Автор: Денис Аветисян
В статье рассматривается, как алгоритмы глубокого обучения с подкреплением превосходят традиционные методы оптимизации портфеля.
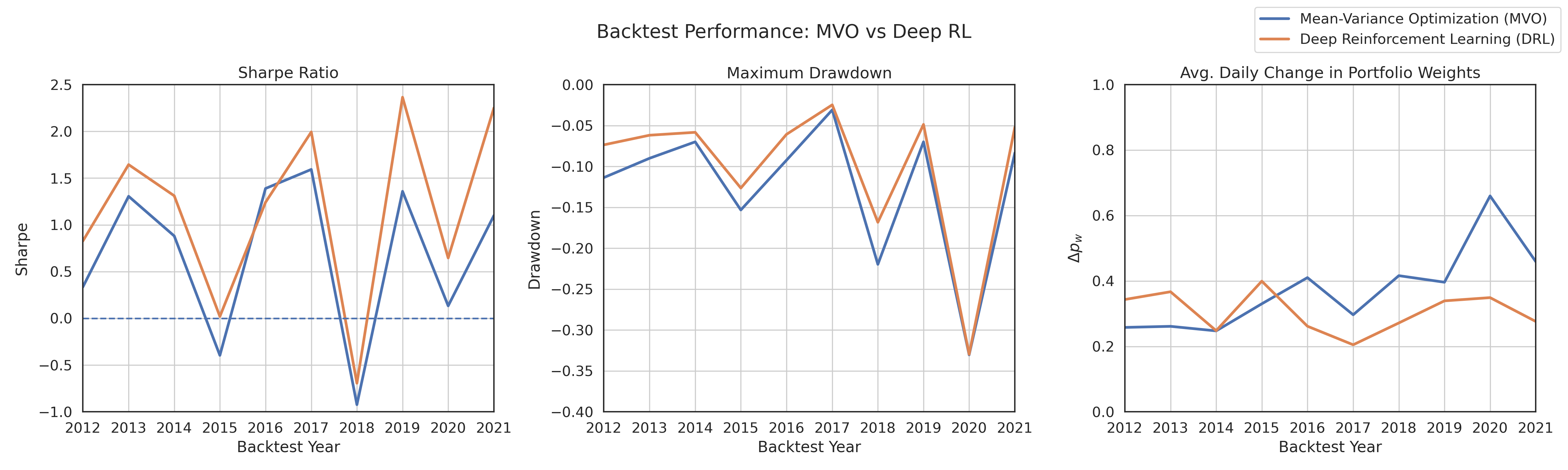
Сравнительное исследование эффективности глубокого обучения с подкреплением и оптимизации по среднему отклонению при управлении инвестиционным портфелем на основе исторических данных рынка США.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм каналНесмотря на широкое использование традиционных методов оптимизации портфеля, их эффективность в условиях динамично меняющихся рынков остается под вопросом. В данной работе, посвященной теме ‘Deep Reinforcement Learning for Optimal Portfolio Allocation: A Comparative Study with Mean-Variance Optimization’, проведено всестороннее сравнение подходов глубокого обучения с подкреплением и классической оптимизации по среднему и отклонению. Полученные результаты демонстрируют, что агент, обученный с использованием методов глубокого обучения с подкреплением, последовательно превосходит традиционную оптимизацию по среднему и отклонению при тестировании на исторических данных. Возможно ли дальнейшее повышение эффективности таких моделей за счет интеграции дополнительных источников информации и разработки более сложных архитектур обучения?
Ограничения Традиционного Подхода к Формированию Портфеля
Традиционное построение инвестиционного портфеля, основанное на принципах современной теории портфеля, предполагает использование статических оценок риска и доходности. Однако, эта методология часто оказывается неэффективной в условиях постоянно меняющихся рыночных реалий. В частности, предполагаемая стабильность исторических данных, используемых для прогнозирования будущей доходности и волатильности, не соответствует действительности. Рынки подвержены непредсказуемым событиям и структурным изменениям, которые приводят к отклонению фактических результатов от первоначальных оценок. Это, в свою очередь, может существенно снизить эффективность портфеля и привести к неоптимальному распределению капитала. Таким образом, статичный подход к оценке рисков и доходности ограничивает способность портфеля адаптироваться к динамике рынка и достигать поставленных инвестиционных целей.
Оптимизация по среднему и отклонению, являясь краеугольным камнем современной теории портфеля, демонстрирует значительную чувствительность к погрешностям в оценках ожидаемой доходности и волатильности активов. Даже незначительные ошибки в этих параметрах могут приводить к формированию неустойчивых портфелей, подверженных резким колебаниям и неоптимальным результатам. Особую проблему представляют транзакционные издержки, которые зачастую игнорируются в классических моделях. Учет комиссий, налогов и других расходов на совершение сделок может существенно снизить эффективность портфеля, особенно при частой ребалансировке, что делает оптимизацию по среднему и отклонению менее надежной в реальных рыночных условиях. \sigma^2 — дисперсия, часто используемая в расчетах, но подверженная влиянию ошибок оценки.
Ограничения традиционного построения портфелей требуют перехода к более устойчивым и адаптивным стратегиям управления активами. Статические модели, основанные на фиксированных оценках риска и доходности, зачастую не способны адекватно реагировать на динамичные изменения рыночной конъюнктуры. Необходимость в подходах, превосходящих рамки статического моделирования, обусловлена потребностью в портфелях, способных сохранять стабильность и прибыльность в условиях повышенной волатильности и неопределенности. Поэтому, всё большее внимание уделяется методам, использующим адаптивные алгоритмы и машинное обучение для постоянной переоценки рисков и возможностей, позволяя инвесторам гибко реагировать на меняющиеся условия и оптимизировать свои инвестиционные стратегии в режиме реального времени.
Обучение с Подкреплением: Адаптивное Решение
Обучение с подкреплением представляет собой принципиально новый подход к автоматизированной торговле на фондовом рынке США, позволяя агенту самостоятельно разрабатывать стратегии посредством проб и ошибок. В отличие от традиционных алгоритмов, требующих четкого программирования правил, агент обучается, взаимодействуя с рыночной средой и получая вознаграждение за прибыльные действия. Этот процесс адаптации позволяет агенту корректировать свою стратегию в реальном времени, реагируя на изменения рыночных условий и не требуя постоянного вмешательства человека. Таким образом, обучение с подкреплением обеспечивает динамическую оптимизацию торговых стратегий, что особенно важно на волатильном рынке ценных бумаг.
Глубокое обучение с подкреплением расширяет возможности обучения агента, используя глубокие нейронные сети для аппроксимации сложных функций ценности и политик. Это позволяет агенту эффективно функционировать в пространствах состояний высокой размерности, характерных для финансовых рынков, таких как рынок акций США. Традиционные методы, как правило, испытывают трудности при работе с большим количеством входных параметров, в то время как глубокие нейронные сети способны извлекать сложные закономерности и обобщать данные, что необходимо для принятия эффективных инвестиционных решений в условиях постоянно меняющейся рыночной конъюнктуры. Использование глубоких нейронных сетей позволяет агенту моделировать нелинейные зависимости между входными данными и ожидаемыми результатами, что значительно повышает его адаптивность и эффективность.
Методы градиентного спуска политики (Policy Gradient Methods) представляют собой семейство алгоритмов обучения с подкреплением, которые непосредственно оптимизируют политику агента, определяющую его действия в заданном состоянии. В отличие от методов, основанных на оценке ценности, методы градиентного спуска политики стремятся найти оптимальную политику путем вычисления градиента функции награды относительно параметров политики. Этот градиент указывает направление, в котором следует изменить параметры политики, чтобы увеличить ожидаемую совокупную награду. В основе лежит принцип, что небольшое изменение в политике, направленное вдоль градиента, приведет к увеличению награды. Алгоритмы, такие как REINFORCE и Actor-Critic, используют различные стратегии для оценки градиента и обновления параметров политики, обеспечивая эффективную оптимизацию в сложных средах и пространствах действий.
Оптимизация Скорректированной на Риск Доходности
Коэффициент Шарпа является ключевым показателем оценки эффективности портфеля, измеряя доходность с поправкой на риск. Он рассчитывается как разница между средней доходностью портфеля и безрисковой ставкой, деленная на стандартное отклонение доходности портфеля. \text{Sharpe Ratio} = \frac{R_p - R_f}{\sigma_p} , где R_p — доходность портфеля, R_f — безрисковая ставка, а \sigma_p — стандартное отклонение доходности портфеля. Однако, статический коэффициент Шарпа имеет ограниченную полезность на динамично меняющемся рынке, поскольку не учитывает изменение волатильности и корреляций активов во времени. Его статическая природа не позволяет эффективно адаптироваться к меняющимся рыночным условиям и может приводить к неоптимальным решениям по управлению портфелем.
В рамках обучения с подкреплением (RL) используется дифференциальный коэффициент Шарпа (Differential Sharpe Ratio) в качестве сигнала вознаграждения. Этот показатель, в отличие от статического коэффициента Шарпа, позволяет агенту RL максимизировать суммарную доходность с учетом риска на протяжении всего периода обучения, что эффективно отражает изменения рыночной конъюнктуры. Применение дифференциального коэффициента Шарпа позволяет агенту динамически адаптироваться к изменяющимся рыночным условиям и оптимизировать портфель для достижения максимальной доходности с учетом риска в каждый момент времени. Фактически, сигнал вознаграждения представляет собой изменение коэффициента Шарпа портфеля по сравнению с предыдущим состоянием, стимулируя агента к принятию решений, которые улучшают риск-доходность.
Результаты проведенных тестов демонстрируют превосходство разработанного DRL-фреймворка над классической оптимизацией «средняя дисперсия» (Mean-Variance Optimization, MVO) в плане достижения скорректированной на риск доходности. В ходе экспериментов DRL-фреймворк достиг значения коэффициента Шарпа 1.17, в то время как MVO показал результат 0.68. Данное различие подтверждает эффективность использования DRL для формирования портфелей с более высокой доходностью при заданном уровне риска.
Повышение Устойчивости Портфеля с Учетом Рыночного Контекста
Включение индекса VIX, как показателя рыночной волатильности, в качестве одного из состояний системы, предоставляет агенту ценную информацию о текущем уровне рыночного риска. Это позволяет ему адаптировать состав портфеля в соответствии с изменяющейся ситуацией, снижая потенциальные убытки в периоды повышенной нестабильности и, наоборот, извлекая выгоду из периодов спокойствия. Агент, обладая информацией о волатильности, может динамически перераспределять активы, увеличивая долю защитных активов при росте VIX и переходя к более агрессивным стратегиям при его снижении. Такой подход позволяет создавать портфели, более устойчивые к неблагоприятным рыночным условиям и способные генерировать более стабильную доходность в долгосрочной перспективе.
В процессе формирования портфеля особое внимание уделяется повышению точности оценки ковариационных матриц, что критически важно для снижения погрешностей и повышения стабильности. Для этого применяется метод Ledoit-Wolf Shrinkage — усовершенствованная техника, позволяющая сгладить оценки дисперсии и ковариации за счет добавления информации о средней дисперсии активов. Этот подход эффективно уменьшает влияние случайных ошибок, особенно при работе с ограниченным объемом данных или при наличии сильно коррелированных активов. В результате, портфель становится менее чувствительным к краткосрочным колебаниям рынка и более устойчивым к потенциальным ошибкам в оценке рисков, что способствует более предсказуемой и надежной доходности.
Исследование демонстрирует, что применение усовершенствованных методов построения портфеля, включающих интеграцию индекса волатильности VIX и алгоритм Ledoit-Wolf Shrinkage, приводит к формированию более устойчивых и адаптируемых инвестиционных стратегий. Результаты показывают, что разработанная стратегия обучения с подкреплением (DRL) обеспечивает приблизительно в 1,85 раза более высокую годовую доходность по сравнению с классическим методом среднего отклонения (MVO), при этом демонстрируя меньшее максимальное падение капитала. Примечательно, что DRL-стратегия характеризуется вдвое меньшим изменением весов портфеля (Δpw) по сравнению с MVO, что потенциально снижает транзакционные издержки и повышает общую эффективность инвестиций.
Исследование демонстрирует превосходство алгоритмов глубокого обучения с подкреплением над традиционной оптимизацией по критерию среднего и отклонения в задаче формирования портфеля активов. Данный подход позволяет достичь более стабильных результатов в ходе бэктестинга на исторических данных американского фондового рынка. Как отмечал Жан-Поль Сартр: «Существование предшествует сущности». В контексте данной работы, алгоритм, лишенный заранее заданных представлений о рынке, формирует свою стратегию, адаптируясь к динамике данных, что и обуславливает его превосходство. Сложность заключается в удалении излишних параметров, а ясность достигается в оптимизированном алгоритме, который находит наиболее эффективное решение, оставляя лишь необходимое.
Что дальше?
Представленная работа, хоть и демонстрирует превосходство подхода, основанного на глубоком обучении с подкреплением, лишь слегка отодвигает завесу над истинной сложностью управления капиталом. Поиск оптимального распределения активов — это не столько техническая задача, сколько экзистенциальный вопрос о преодолении неопределённости. Превосходство над классической оптимизацией по среднему и отклонению — это, скорее, признание несовершенства самой модели, нежели абсолютная истина. Ясность — это минимальная форма любви, и в данном случае, она проявляется в признании ограниченности существующих метрик.
Необходимо двигаться к моделям, способным учитывать не только статистические характеристики рынков, но и их эволюцию, нелинейные зависимости, и, возможно, даже — влияние иррационального поведения участников. Имитация исторических данных — лишь первый шаг. Следующий — создание систем, способных к адаптации в реальном времени, к обучению на новых, непредсказуемых событиях. Проблема не в увеличении количества параметров, а в их осознанном выборе, в создании минималистичной модели, отражающей суть процесса.
Попытки создания «универсального» алгоритма — тщеславие. Более плодотворным представляется путь к созданию набора специализированных агентов, каждый из которых оптимизирован для конкретных рыночных условий. Не стоит искать совершенство в одном решении, лучше стремиться к гибкости и адаптивности. В конечном счёте, задача управления капиталом — это не столько максимизация прибыли, сколько минимизация риска сожаления.
Оригинал статьи: https://arxiv.org/pdf/2602.17098.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- Фракталы на бирже: Новый взгляд на оптимизацию портфеля
- Город как игра: как улучшить жизнь в районах
- Крипто в зоне турбулентности: Геополитика, хаки и перспективы роста XRP (13.04.2026 09:15)
- РУСАЛ акции прогноз. Цена RUAL
- Делимобиль акции прогноз. Цена DELI
- Прогноз нефти
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
2026-02-20 06:35