Автор: Денис Аветисян
Новый подход позволяет большим языковым моделям повысить надежность длинных текстов, заменяя сомнительные утверждения на более общие, но проверенные.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал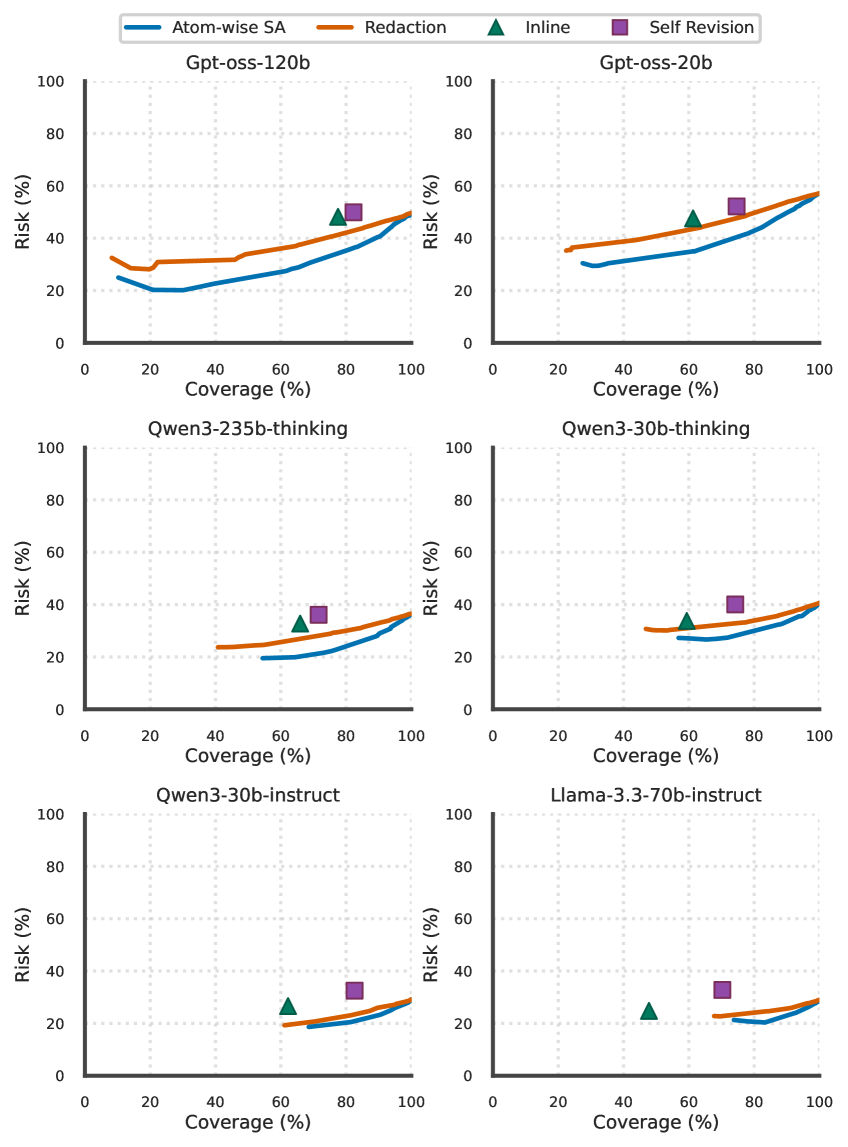
Исследование представляет метод селективной абстракции для улучшения баланса между информативностью и фактической точностью в генерации текста.
Несмотря на широкое распространение, большие языковые модели (LLM) по-прежнему склонны к фактическим ошибкам, снижающим доверие пользователей. В работе ‘When Should LLMs Be Less Specific? Selective Abstraction for Reliable Long-Form Text Generation’ предложен подход, позволяющий LLM находить баланс между точностью и надежностью путем выборочного снижения детализации неопределенной информации. Авторы представляют Selective Abstraction (SA) — фреймворк, заменяющий низкоуверенные утверждения на более общие, но достоверные, что повышает точность генерируемого текста без значительной потери смысла. Может ли эта стратегия выборочного абстрагирования стать ключевым шагом к созданию более надежных и полезных LLM для критически важных приложений?
Преодолевая Неопределенность: Вызовы Генерации Длинных Текстов
Несмотря на впечатляющий прогресс в области больших языковых моделей, создание последовательного, фактического и связного текста большой формы остается серьезной проблемой. Современные модели часто демонстрируют способность генерировать правдоподобные, но не всегда достоверные утверждения, особенно при переходе от коротких ответов к развернутым повествованиям или аналитическим текстам. Эта сложность обусловлена тем, что модели обучаются на огромных объемах данных, включающих как истинную информацию, так и ошибки, предвзятости и устаревшие сведения. В результате, модель может уверенно представлять ложные или необоснованные утверждения как факты, что ставит под сомнение надежность автоматически сгенерированного контента и требует разработки новых методов контроля качества и проверки достоверности.
Существенная проблема в создании длинных текстов с помощью языковых моделей заключается в сложности количественной оценки и контроля неопределенности в процессе генерации. Модели, даже самые передовые, не всегда способны достоверно оценить вероятность истинности генерируемой информации, что приводит к появлению потенциально вводящих в заблуждение или фактически неверных утверждений. Эта неопределенность проявляется в различных формах, включая неспособность отличить правдоподобные, но ложные факты, или же генерацию логически несогласованных последовательностей. В результате, даже при внешне связном тексте, существует риск получения информации, требующей тщательной проверки, что снижает доверие к автоматически сгенерированному контенту и подчеркивает необходимость разработки методов управления и отображения этой внутренней неопределенности.
![В рамках фреймворка Selective Abstraction текст разбивается на атомы, при этом атомы с низкой степенью уверенности заменяются на надежные абстракции, в данном примере с порогом уверенности в [latex]85\%[/latex].](https://arxiv.org/html/2602.11908v1/x3.png)
Оценка Уверенности: Измерение Веры Модели
Назначение оценок достоверности генерируемым утверждениям является критически важным для фильтрации недостоверной информации, однако традиционные методы зачастую демонстрируют плохую калибровку. Это означает, что заявленная моделью уверенность в ответе не всегда соответствует фактической вероятности его правильности. Например, ответ, оцененный моделью как «90% уверенный», может оказаться неверным в значительном проценте случаев. Некорректная калибровка ограничивает возможности использования оценок достоверности для надежного ранжирования и отсева ложных утверждений, что особенно важно в приложениях, требующих высокой точности и надежности генерируемого контента.
Для количественной оценки уверенности модели в сгенерированных утверждениях применяются различные методы, среди которых LogLikelihood и VerbalizedConfidence. Результаты тестирования показывают, что VerbalizedConfidence демонстрирует наивысшее значение AUROC (Area Under the Receiver Operating Characteristic curve), что свидетельствует о его превосходной способности ранжировать и выявлять неверные элементы (atoms) в генерируемом тексте. Высокий показатель AUROC указывает на более точное разграничение между корректной и некорректной информацией, что делает VerbalizedConfidence предпочтительным методом для оценки надежности отдельных фрагментов генерируемого контента.
Эффективная оценка достоверности требует гранулярного подхода, заключающегося в анализе надежности отдельных фрагментов информации, а не всего сгенерированного текста в целом. Оценка достоверности на уровне отдельных “атомов” (фактических утверждений) позволяет более точно выявлять и фильтровать недостоверные данные. Такой подход позволяет избежать ситуации, когда в целом связный и логичный текст содержит отдельные ошибочные утверждения, которые могут остаться незамеченными при оценке достоверности всего текста как единого целого. Подобная детализация особенно важна в задачах, требующих высокой точности и надежности генерируемой информации.
![На диаграмме, отображающей зависимость риска от покрытия для FactScore с использованием модели gpt-oss-120b, вербализованная уверенность превосходит оценку [latex]P( ext{true})[/latex] и наиболее эффективный логарифмический baseline (вероятность логарифма) в снижении AURC.](https://arxiv.org/html/2602.11908v1/x7.png)
Селективная Абстракция: Баланс между Точностью и Надежностью
Селективная абстракция представляет собой новый подход к балансировке фактической точности и информационного охвата при генерации длинных текстов. В отличие от традиционных методов, которые стремятся к максимальной детализации, данный фреймворк сознательно снижает специфичность информации в тех областях, где модель испытывает неуверенность. Это достигается путем идентификации и переформулировки «атомов» информации — базовых утверждений, из которых состоит текст — с целью уменьшения вероятности генерации ложных или неточных данных. Приоритет отдается надежности информации, даже за счет некоторого снижения ее детализации и объема, что позволяет повысить общую достоверность генерируемого контента.
Метод селективной абстракции использует оценку достоверности и атомизацию для выявления и уточнения неуверенных утверждений. Оценка достоверности, генерируемая языковой моделью, применяется к каждому «атому» — минимальной единице информации — для определения степени уверенности в его истинности. В случае низкой достоверности, происходит снижение специфичности утверждения путем обобщения или удаления деталей, что уменьшает вероятность распространения ложной информации. Это не приводит к полной потере информации, а к повышению надежности генерируемого текста за счет уменьшения риска неточностей.
Метод избирательной абстракции снижает риск распространения ложной информации за счет целенаправленного уменьшения информационного содержания низкоконфиденциальных “атомов” данных. Это достигается путем упрощения или обобщения утверждений, в которых модель имеет низкую уверенность, что позволяет повысить надежность генерируемого текста. Экспериментальные данные, полученные на различных больших языковых моделях (LLM) и наборах данных, демонстрируют улучшение компромисса между риском и охватом информации, что подтверждается более низким значением площади под кривой риск-охват (AURC) по сравнению с существующими базовыми методами. Более низкий показатель AURC указывает на то, что метод позволяет достичь более высокого уровня надежности при сохранении приемлемого объема генерируемой информации.

Поиск Баланса: Последствия для Достоверного Искусственного Интеллекта
В основе подхода селективной абстракции лежит фундаментальное противоречие между полнотой охвата информации и обеспечением её достоверности. Данное противоречие, известное как компромисс между риском и охватом, представляет собой серьезную проблему для современных систем искусственного интеллекта, стремящихся генерировать длинные тексты. Стремление к максимальному включению деталей часто приводит к увеличению вероятности ошибок и неточностей, в то время как чрезмерная осторожность и упрощение могут привести к потере важной информации и снижению полезности генерируемого текста. Эффективное управление этим компромиссом является ключевым фактором для создания надежных и заслуживающих доверия систем искусственного интеллекта, способных предоставлять точную и всестороннюю информацию.
Разработка систем искусственного интеллекта, осознанно учитывающих компромисс между объемом предоставляемой информации и её достоверностью, открывает путь к формированию доверия со стороны пользователей. Вместо стремления к максимальному охвату данных, часто сопровождающемуся увеличением вероятности ошибок, создание ИИ, способного взвешенно подходить к представлению информации, позволяет достичь большей надёжности и, как следствие, повысить уверенность в результатах его работы. Такой подход, фокусирующийся на демонстрации обоснованности и точности, становится ключевым фактором для принятия и широкого внедрения технологий искусственного интеллекта в различных сферах деятельности, где достоверность информации имеет первостепенное значение.
Селективное абстрагирование представляет собой существенный прогресс в создании длинных текстов, отличающихся одновременно полнотой и достоверностью, что способствует повышению доверия к контенту, генерируемому искусственным интеллектом. Результаты эмпирических исследований последовательно демонстрируют улучшение баланса между риском и охватом информации, что позволяет создавать системы, способные предоставлять развернутые ответы без ущерба для точности и надежности. Данный подход позволяет ИИ не просто генерировать текст, но и формировать осмысленные и проверенные сведения, что особенно важно для областей, требующих высокой степени ответственности и точности, таких как наука, образование и журналистика.
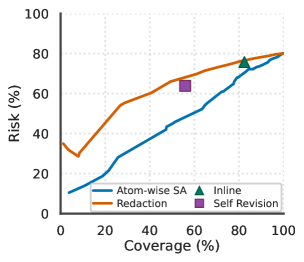
Исследование демонстрирует, что системы, подобные большим языковым моделям, способны к адаптации и выбору стратегий, обеспечивающих надежность генерации длинных текстов. Авторы предлагают механизм избирательной абстракции, позволяющий моделям осознанно снижать уровень детализации в областях с низкой уверенностью. Этот подход напоминает мудрость, высказанную Блез Паскалем: «Все великие вещи приходят от человека, который умеет ждать». Подобно тому, как система откладывает детализацию для обеспечения общей надежности, так и время играет ключевую роль в создании устойчивых и достоверных результатов. Вместо борьбы с неизбежной неопределенностью, модель учится интегрировать её в процесс генерации, подобно тому, как мудрая система не стремится избежать энтропии, а дышит вместе с ней.
Что дальше?
Представленный подход к выборочной абстракции, несомненно, представляет собой коммит в летопись усовершенствования больших языковых моделей. Однако, как и любой коммит, он выявляет новые области для исследований. Вопрос не в том, чтобы заставить модель выдавать больше фактов, а в том, чтобы научить её достойно признавать свою неопределенность. Текущая реализация, по сути, является лишь первым шагом к созданию системы, способной динамически адаптировать уровень детализации в зависимости от контекста и собственных ограничений.
Задержка в исправлении неизбежных ошибок — это налог на амбиции, и в данном случае, амбиция заключается в создании действительно надежных систем генерации текста. Дальнейшие исследования должны сосредоточиться на более изящных механизмах оценки уверенности, а также на разработке методов, позволяющих модели не просто заменять факты, но и указывать на потенциальные пробелы в знаниях. В конечном итоге, задача состоит в том, чтобы создать не просто генератор текста, а партнера в процессе познания.
Каждая версия — это глава, и данная работа открывает новую главу в понимании компромисса между информативностью и надежностью. Будущие исследования, вероятно, будут направлены на интеграцию выборочной абстракции с другими методами повышения надежности, такими как обучение с подкреплением и верификация фактов. Ведь системы стареют — вопрос лишь в том, делают ли они это достойно.
Оригинал статьи: https://arxiv.org/pdf/2602.11908.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- Будущее FET: прогноз цен на криптовалюту FET
- АЛРОСА акции прогноз. Цена ALRS
- Российский рынок: Снижение производства, стабильный банковский сектор и ускорение инфляции (26.03.2026 01:32)
- Супернус: Продажа Акций и Нервные Тики
- ПИК акции прогноз. Цена PIKK
- СириусXM: Пыль дорог и звон монет
- ЛУКОЙЛ акции прогноз. Цена LKOH
- ЕвроТранс акции прогноз. Цена EUTR
2026-02-14 19:10