежности LLM-агентов. Эксперименты на различных моделях и датасетах демонстрируют, что MAXS превосходит существующие методы как по производительности, так и по вычислительной эффективности. Позволит ли предложенный подход создать LLM-агентов, способных решать сложные задачи с высокой степенью уверенности и надежности?
Пределы Традиционного Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющие возможности в обработке и генерации текста, большие языковые модели (БЯМ) зачастую сталкиваются с трудностями при решении сложных задач, требующих последовательного и длительного применения логических операций. В то время как БЯМ превосходно справляются с задачами, основанными на распознавании паттернов и статистической вероятности, многоэтапные рассуждения, включающие планирование, абстракцию и критический анализ информации, представляют собой серьезное препятствие. Это связано с тем, что текущая архитектура БЯМ ориентирована на прогнозирование следующего токена в последовательности, а не на моделирование процесса мышления, требующего поддержания контекста и отслеживания промежуточных выводов на протяжении всей задачи. Поэтому, несмотря на кажущуюся интеллектуальность, БЯМ демонстрируют ограниченные способности в ситуациях, требующих глубокого понимания и последовательного применения когнитивных усилий.
Несмотря на определенный прогресс, достигнутый благодаря методам стимулирования, таким как “Цепочка Мыслей” (Chain of Thought), современные языковые модели демонстрируют хрупкость в задачах, требующих развернутого и последовательного рассуждения. Хотя данный подход и позволяет модели более четко излагать ход своих мыслей, он часто оказывается недостаточно надежным при увеличении длины цепочки рассуждений. Даже незначительные ошибки на ранних этапах могут накапливаться и приводить к существенным неточностям в конечном ответе. Таким образом, несмотря на кажущееся улучшение, сохраняется проблема поддержания логической связности и корректности в сложных, многоступенчатых задачах, что указывает на необходимость поиска более устойчивых и надежных методов организации процесса рассуждения.
Несмотря на впечатляющий прогресс в увеличении масштаба языковых моделей, исследования показывают, что простое наращивание количества параметров не решает проблему сложных, многоступенчатых рассуждений. Увеличение размера моделей, хотя и улучшает некоторые аспекты производительности, не обеспечивает фундаментального прорыва в решении задач, требующих устойчивых когнитивных усилий и способности к последовательному логическому выводу. Это указывает на необходимость разработки принципиально новых архитектур, которые выходят за рамки простого увеличения вычислительных ресурсов и фокусируются на создании механизмов, имитирующих более эффективные и надежные формы рассуждений, присущие человеческому интеллекту. Поиск таких архитектур становится ключевой задачей в развитии искусственного интеллекта, поскольку именно они определят способность моделей к решению действительно сложных и значимых проблем.

MAXS: Мета-Адаптивная Структура для Надежного Рассуждения
MAXS представляет собой новую структуру, предназначенную для расширения возможностей LLM-агентов посредством адаптивных стратегий исследования, что приводит к повышению эффективности рассуждений. В отличие от традиционных методов, полагающихся на фиксированные алгоритмы поиска, MAXS динамически корректирует процесс исследования на основе оценки качества текущих путей рассуждений. Это достигается за счет возможности агента предвидеть потенциальные исходы различных действий и выбирать наиболее перспективные пути, избегая тупиковых ветвей и снижая вероятность ошибок в сложных задачах. Адаптивность стратегий исследования позволяет MAXS эффективно работать в различных средах и с задачами, требующими различных уровней сложности и глубины анализа.
В основе MAXS лежит метод Lookahead Rollout, позволяющий проактивно оценивать различные варианты развития процесса рассуждений. Данный подход заключается в симуляции нескольких последующих шагов для каждого потенциального действия, что позволяет агенту предвидеть возможные ошибки и нежелательные последствия до того, как они приведут к каскадным ошибкам в логической цепочке. В процессе Lookahead Rollout оценивается не только немедленная награда, но и качество каждого пути рассуждений, что обеспечивает более надежное принятие решений и повышение общей эффективности агента.
Эффективность MAXS обусловлена использованием Композитной Функции Ценности (Composite Value Function), которая объединяет немедленное вознаграждение с метриками, оценивающими качество хода рассуждений. В отличие от стандартных подходов, фокусирующихся исключительно на конечном результате, данная функция учитывает промежуточные шаги и их вклад в общую достоверность решения. Это достигается путем включения в оценку таких параметров, как глубина рассуждений, степень согласованности аргументов и вероятность успешного завершения цепочки логических выводов. V(s) = R(s) + \gamma \sum_{a} P(a|s)V(s'), где V(s) — ценность состояния, R(s) — немедленное вознаграждение, γ — коэффициент дисконтирования, P(a|s) — вероятность действия a в состоянии s, а V(s') — ценность следующего состояния. Композитная функция позволяет агенту оценивать и выбирать наиболее перспективные пути рассуждений, даже если они не приводят к немедленному вознаграждению, что повышает устойчивость и точность принимаемых решений.

Количественная Оценка Качества Рассуждений: Метрики Надежности и Плавности
Оценка преимущества (Advantage Score) внутри композиционной функции ценности (C(s,a)) представляет собой расчет ожидаемой будущей награды, получаемой за конкретный шаг рассуждений. Этот показатель используется для направления агента к наиболее перспективным путям решения задачи. Фактически, он определяет, насколько данный шаг улучшает общую оценку состояния по сравнению со средним ожидаемым вознаграждением, позволяя агенту отдавать предпочтение шагам, которые, вероятно, приведут к более высоким результатам. Высокое значение оценки преимущества указывает на то, что данный шаг является выгодным, в то время как отрицательное значение свидетельствует о том, что он может быть контрпродуктивным и его следует избегать.
Дисперсия на уровне шага (Step-Level Variance) представляет собой метрику, оценивающую стабильность отдельных этапов рассуждений. Она измеряет разброс ответов на идентичные или схожие входные данные, генерируемые моделью на каждом шаге логической цепочки. Высокое значение дисперсии указывает на непоследовательность и непредсказуемость модели, что негативно сказывается на общей надежности процесса рассуждений. В процессе обучения или оценки, дисперсия на уровне шага используется как штраф, снижающий итоговый показатель качества, если модель демонстрирует значительные отклонения в ответах при незначительных изменениях входных данных или контекста. Формально, дисперсия рассчитывается как \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 , где x_i — ответ модели на i-й входной сигнал, а μ — среднее значение ответов на схожие входные данные.
Дисперсия на уровне наклона (Slope-Level Variance) представляет собой метрику, оценивающую плавность траектории рассуждений. Она измеряет изменение направления логической цепочки между последовательными шагами. Высокое значение дисперсии указывает на резкие переходы или непоследовательность в логике, что свидетельствует о менее когерентном процессе рассуждения. Метрика вычисляется как \sigma^2 = \frac{1}{N-1} \sum_{i=1}^{N-1} (slope_i - \bar{slope})^2 , где slope_i — наклон траектории между шагами i и i+1 , а \bar{slope} — средний наклон по всей траектории. Низкая дисперсия на уровне наклона указывает на более плавный и логически последовательный процесс рассуждения, что способствует повышению надежности и обоснованности принимаемых решений.
Проверка на Сложных Наборах Данных: Демонстрация Превосходства MAXS
Система MAXS подверглась тщательному тестированию на ряде сложных эталонных наборов данных, включая MATH, OlympiadBench, EMMA и TheoremQA, что позволило продемонстрировать существенные улучшения в производительности. Эти наборы данных, известные своей сложностью и разнообразием математических задач, были использованы для всесторонней оценки способности системы к решению проблем и логическому выводу. Результаты показывают, что MAXS эффективно справляется с задачами, требующими глубокого понимания математических концепций и способности применять их в различных контекстах, превосходя существующие аналоги в решении сложных математических задач и демонстрируя высокий уровень точности и надежности.
Особое внимание заслуживает эффективность предложенного фреймворка на наборе данных MathVista, специально разработанном для оценки способностей к решению сложных научно-технических задач. Этот набор данных, требующий глубокого понимания физических и математических принципов, стал лакмусовой бумажкой для проверки способности системы к абстрактному мышлению и логическому выводу. Результаты показывают, что фреймворк демонстрирует выдающиеся результаты на MathVista, превосходя существующие аналоги в решении задач, требующих интеграции знаний из различных областей науки и применения сложных математических операций. Это свидетельствует о значительном прогрессе в области искусственного интеллекта, способного не просто обрабатывать информацию, но и эффективно применять научные знания для решения сложных проблем.
Результаты всестороннего тестирования показали, что разработанная система MAXS демонстрирует передовые показатели в решении сложных задач логического вывода. На пяти ключевых бенчмарках, включающих MATH, OlympiadBench и другие, система достигла повышения точности до 10.3% по сравнению с существующими решениями. Статистический анализ подтвердил значимость полученных результатов — p-value, равный менее 0.001, указывает на то, что превосходство MAXS над конкурентами не является случайным. Это свидетельствует о высокой эффективности подхода, используемого в MAXS, и открывает новые возможности для автоматизации сложных процессов рассуждения и решения математических задач.
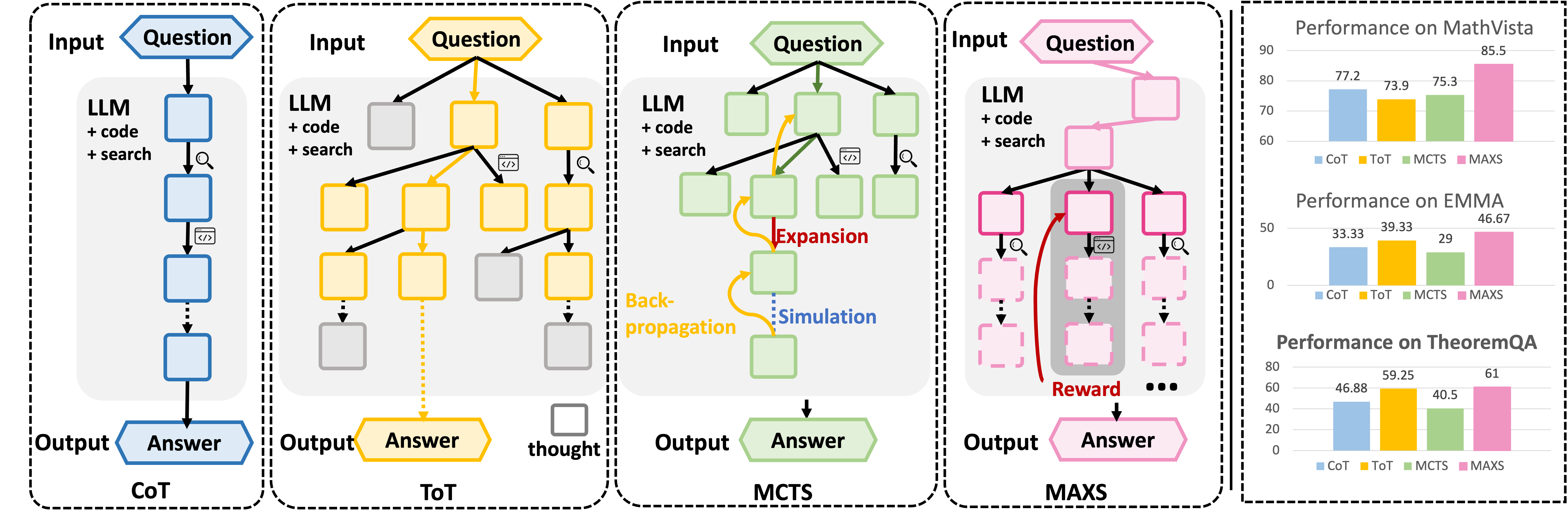
Перспективы Развития: Адаптивное Рассуждение и За Его Пределами
В будущем планируется интеграция усовершенствованных стратегий исследования, таких как «Дерево Мыслей» (Tree of Thought) и «Поиск методом Монте-Карло» (Monte Carlo Tree Search), в рамки платформы MAXS. Эти методы позволяют моделировать процесс рассуждения как построение и исследование дерева возможных вариантов, что значительно повышает эффективность решения сложных задач. В отличие от последовательного подхода, ToT и MCTS позволяют оценить перспективность различных путей решения, выбирая наиболее вероятные и отбрасывая бесперспективные, подобно тому, как человек обдумывает различные варианты перед принятием решения. Ожидается, что внедрение этих стратегий существенно расширит возможности MAXS в области логического вывода, планирования и креативного решения проблем, приближая систему к уровню интеллекта, присущего биологическим организмам.
Расширение набора инструментов, доступных для LLM-агентов, представляет собой ключевой шаг к повышению их способности к рассуждениям. Усовершенствованные инструменты для работы с кодом позволят агентам не только понимать и анализировать программный код, но и самостоятельно генерировать и отлаживать его, что значительно расширит спектр решаемых задач. Параллельно, улучшенные инструменты поиска предоставят доступ к более широкому объему информации и позволят более эффективно извлекать необходимые данные для принятия решений. Комбинация этих двух направлений позволит LLM-агентам решать сложные задачи, требующие как логического мышления, так и доступа к актуальной информации, приближая их к уровню человеческого интеллекта и открывая новые горизонты в области искусственного интеллекта.
Конечная цель исследований направлена на создание поистине адаптивных систем рассуждений, способных эффективно и надежно решать сложные задачи, подобно биологическому интеллекту. Эти системы должны не просто обрабатывать информацию, но и динамически подстраиваться к изменяющимся условиям и новым данным, подобно тому, как это делает человеческий мозг. Разработка таких систем предполагает выход за рамки традиционных алгоритмов и использование принципов, лежащих в основе нейронных сетей и эволюционных процессов. Подобный подход позволит создать искусственный интеллект, обладающий не только мощностью вычислений, но и гибкостью, устойчивостью и способностью к самообучению, что открывает перспективы для решения задач, ранее считавшихся недоступными для автоматизации.

Наблюдается закономерность: системы, стремящиеся к адаптации, неизменно демонстрируют траектории, далекие от прямой линии. В представленной работе MAXS, с её акцентом на мета-адаптивное исследование и стабильную оценку ценности, это особенно заметно. Ведь каждое расширение возможностей агента, каждый новый инструмент — это не просто шаг вперед, а разветвление возможных путей. Как однажды заметил Пол Эрдёш: «Математика — это искусство находить закономерности, а не просто решать задачи». И в контексте разработки подобных систем, закономерность заключается в том, что стремление к совершенству неизбежно порождает сложность, требующую постоянной оценки и адаптации. Стабильность траектории — иллюзия, а сама система — организующийся хаос.
Что дальше?
Представленный подход MAXS, безусловно, демонстрирует улучшение в адаптивном исследовании агентов на основе больших языковых моделей. Однако, он лишь откладывает неизбежное. Каждая оптимизация траектории, каждое усовершенствование оценки ценности — это лишь усложнение системы, увеличение числа точек отказа. Мы разделили задачу на более мелкие части, но не избавили систему от общей хрупкости. Улучшение стабильности — это иллюзия, поскольку любая система, стремящаяся к оптимальности, неизбежно становится более уязвимой к непредсказуемым изменениям среды.
Следующим шагом видится не поиск более совершенных алгоритмов планирования, а принятие факта, что полная предсказуемость недостижима. Вместо стремления к идеальной траектории, необходимо разработать механизмы, позволяющие агентам быстро восстанавливаться после сбоев, адаптироваться к неожиданностям и учиться на собственных ошибках. Поиск устойчивости не в совершенстве алгоритма, а в гибкости архитектуры.
В конечном счете, развитие MAXS и подобных ему систем, вероятно, приведет к созданию еще более сложных и взаимосвязанных архитектур. И, как следствие, к еще более масштабным и непредсказуемым сбоям. Всё связанное когда-нибудь упадёт синхронно. Вопрос лишь в том, когда и насколько болезненно это произойдет.
Оригинал статьи: https://arxiv.org/pdf/2601.09259.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Капитал Б&Т и его душа в AESI
- Почему акции Pool Corp могут стать привлекательным выбором этим летом
- Квантовые Химеры: Три Способа Не Потерять Рубль
- Стоит ли покупать фунты за йены сейчас или подождать?
- Два актива, которые взорвут финансовый Лас-Вегас к 2026
- МКБ акции прогноз. Цена CBOM
- Один потрясающий рост акций, упавший на 75%, чтобы купить во время падения в июле
- Будущее ONDO: прогноз цен на криптовалюту ONDO
- Делимобиль акции прогноз. Цена DELI
- Российский рынок: Рост на фоне Ближнего Востока и сырьевая уверенность на 100 лет (28.02.2026 10:32)
2026-01-15 17:11