Автор: Денис Аветисян
Исследователи предлагают инновационный метод обучения нескольких агентов, основанный на диффузионных моделях, позволяющий добиться эффективной координации в сложных задачах.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Алгоритм OMAD демонстрирует стабильное и скоординированное поведение агентов в четырех различных задачах MAMuJoCo, о чем свидетельствуют последовательные снимки их состояний в моменты времени [latex]t \in \{1, 100, 250, 500\}[/latex] и мгновенная скорость, подтверждающие эффективность подхода.](https://arxiv.org/html/2602.18291v1/figure/swimmer2x1_frames.jpg)
Представлен OMAD — онлайн-фреймворк для обучения с подкреплением, сочетающий диффузионные политики с централизованным распределенным критиком для достижения передовых результатов.
Эффективная координация в многоагентном обучении с подкреплением (MARL) часто затруднена недостаточной выразительностью политик. В данной работе, ‘Diffusing to Coordinate: Efficient Online Multi-Agent Diffusion Policies’, предложен новый подход, использующий диффузионные модели для повышения способности агентов к координации в онлайн-среде. Ключевым результатом является разработка фреймворка OMAD, сочетающего диффузионные политики с централизованным распределенным критиком для достижения передовых результатов в сложных координационных задачах. Не откроет ли это новые горизонты для создания более гибких и эффективных систем MARL, способных решать задачи, недоступные для традиционных методов?
Сложность Координации в Многоагентных Системах
Традиционные алгоритмы обучения с подкреплением для многоагентных систем, такие как MADDPG, часто демонстрируют ограниченную эффективность в сложных, децентрализованных средах. Проблема заключается в том, что каждый агент должен принимать решения, основываясь на неполной информации о состоянии окружающей среды и действиях других агентов. В условиях высокой динамичности и сложности взаимодействия агентам становится трудно выучить оптимальные стратегии, поскольку пространство возможных состояний и действий экспоненциально растет. Это приводит к замедлению обучения, нестабильности и низкой эффективности в достижении общих целей, особенно когда агенты не могут напрямую обмениваться информацией или полагаться на централизованного координатора. В результате, стандартные алгоритмы часто застревают в локальных оптимумах или не способны адаптироваться к меняющимся условиям среды, что подчеркивает необходимость разработки новых подходов к обучению многоагентных систем.
Для достижения эффективной координации в многоагентных системах недостаточно простого обучения оптимальным стратегиям поведения. Важным аспектом является также способность агентов эффективно исследовать пространство возможных действий и обмениваться информацией друг с другом. Неэффективное исследование может привести к застреванию в локальных оптимумах, препятствуя достижению глобально оптимального решения. В свою очередь, недостаточный обмен информацией ограничивает способность агентов учитывать действия других, что снижает общую эффективность системы. Поэтому, современные исследования направлены на разработку алгоритмов, которые позволяют агентам не только учиться, но и активно исследовать окружение, а также эффективно коммуницировать, чтобы совместно решать сложные задачи и адаптироваться к изменяющимся условиям.
Парадигма централизованного обучения и децентрализованного исполнения (CTDE) представляется перспективным подходом к решению задач координации в многоагентных системах, однако её практическая реализация сталкивается с рядом трудностей. Основная проблема заключается в масштабируемости: по мере увеличения числа агентов сложность централизованного обучения экспоненциально возрастает, что требует значительных вычислительных ресурсов и времени. Кроме того, модели, обученные в контролируемой среде централизованного обучения, зачастую демонстрируют низкую обобщающую способность при переходе к реальным, динамичным условиям, где агенты взаимодействуют с непредсказуемыми средами и другими агентами. Разработка эффективных методов для уменьшения вычислительной нагрузки и повышения устойчивости к изменениям окружающей среды является ключевой задачей для успешного применения CTDE в сложных многоагентных системах.
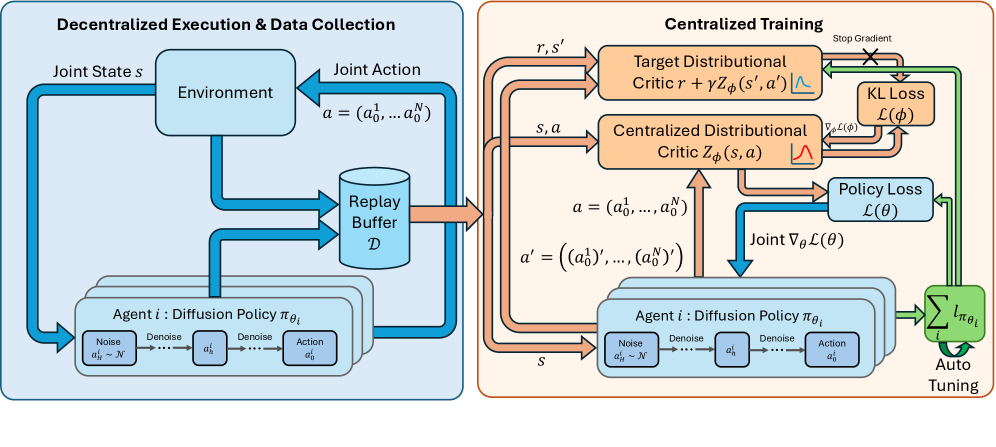
OMAD: Онлайн-Фреймворк Диффузионных Политик для Многоагентного Обучения
OMAD использует диффузионные политики для генерации разнообразных и выразительных распределений действий, что способствует надежному исследованию пространства состояний. В отличие от детерминированных или гауссовских политик, диффузионные модели позволяют агентам генерировать широкий спектр возможных действий, учитывая как вероятные, так и менее вероятные варианты. Этот подход основан на постепенном добавлении шума к целевым действиям в процессе обучения, а затем на обучении модели для удаления этого шума и восстановления действий. В результате, агенты могут более эффективно исследовать неопределенные состояния, избегать преждевременной сходимости к локальным оптимумам и находить более оптимальные стратегии в сложных многоагентных средах. Использование диффузионных политик позволяет генерировать не только вероятные, но и инновационные действия, расширяя возможности исследования и повышая устойчивость к изменениям в окружающей среде.
Централизованный распределительный критик в OMAD оценивает полное распределение возвратов, а не только ожидаемое значение, как в традиционных функциях ценности. Это обеспечивает более детальную информацию об ожидаемых результатах действий, включая не только среднее значение, но и дисперсию и другие статистические характеристики. Оценка полного распределения позволяет агентам лучше понимать риски и возможности, связанные с каждым действием, что приводит к более эффективному обучению и улучшенной координации между агентами. В отличие от скалярных значений ценности, распределительный критик предоставляет информацию о вероятности различных возможных возвратов, позволяя агентам выбирать действия, максимизирующие не только ожидаемую награду, но и учитывающие неопределенность.
Интеграция обучения с максимальной энтропией (Maximum Entropy RL) в OMAD направлена на стимулирование исследования неопределенных состояний в многоагентной среде. Этот подход позволяет агентам не только максимизировать ожидаемую награду, но и увеличивать энтропию своей политики, что способствует более широкому охвату пространства состояний. Повышенное исследование снижает вероятность преждевременной сходимости к локальным оптимумам и улучшает координацию между агентами, поскольку каждый агент менее склонен к эксплуатации известных стратегий, а более склонен к поиску новых и потенциально более эффективных решений. Практически, это достигается путем добавления члена, пропорционального энтропии политики, к функции награды, побуждая агентов выбирать действия с более высокой неопределенностью.
Улучшение Стабильности Критика: Методы Нормализации и CrossQ
Для стабилизации централизованного распределенного критика, OMAD использует пакетную нормализацию (Batch Normalization). Данная техника нормализует активации в скрытых слоях критика, что уменьшает внутреннее ковариационное смещение и позволяет использовать более высокие скорости обучения. Это, в свою очередь, значительно ускоряет процесс обучения и улучшает сходимость алгоритма, особенно в сложных средах обучения с подкреплением, где нестабильность критика может препятствовать эффективному обучению агентов.
Критик в OMAD использует метод CrossQ для повышения точности оценки функций ценности. CrossQ сочетает в себе пакетную нормализацию (Batch Normalization) и остановку градиентов (stop gradients). Пакетная нормализация стабилизирует процесс обучения, а остановка градиентов предотвращает распространение нежелательных градиентов из критика в политику, что позволяет более эффективно оценивать функции ценности и ускоряет сходимость алгоритма. Данный подход позволяет добиться более точной оценки ценности состояний, что критически важно для обучения оптимальной политики в сложных многоагентных средах.
Комбинация применяемых техник, включая нормализацию пакетов (Batch Normalization) и метод CrossQ, в связке с диффузионной политикой, обеспечивает эффективную аппроксимацию оптимальной политики в сложных многоагентных средах. Использование диффузионной политики позволяет OMAD эффективно исследовать пространство действий и находить стратегии, оптимальные для всех агентов. Нормализация пакетов и CrossQ стабилизируют обучение централизованного критика, что критически важно для координации действий множества агентов и достижения стабильных результатов в сложных сценариях взаимодействия.
![Исследование абляции гиперпараметров распределенной Q-функции показало, что производительность агента чувствительна к верхнему пределу поддержки [latex]V_{max}[/latex] и зависит от разрешения дискретизации при изменении числа атомов.](https://arxiv.org/html/2602.18291v1/x4.png)
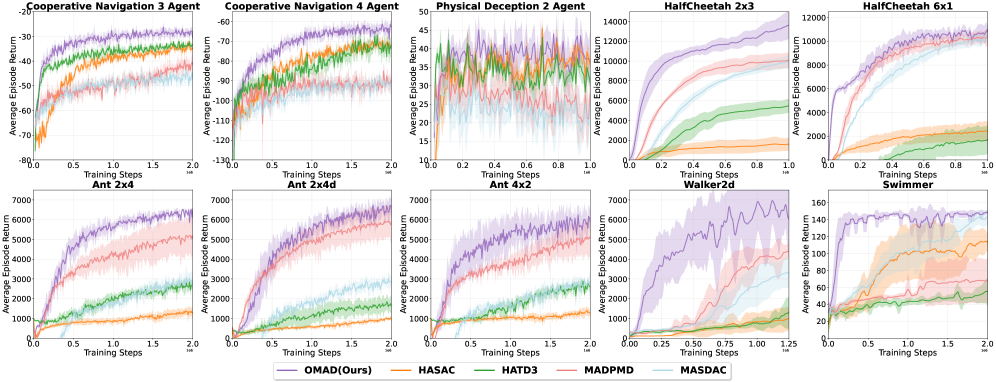
Эмпирическая Оценка и Производительность: Превосходящие Результаты в Бенчмарках
В рамках строгой оценки, разработанный алгоритм OMAD был протестирован на общепринятых бенчмарках для обучения с подкреплением в многоагентной среде, включая MPE и MAMuJoCo. Результаты демонстрируют, что OMAD достигает передового уровня производительности, превосходя существующие подходы в задачах, требующих сложной координации между агентами. Эти тесты подтверждают эффективность предложенной архитектуры и ее способность успешно решать широкий спектр задач в динамичных и конкурентных средах, устанавливая новые стандарты в области многоагентного обучения с подкреплением.
Предложенная схема обучения, OMAD, демонстрирует значительное превосходство над существующими алгоритмами, в частности, HASAC, обеспечивая улучшенную координацию агентов и более высокие суммарные награды. В ходе обширных экспериментов, включающих 1010 разнообразных сценариев, OMAD показал увеличение эффективности использования данных в 2.5 — 5 раз по сравнению с аналогами. Такой существенный прирост свидетельствует о потенциале подхода, основанного на диффузии, для решения сложных задач многоагентного обучения и координации, где эффективное использование ограниченных данных играет критическую роль.
В ходе экспериментов, алгоритм OMAD продемонстрировал выдающиеся результаты в задачах управления многоагентными системами. В частности, на задаче HalfCheetah, максимальное среднее вознаграждение за эпизод достигло отметки в 12499.8, а на задаче Ant — 7521.9. Эти показатели значительно превосходят результаты, полученные с использованием существующих алгоритмов, что подтверждает эффективность подхода, основанного на диффузионных моделях.
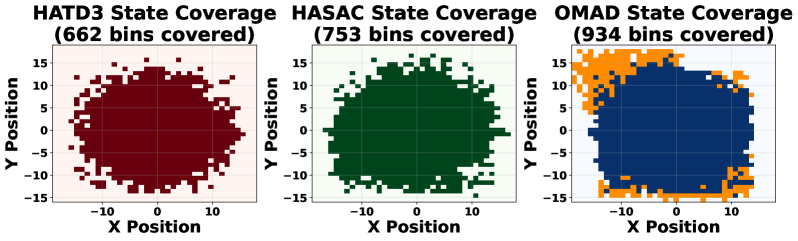
Перспективы Развития: К Масштабируемой и Адаптивной Координации
Дальнейшее развитие алгоритма OMAD требует пристального внимания к ситуациям, когда агенты обладают лишь частичным представлением об окружающей среде и когда состав популяции агентов постоянно меняется. Исследования в этом направлении направлены на создание систем, способных эффективно координировать действия в условиях неопределенности и изменчивости. Разработка методов, позволяющих агентам делать обоснованные выводы на основе неполной информации и адаптироваться к появлению или исчезновению других агентов, представляется ключевой задачей. Успешное решение этих проблем позволит значительно расширить область применения OMAD, сделав его пригодным для более сложных и реалистичных сценариев, где полная наблюдаемость и статичность популяции являются недостижимыми идеалами.
Дальнейшее развитие алгоритмов координации требует пристального внимания к усовершенствованию моделей диффузии и стратегий исследования. Исследования направлены на внедрение более сложных диффузионных моделей, способных эффективно передавать информацию между агентами даже в условиях неопределенности и частичной наблюдаемости. Параллельно изучаются продвинутые стратегии исследования, позволяющие агентам более эффективно исследовать пространство возможных решений и избегать застревания в локальных оптимумах. Оптимизация этих компонентов, включая β-параметров диффузии и функции вознаграждения для исследования, может значительно повысить общую производительность и адаптивность системы, позволяя агентам более эффективно координировать свои действия и достигать поставленных целей в сложных и динамичных средах.
Перспективы применения OMAD в реальных задачах, таких как робототехника и автономное вождение, открывают значительные возможности для координации множества агентов. Исследования в этой области позволяют представить сценарии, где роботы совместно выполняют сложные производственные задачи, а автономные транспортные средства эффективно взаимодействуют в условиях плотного городского трафика. В подобных системах OMAD может обеспечить децентрализованное и адаптивное принятие решений, позволяя агентам динамически приспосабливаться к изменяющейся обстановке и избегать столкновений или конфликтов. Успешная реализация OMAD в этих сферах не только повысит эффективность и надежность систем, но и позволит создать более безопасные и интуитивно понятные взаимодействия между машинами и человеком.

Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в алгоритмах обучения с подкреплением для многоагентных систем. OMAD, предложенный фреймворк, подчеркивает важность непротиворечивости и предсказуемости в координации агентов, что находит отклик в словах Карла Фридриха Гаусса: «Если бы я должен был выбрать один из вариантов, я бы выбрал тот, который наиболее элегантен». Элегантность, в данном контексте, проявляется в эффективном использовании централизованного критика для обучения и децентрализованного исполнения, позволяя агентам достигать state-of-the-art результатов в сложных координационных задачах. Данный подход, подобно математической аксиоме, стремится к доказательству корректности, а не просто к успешному прохождению тестов.
Куда двигаться дальше?
Без четкого определения метрик успешной координации, любое улучшение производительности представляется скорее шумом, чем прогрессом. Представленная работа, хотя и демонстрирует впечатляющие результаты, не решает фундаментальный вопрос: что на самом деле означает «координация» в контексте обучения с подкреплением для множества агентов? Ограничения текущих подходов в обобщении на принципиально новые сценарии остаются очевидными. Успех, измеренный на конкретных задачах, не гарантирует устойчивость алгоритма к минимальным изменениям в структуре взаимодействия агентов.
Ключевым направлением представляется разработка формальных методов верификации политик, позволяющих доказать корректность алгоритма координации, а не просто наблюдать ее на ограниченном наборе тестов. Необходимо уйти от эвристических подходов к построению критиков и перейти к строго обоснованным моделям, учитывающим не только текущее состояние, но и историю взаимодействия агентов. Вопрос о вычислительной сложности таких методов, безусловно, встает остро, но он является неотъемлемой частью любой научной задачи.
Дальнейшие исследования должны быть сосредоточены на разработке алгоритмов, способных к самообучению и адаптации к изменяющимся условиям. Необходимо найти способы преодолеть зависимость от централизованного обучения и перейти к полностью децентрализованным системам, способным функционировать в условиях ограниченной информации и непредсказуемости. И лишь тогда можно будет говорить о реальном прогрессе в области многоагентного обучения с подкреплением.
Оригинал статьи: https://arxiv.org/pdf/2602.18291.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Хэдхантер акции прогноз. Цена HEAD
- РУСАЛ акции прогноз. Цена RUAL
- Будущее лайткоина: прогноз цен на криптовалюту LTC
- Как два ETF играют в одни ворота, но с разными мячами
- Группа Аренадата акции прогноз. Цена DATA
- ДЭК акции прогноз. Цена DVEC
2026-02-23 20:33