Автор: Денис Аветисян
Новая теоретическая база показывает, что правильно организованные высокоразмерные данные могут значительно улучшить точность и устойчивость моделей машинного обучения, уделяя приоритетное внимание качеству данных.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал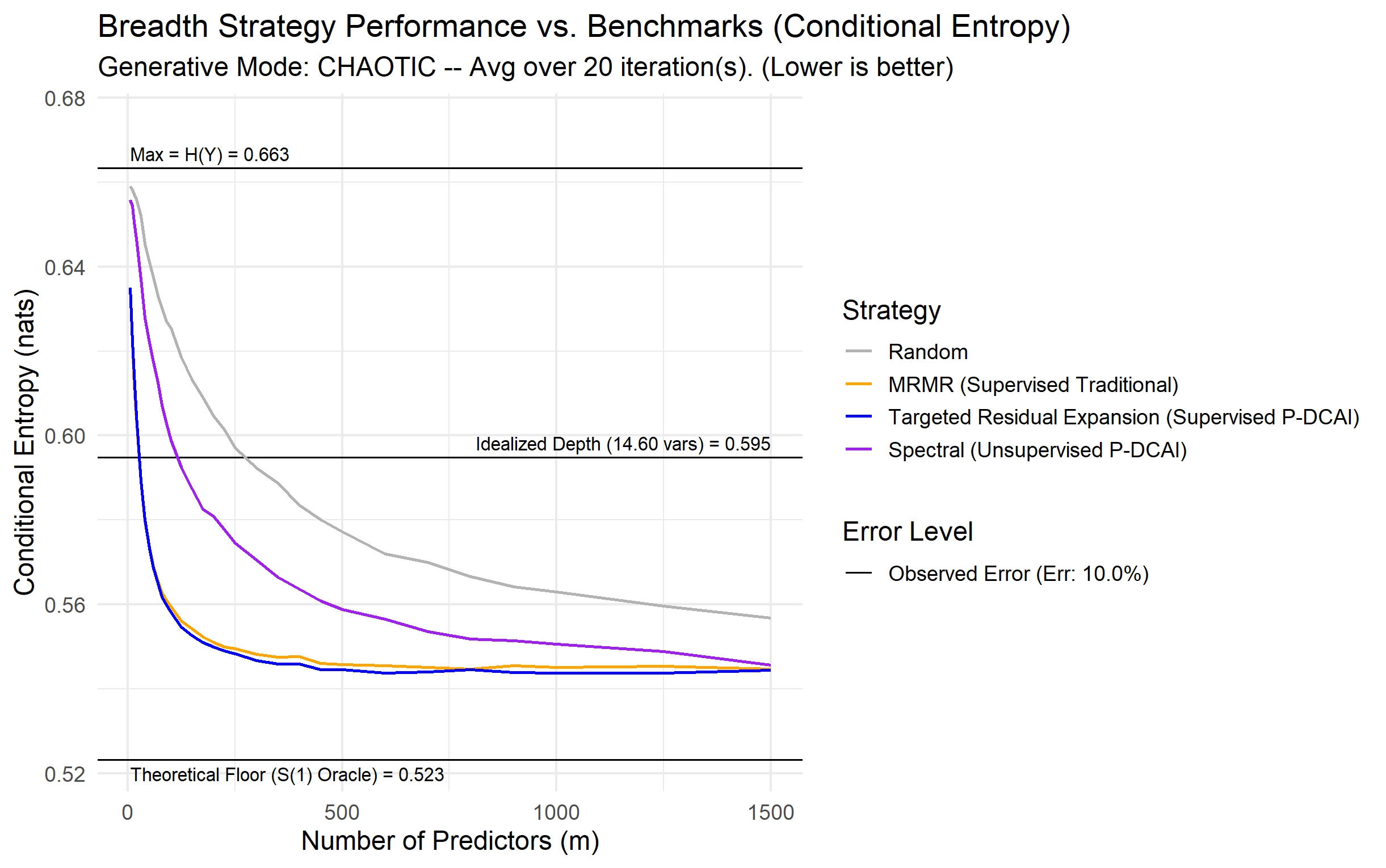
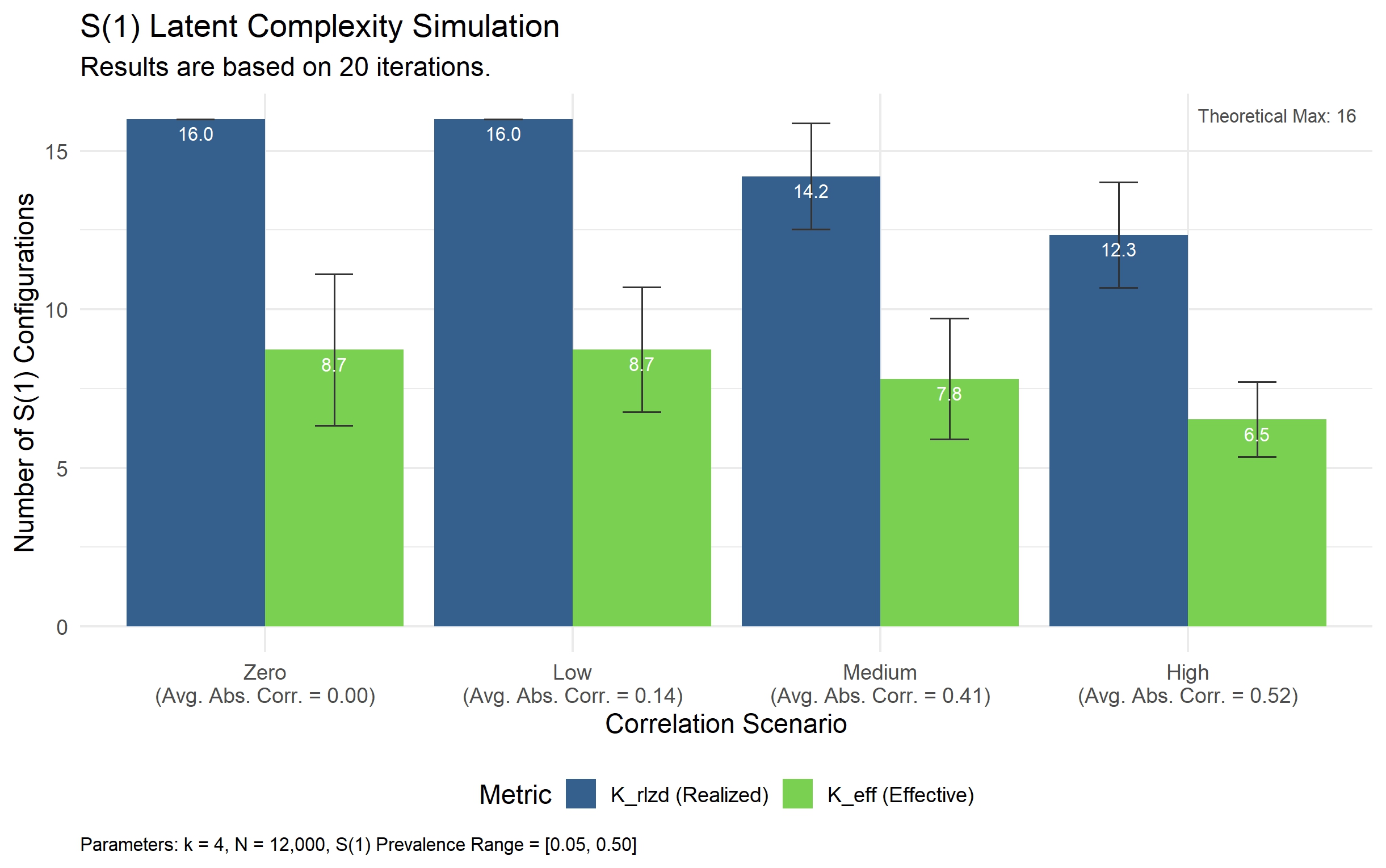
Предлагается G2G — data-centric подход, демонстрирующий, что высокая размерность данных, при правильном управлении, может повысить точность и устойчивость предсказаний, фокусируясь на качестве данных, а не на сложности алгоритмов.
Современное машинное обучение парадоксально демонстрирует высокую эффективность даже при использовании некачественных, многомерных и избыточных данных, противореча принципу «мусор на входе — мусор на выходе». В работе ‘From Garbage to Gold: A Data-Architectural Theory of Predictive Robustness’ предложена теоретическая основа, объясняющая, что устойчивость моделей к шумам обусловлена не столько очисткой данных, сколько синергией между их архитектурой и способностью модели к обучению. Авторы показывают, что корректное использование высокоразмерных данных позволяет асимптотически преодолевать как ошибки в измерениях, так и структурную неопределенность, в то время как очистка данных низкой размерности ограничена последней. Не является ли это теоретическое обоснование отправной точкой для нового подхода к Data-Centric AI, позволяющего эффективно использовать «сырые» данные из корпоративных источников?
Вызов Согласования: Направление LLM к Человеческим Намерениям
Современные большие языковые модели демонстрируют впечатляющую способность генерировать текст, однако обеспечение соответствия этих результатов человеческим предпочтениям представляет собой серьезную задачу. Несмотря на кажущуюся плавность и связность сгенерированного контента, модели часто сталкиваются с трудностями в понимании нюансов человеческого намерения, что может приводить к нежелательным или даже вводящим в заблуждение ответам. Эта проблема особенно актуальна в контексте сложных запросов, требующих критического мышления, этических оценок или учета культурных особенностей. Попытки скорректировать поведение моделей с помощью традиционных методов часто оказываются сложными и ресурсоемкими, что препятствует их широкому внедрению в практические приложения и требует дальнейших исследований в области согласования искусственного интеллекта с человеческими ценностями.
Традиционные подходы к управлению поведением больших языковых моделей (LLM) зачастую оказываются избыточно сложными и требуют значительных вычислительных ресурсов. Это связано с необходимостью детальной проработки всех возможных сценариев взаимодействия и применения сложных алгоритмов обучения с подкреплением. В результате, развертывание LLM в реальных приложениях, особенно на устройствах с ограниченными ресурсами, становится затруднительным и экономически невыгодным. Сложность заключается не только в объеме вычислений, но и в трудоемкости настройки и поддержания таких систем, что создает барьер для широкого внедрения передовых языковых технологий. Поиск более эффективных и экономичных методов контроля над LLM является ключевой задачей для дальнейшего развития этой области.
Обучение с Подкреплением на Основе Обратной Связи: Сложный Подход
Обучение с подкреплением на основе обратной связи от человека (RLHF) представляет собой перспективный подход к задаче согласования больших языковых моделей (LLM) с намерениями пользователя. В отличие от традиционных методов обучения, RLHF использует прямую оценку качества генерируемых LLM текстов, предоставляемую людьми-оценщиками. Эти оценки используются для формирования сигнала вознаграждения, который, в свою очередь, направляет процесс обучения модели, побуждая ее генерировать тексты, соответствующие предпочтениям человека. Такой подход позволяет преодолеть трудности, связанные с определением сложных целевых функций, и добиться более естественного и полезного поведения LLM, особенно в задачах, требующих субъективной оценки качества, таких как генерация творческих текстов или ответы на открытые вопросы.
Обучение с подкреплением на основе обратной связи от человека (RLHF) функционирует посредством двух ключевых этапов. Сначала создается модель вознаграждения (Reward Model), которая обучается предсказывать предпочтения человека относительно различных выходных данных языковой модели. Затем, на этапе обучения политики (Policy Learning), языковая модель корректирует свое поведение, стремясь максимизировать предсказанное вознаграждение от модели вознаграждения. Для обеспечения стабильности процесса обучения и предотвращения отклонения от исходного распределения, часто применяется KL-дивергенция — мера расхождения между распределениями вероятностей, которая штрафует за значительные изменения в поведении модели по сравнению с ее первоначальным состоянием. KL(P||Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)}
Обучение с подкреплением на основе обратной связи от человека (RLHF), несмотря на свою эффективность в согласовании больших языковых моделей (LLM) с человеческими предпочтениями, характеризуется высокой сложностью. Реализация RLHF требует значительных вычислительных ресурсов для обучения как модели вознаграждения, предсказывающей оценки человека, так и самой LLM, использующей эти прогнозы для улучшения своей политики. Процесс требует тщательной настройки множества компонентов, включая функции вознаграждения, гиперпараметры обучения и механизмы стабилизации, такие как расхождение Кульбака-Лейблера KL-дивергенция, для предотвращения отклонения модели от желаемого поведения и обеспечения стабильности обучения. Эффективная реализация RLHF также требует сбора и аннотации большого объема данных обратной связи от человека, что само по себе является ресурсоемкой задачей.
Прямая Оптимизация Предпочтений: Упрощенная Стратегия Согласования
Прямая оптимизация предпочтений (DPO) представляет собой упрощенный подход к согласованию больших языковых моделей (LLM), который позволяет напрямую оптимизировать политику модели на основе данных о предпочтениях, без необходимости в явном моделировании вознаграждения. Традиционные методы, такие как обучение с подкреплением на основе обратной связи от человека (RLHF), требуют отдельного этапа обучения модели вознаграждения, что усложняет процесс и может приводить к нестабильности. DPO обходит этот этап, используя данные о ранжировании результатов, предоставленные людьми, для непосредственного обновления параметров политики модели, что позволяет добиться более стабильного и эффективного согласования.
Алгоритм Direct Preference Optimization (DPO) использует набор данных предпочтений, состоящий из пар ответов, ранжированных человеком по степени предпочтения. Обучение политики происходит посредством минимизации функции потерь Binary Cross-Entropy (BCE). Эта функция потерь оценивает разницу между предсказанными вероятностями предпочтения модели и фактическими предпочтениями, указанными в наборе данных. Использование BCE позволяет эффективно обучать политику, напрямую максимизируя вероятность выбора предпочтительного ответа, и избегать необходимости в промежуточном обучении модели вознаграждения. Формула функции потерь BCE для DPO выглядит следующим образом: L = -log(\sigma(β log(π_θ(x|y)) - β log(π_θ(x|y')))) , где π_θ — политика, x — входной запрос, y и y' — предпочтительный и непредпочтительный ответы соответственно, а β — коэффициент, регулирующий силу регуляризации.
Оптимизация по предпочтениям (DPO) обеспечивает более стабильный и вычислительно эффективный процесс согласования больших языковых моделей (LLM) по сравнению с традиционными методами обучения с подкреплением на основе обратной связи от человека (RLHF). RLHF требует обучения отдельной модели вознаграждения, что вносит дополнительную сложность и потенциальную нестабильность. DPO обходит этот этап, напрямую оптимизируя политику модели на основе данных о предпочтениях, что снижает вычислительные затраты и упрощает процесс обучения. Это достигается за счет использования бинарной кросс-энтропийной функции потерь L_{DPO} для максимизации вероятности выбора предпочтительного ответа, что позволяет модели быстрее сходиться к желаемому поведению и избегать проблем, связанных с неточным или нестабильным обучением модели вознаграждения.
Оценка DPO: Производительность, Стабильность и Эффективность
Экспериментальные исследования показали, что метод DPO (Direct Preference Optimization) демонстрирует сопоставимую, а в ряде случаев и превосходящую производительность по сравнению с RLHF (Reinforcement Learning from Human Feedback) в задаче согласования больших языковых моделей (LLM) с человеческими предпочтениями. В ходе тестов, DPO успешно обучал модели генерировать ответы, которые соответствуют ожиданиям людей, причем часто с более высокой точностью и последовательностью. Особенно заметно превосходство DPO в сценариях, требующих тонкого понимания нюансов человеческих оценок и генерации более естественных и убедительных текстов. Полученные результаты подтверждают, что DPO является перспективной альтернативой RLHF для создания LLM, ориентированных на пользователя и способных эффективно взаимодействовать с людьми.
Исследования показывают, что метод Direct Preference Optimization (DPO) демонстрирует повышенную стабильность в процессе обучения больших языковых моделей. В отличие от Reinforcement Learning from Human Feedback (RLHF), который склонен к расхождениям в политике и непредсказуемому поведению, DPO позволяет существенно снизить риск отклонения от желаемого поведения модели. Это достигается за счет упрощенной процедуры обучения, избегающей сложных этапов оценки и оптимизации, что обеспечивает более предсказуемую и надежную работу модели даже при длительном обучении. Повышенная стабильность DPO позволяет избежать необходимости в частой корректировке параметров и снижает вероятность получения нежелательных результатов, что делает его более практичным и эффективным инструментом для разработки и внедрения языковых моделей.
Исследования показали, что метод Direct Preference Optimization (DPO) демонстрирует значительное снижение вычислительных затрат и повышение эффективности использования данных по сравнению с традиционным обучением с подкреплением на основе человеческих предпочтений (RLHF). Это достигается за счет упрощения процесса обучения, позволяя модели быстрее сходиться к желаемому поведению при меньшем количестве необходимых обучающих примеров. В результате, DPO становится особенно привлекательным для практического применения в сценариях, где ресурсы ограничены, или требуется быстрое развертывание моделей, например, в мобильных устройствах или при работе с большими объемами данных. Снижение вычислительной сложности делает возможным обучение и тонкую настройку больших языковых моделей (LLM) с меньшими затратами энергии и времени, открывая новые возможности для широкого внедрения подобных технологий.
Данное исследование, представляющее концепцию G2G, подчеркивает важность качественных данных в условиях высокой размерности. Авторская работа демонстрирует, что приоритет следует отдавать не сложности алгоритмов, а информационной избыточности и взаимосвязи данных. В этом контексте, слова Барбары Лисков: «Хороший дизайн — это когда система настолько проста, что кажется очевидной» — особенно актуальны. Простота и ясность структуры данных, обеспечивающие корректность и предсказуемость результатов, являются фундаментом надежного и устойчивого искусственного интеллекта. Акцент на данных, а не на алгоритмах, позволяет создавать системы, которые не просто «работают на тестах», но и демонстрируют истинную устойчивость к новым, ранее не встречавшимся данным.
Куда же дальше?
Представленная работа, демонстрируя потенциал высокой размерности при адекватном управлении данными, лишь приоткрывает дверь в область, где качество данных превосходит сложность алгоритмов. Однако, вопрос о том, как объективно оценивать и гарантировать «информативное избыточность» в реальных, зашумленных наборах данных, остаётся открытым. Необходимы более строгие математические инструменты для определения границ между полезным избыточностью и бесполезным шумом, особенно в контексте нелинейных зависимостей.
Дальнейшие исследования должны быть направлены на разработку адаптивных методов очистки и обогащения данных, способных автоматически выявлять и устранять источники систематических ошибок. Важно помнить, что любое упрощение модели неизбежно влечёт за собой потерю информации, а значит, необходимо искать баланс между точностью и обобщающей способностью. Идеальное решение, вероятно, лежит в области принципиально новых подходов к представлению данных, позволяющих извлекать максимальную пользу из их внутренней структуры.
В конечном счете, задача состоит не в том, чтобы создать «идеальный» алгоритм, а в том, чтобы построить систему, способную самостоятельно оценивать и улучшать качество данных, подобно тому, как живой организм адаптируется к изменяющейся среде. И тогда, возможно, мы сможем приблизиться к созданию действительно «робастных» моделей, способных предсказывать будущее с большей уверенностью.
Оригинал статьи: https://arxiv.org/pdf/2603.12288.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Будущее TAO: прогноз цен на криптовалюту TAO
- Стоит ли покупать доллары за индонезийские рупии сейчас или подождать?
- Геополитические риски и динамика рубля: анализ финансовых рынков на 28 июля 2025 18:00
- ПИК акции прогноз. Цена PIKK
- Хрупкие стабильные монеты и восход XRP: Анализ инфраструктурных рисков и перспектив развития (18.06.2026 04:45)
- Магнитогорский металлургический комбинат акции прогноз. Цена MAGN
- Самообучающиеся сети 5G: как обеспечить надежность и безопасность
- Атомные перспективы: NuScale против Oklo
2026-03-17 04:17